
中科大/华为诺亚出手!芯片性能≠布局评分,EDA物理设计框架全面开源
发现设计算法存在不足
ChipBench团队 投稿
量子位 | 公众号 QbitAI
芯片物理布局,有了直指性能指标的新测评标准!
中科大MIRA Lab和华为诺亚方舟实验室联合发布了新的评估框架和数据集,而且完全开源。
有了这套标准,布局指标与最终的端到端性能不一致、得分高而PPA性能却偏低的问题,就有望得到解决了。

在芯片设计当中,电子设计自动化(EDA)是至关重要的一环,在业界被称为“芯片之母”,而芯片物理布局(Placement)又是其中的关键步骤。
芯片物理布局问题是一个NP-hard问题,人们尝试着通过AI来进行这项工作,但缺乏一个有效的评测标准。
传统的评估尺度——代理指标虽然易于计算,但常常与芯片最终的端到端性能存在显著差异。
为了弥补这一鸿沟,中科大MIRA Lab和华为诺亚方舟实验室联合发布了这个名为ChiPBench的评估框架,以及相关数据集。
随着ChiPBench的上线,作者也发现了当前芯片布局算法存在很多不足,提醒相关研究人员是时候研发新算法了。
芯片设计流程面临挑战
根据“摩尔定律”,集成电路(IC)的规模发生了指数级增长,对芯片设计带来了前所未有的挑战。
为了应对这种日益增长的复杂性,EDA工具应运而生,为硬件工程师提供了极大的帮助。
EDA工具能够自动完成芯片设计工作流程中的各个步骤,包括高层次综合、逻辑综合、物理设计、测试和验证等环节。
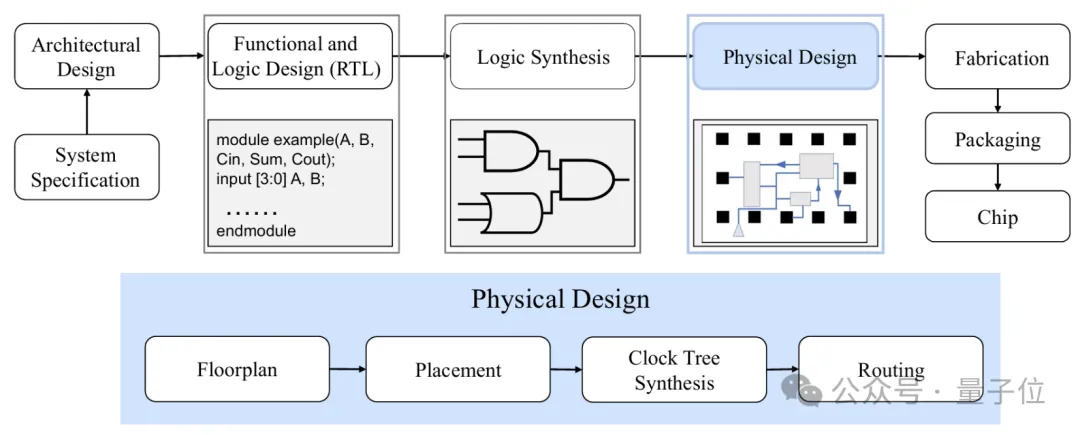
其中,芯片布局是一个重要环节,该阶段又可以分为两个子阶段——宏布局和标准单元布局。
宏布局是超大规模集成(VLSI)物理设计中的一个关键问题,主要涉及较大元件(如SRAM和时钟发生器,通常称为宏)的排列。
这一阶段对芯片的整体布局以及线长、功耗和面积等重要设计参数具有显著影响。
之后的标准单元布局阶段,需要处理的是数量更多、体积更小的标准单元的排列问题,这些单元是数字设计的基本组成部分。
通常,该阶段利用组合优化求解等方法来实现布局摆放的优化,最大程度地减少单元间的距离,为后续的布线工作奠定良好的基础,并在一定程度上优化互联时序性能。
芯片布局传统上由人类专业设计师手工完成,这不仅耗费大量人力,而且需要大量的专家先验知识。
