大模型指令调优数据集万字评测!腾讯上交大联合出品
覆盖文献400余篇
腾讯优图实验室 投稿
量子位 | 公众号 QbitAI
随着大模型的快速发展,指令调优在提升模型性能和泛化能力方面发挥着至关重要的作用。
然而,对于指令调优数据集的数据评估和选择方法尚未形成统一的体系,且缺乏全面深入的综述。
为了填补这一空白,腾讯优图实验室发布一篇完整综述进行梳理。
长度超过了万字,涉及的文献多达400余篇。

这项研究涵盖了质量、多样性和重要性三个主要方面的数据评估和选择方法,对每个方面都进行了详细的分类和阐述。
同时,作者还关注了该领域的最新进展和趋势,包括一些新兴的技术和方法,如利用GPT等强大语言模型进行数据评分、基于双层优化的Coreset采样等。
全方位评估指令调优数据集
LLMs的发展目标是解锁对自然语言处理(NLP)任务的泛化能力,指令调优在其中发挥重要作用,而数据质量对指令调优效果至关重要。
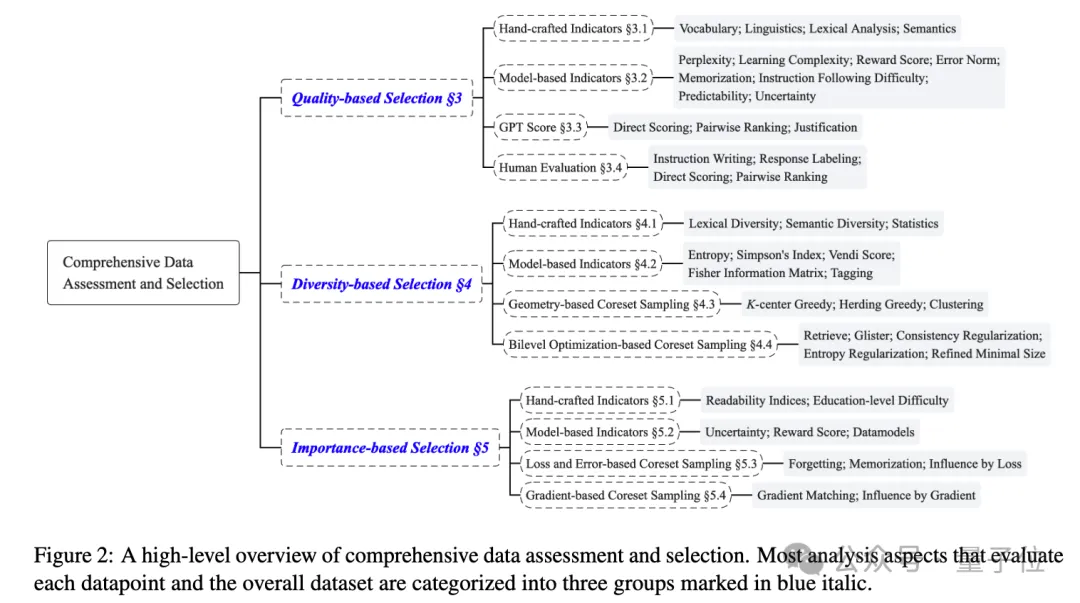
作者深入研究了各种指令调优数据集的数据评估和选择方法,从质量、多样性和重要性三个方面进行了分类和阐述。
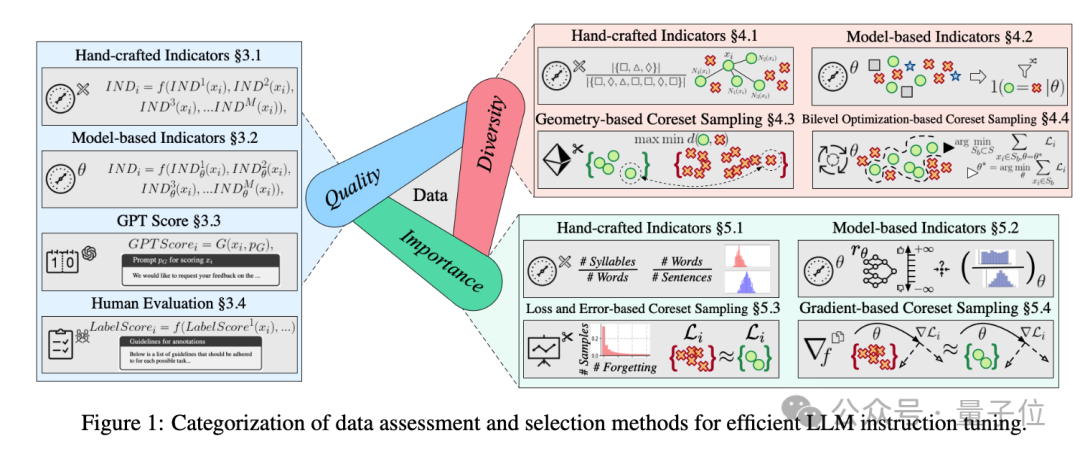
质量评估与选择
“质量”主要指指令响应数据点的完整性、准确性和合理性,现有方法通常制定统一的评分机制来综合考虑这些维度。
针对数据集的质量,作者主要总结出了四种测试方法:
- 一是手工设计指标,如通过词汇、句法、语义相似性等来方法评估数据质量,优点是指标计算明确,但无法检测不匹配的指令响应对。
- 二是使用基于模型的指标,这种方法利用可训练模型(如使用困惑度、多维评分评估器等)进行,结合多种训练感知指标(如不确定性、奖励分数等)的混合技术,这种方法在选择无偏高质量样本方面具有潜力。
- 第三种方法是直接交给GPT,调用OpenAI APIs对指令调优数据集进行自动评分,这种方法与人类偏好高度对齐,收集少量GPT评分样本后微调开源LLM进行质量测量,可提高成本效率。
- 最后是人工评价,这种方法在构建偏好对齐数据集时不可或缺,可用为模型训练提供高质量数据,但存在标注不一致问题,需制定详细指南,并辅以GPT评分等其他措施作为补充。
多样性评估与选择
这里的多样性,是指指令数据集的个体多样性(如词汇和语义丰富度)和整体多样性(如数据分布),选择具有多样性的数据集可增强模型的泛化能力。
作者同样是总结了四种测试数据集多样性的方式。
- 手工设计的指标:包括词汇多样性(如Type-token ratio、vocd-D、MTLD、HD-D等)和语义多样性(如通过k – NN图计算距离、利用BERT嵌入计算方差等)等多种指标。
- 基于模型的指标:通过熵相关方法(如vanilla entropy、Rényi entropy、Simpson’s Index、Vendi Score等)、Task2Vec嵌入、开放标签的多样性标记等方式评估多样性。
- 基于几何特征的Coreset采样:通过k-center greedy、herding等方法选择最具信息和多样性的子集,代表整个数据集,使模型在子集上的训练性能接近在整个数据集上的训练性能,聚类技术在其中起到解释数据结构的作用。
