小模型站起来了,浏览器里跑出SOTA,抱抱脸:快逃,合成数据不是未来
小模型也要训练数万亿tokens
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
浏览器里直接能跑的SOTA小模型来了,分别在2亿、5亿和20亿级别获胜,抱抱脸出品。
秘诀只有两个:
- 狠狠地过滤数据
- 在高度过滤的数据集上狠狠地训练
抱抱脸首席科学家Thomas Wolf,总结团队在开发小模型时的经验,抛出新观点,引起业界关注:
合成数据目前只在特定领域有用,网络是如此之大和多样化,真实数据的潜力还没完全发挥。
目前360M模型版本已发布Demo,在线可玩(注意流量)。

在浏览器里调用本地GPU运行,连模型权重带网页前端UI,400MB搞定。
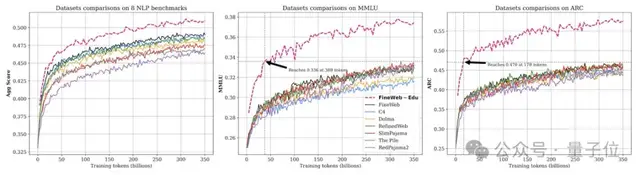
严格过滤网络数据,性能直线上升
针对微软Phi系列小模型,声称使用了一半合成数据,效果很好,但不公开数据。
开源界扛把子抱抱脸看不下去了:
造一个对标的大型合成数据集,开源它。
而且,团队隐隐暗示了,此举也有检验微软在测试集上刷榜的传闻,到底有没有这回事的考虑。

抱抱脸使用当时最好的开源模型Mixtral-8-7B构造了25B合成数据。
训练出来的模型效果还不错,但仍然在某种程度上低于Phi-1和Phi-1.5的水平。
他们尝试了让大模型在中学水平上解释各种主题,最终只有在MMLU测试上表现不好,因为MMLU是博士水平的题目。
真正的性能突破,反而来自一项支线任务:
除了用大模型从头生成合成数据,也试试用大模型筛选过滤网络数据。
具体来说是使用Llama3-70B-Struct 生成的标注开发了一个分类器,仅保留FineWeb数据集中最具教育意义的网页。
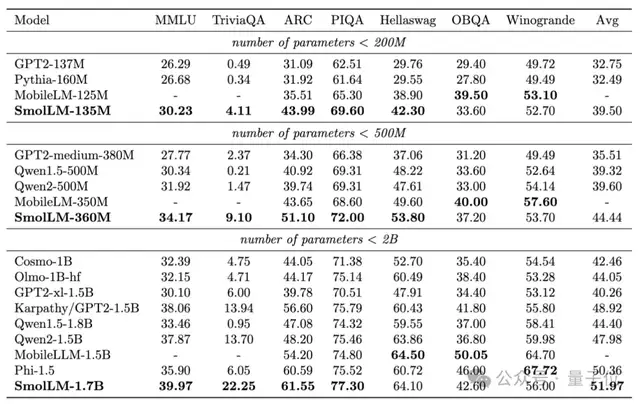
使用经过严格过滤的网络数据后,性能直线上升,并在大多数基准测试中超过了所有其他类似大小的模型,包括Phi-1.5。
抱抱脸团队称这项实验结果是“苦乐参半”的:虽然模型性能前所未有的高,但也显示出了合成数据还是比不过真实数据。
后来他们用同样的思路从自然语言扩展到代码,过滤的代码数据集也被证明是非常强大的。
将HumanEval基准测试成绩从13%左右直接提高到20%以上。
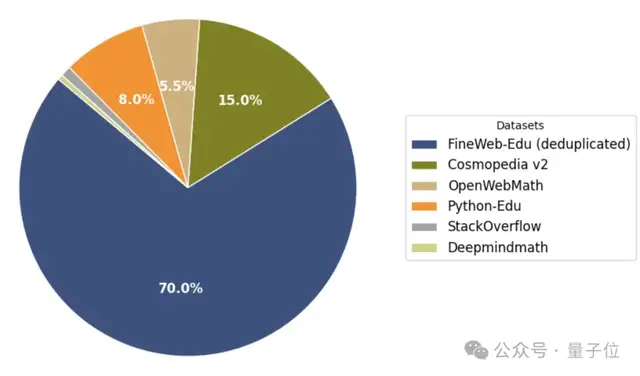
最终他们构造的混合数据集中,去重的过滤数据集占绝大部分,纯合成数据Cosmopedia v2只占15%。
所以总得来说,合成数据还有用吗?
团队认为,可能只对确实缺少真实数据的领域更有意义了,比如推理和数学。

即使小模型也要训练数万亿tokens
就在他们对这些新发现和结果感到兴奋时,一位新实习生Elie Bakouch加入了。
虽然他当时只是实习生,但确是一位精通各类训练技巧的专家。
在Elie的帮助下,团队将模型尺寸从1.7B开始下降到360M甚至170M,也就是对标经典模型GPT-1、GPT-2和BERT。
在这个过程中有了第二个重要发现:与过去的共识不同,即使是小模型也要在数万亿token上训练,时间越长越好。
此外数据退火(Anneal the data)也被证明是有效的,也就是在训练的最后一部分保留一组特殊的高质量数据。
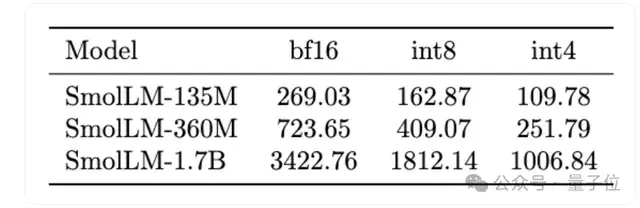
最终发布的系列模型适合部署在从智能手机到笔记本电脑的各种设备上,最大的1.7B模型BF16精度只占3G内存。
作为参考,iPhone 15入门版也有6G,安卓手机就更多了。
虽然这次训练出来的基础模型足够好,但团队也还是发现一个问题。
过去的对齐和微调技术,如SFT、DPO、PPO等都是针对大模型非常有效,但对小模型效果并不理想。
团队分析,对齐数据集中包含许多对小模型来说过于复杂的概念,并且缺乏精心设计的简单任务。
下一个新坑也挖好了,有兴趣的团队可以开始搞起,没准就成了小模型大救星。
在线试玩:
https://huggingface.co/spaces/HuggingFaceTB/instant-smollm
参考链接:
[1]https://huggingface.co/blog/smollm
[2]https://x.com/Thom_Wolf/status/1825094850686906857
- Qwen上新AI前端工程师!一句话搞定HTML/CSS/JS,新手秒变React大神2025-05-10
- DeepSeek新数学模型刷爆记录!7B小模型自主发现671B模型不会的新技能2025-05-01
- 自动化所:基于科学基础大模型的智能科研平台ScienceOne正式发布2025-04-30
- 小扎回应Llama4对比DeepSeek:榜单有缺陷,等推理模型出来再比2025-04-30