- 基于Bi-level的Coreset采样:将Coreset采样视为Bi-level优化问题,通过优化硬掩码或软权重来选择子集,涉及到模型内部参数的优化和数据选择的外部循环,一些方法通过引入验证集、梯度匹配和优化技术等来提高鲁棒性和效率。
重要性评估与选择
重要性是指样本对模型训练的必要性,与模型任务相关,同时也关乎性能。易样本可能不需要额外调优,而难样本对模型训练至关重要。
对重要性的评估,主要有这样几种指标和方法:
- 手工设计的指标:通过可读性指标(如语法、词汇、推理依赖等)评估文本难度,选择具有挑战性的样本以评估模型鲁棒性和构建有区分度的NLP基准。
- 基于模型的指标:包括不确定性(如prompt uncertainty)、奖励分数(通过奖励模型判断样本对模型行为的必要性)和数据模型(如通过Data model预测数据点对模型行为的影响、DSIR根据分布相似性估计重要性分数、MATES连续选择最有效子集、Xie等人通过重要性重采样选择类似目标分布的样本)等方式。
- 基于Loss和Error的Coreset采样:通过记录训练中样本的错误(如forgetting score、memorization、influence等)来估计重要性,选择对损失贡献大或导致性能差的样本,一些研究通过迭代近似和小代理模型加速计算边际效应。
- 基于梯度的Coreset采样:利用梯度直接影响语言模型优化的特性,通过梯度匹配(如逼近整个数据集的梯度)和梯度基于的影响(如通过上加权梯度乘法测量样本对模型参数的影响)来选择数据,一些技术(如低秩梯度相似性搜索、移动样本近似等)用于加速计算和提高效率,同时需要考虑近似的精度和效率。
现有挑战和未来方向
作者发现,数据选择的有效性与模型在基准测试上的性能报告之间存在差距,原因包括评估损失与基准性能相关性不强、测试集污染等。
未来需要构建专门的基准来评估指令调优模型和所选数据点,并解耦数据选择和模型评估以排除数据污染的影响。
目前也没有统一标准来区分“好”“坏”指令,现有质量测量方法具有特定任务导向性且缺乏解释性,未来需要更统一、通用的定义和提高选择管道的可解释性,以适应不同下游任务的需求。
随着数据集的扩大,确定最佳选择比例也变得困难,原因包括噪声增加、过拟合和遗忘问题,建议通过质量测量方案、强调多样性和考虑与预训练数据的相似性来确定最佳选择比例,并优化数据评估和选择的可扩展性pipeline。
除了数据集,大模型本身的规模也在增大,数据评估和选择的成本效率降低,需要发展高效的代理模型,同时重新思考传统机器学习技术,如优化技巧和降维方法。
项目主页:
https://github.com/yuleiqin/fantastic-data-engineering
论文地址:
https://arxiv.org/abs/2408.02085
- 数据中心不必建在地球!中国企业已经把算力设施送到了太空2025-05-14
- Qwen3家族训练秘籍公开:思考/非思考融进一个模型,大模型蒸馏带动小模型2025-05-14
- 字节Seed首次开源代码模型,拿下同规模多个SOTA,提出用小模型管理数据范式2025-05-11
- AI开源社区来了国家队!华为百度第一时间加入2025-05-09