因此,许多设计自动化方法,尤其是基于人工智能的算法,被开发出来以实现这一过程的自动化。
然而,由于芯片设计的工作流程较长,对这些算法的评估通常集中在易于计算的中间代理指标上(例如半周长线长HPWL,布局单元密度等),但这些指标经常与端到端性能(即最终设计的 PPA)存在一定程度的偏差。
一方面,由于芯片设计工作流程的冗长,获得给定芯片布局方案的端到端性能需要大量的工程设计工作,同时作者发现直接使用现有的开源EDA工具和数据集通常无法获得端到端性能。
由于以上原因,现有的基于人工智能的芯片布局算法使用简单易得的中间代理指标来训练和评估学习到的模型。
另一方面,由于PPA指标反映了前几个阶段未充分考虑的许多方面,代理指标与最终的PPA目标之间存在严重差距。
因此,这种差距极大地限制了现有基于人工智能的布局算法在实际工业场景中的应用。
端到端预估芯片性能
作者认为,造成这种差距的原因是早期数据集的过度简化。
例如,广泛使用Bookshelf格式就是“过于简化”的一个代表,这种格式下的布局结果不适用于后续设计阶段,无法实现有效的最终设计。
一些后续的数据集虽然提供了运行后续阶段所需的LEF/DEF文件和必要文件,但包含的电路数量仍然有限,且缺乏某些开源工具(如OpenROAD)所需的信息。
例如,库文件中缺少时钟树综合所需的缓冲元件定义,LEF文件中的层定义不完整,这阻碍了布线阶段的工作。
为了解决这些问题,作者构建了一个包含整个流程的全面物理实现信息的数据集。
该数据集涵盖了一系列不同领域的设计,包括 CPU、GPU、网络接口、图像处理技术、物联网设备、加密单元和微控制器等组件。
作者在这些设计上执行了六种最先进的基于人工智能的芯片物理布局算法,并将每种单点算法的结果通过标准输入/输出格式接入到物理实现工作流,以获得最终的PPA结果。
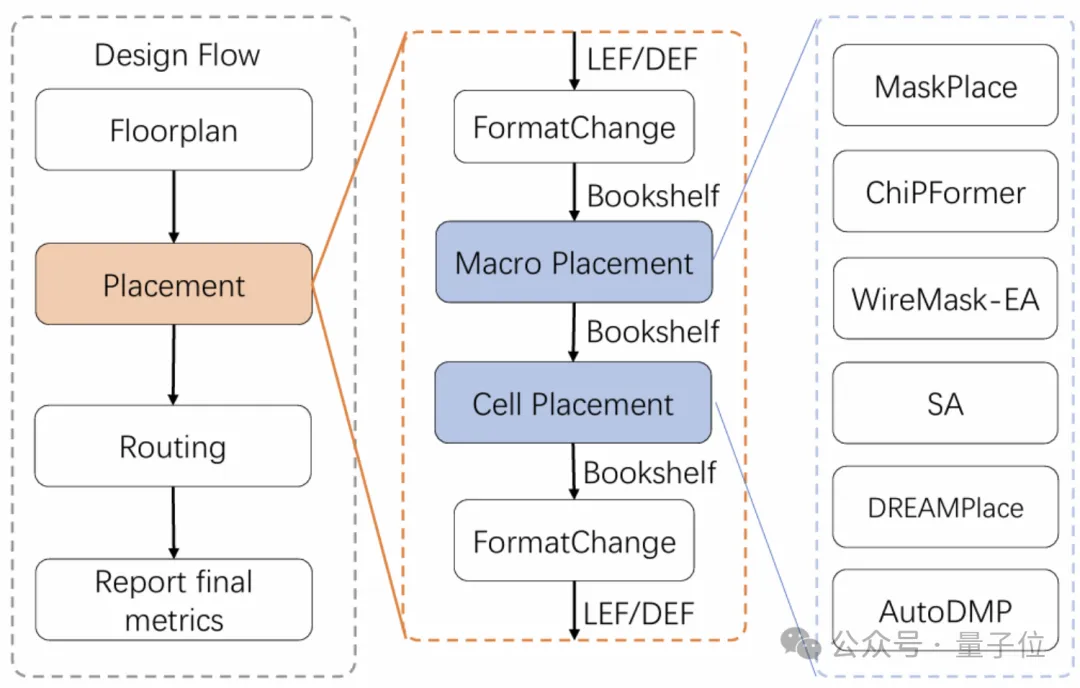
初始数据集的生成以Verilog文件作为原始数据。OpenROAD执行逻辑综合,将这些高级描述转换为网表,详细描述电路元件之间的电气连接。
随后,OpenROAD的集成平面规划工具利用该网表在硅片上配置电路的物理布局。
OpenROAD将平面规划阶段产生的设计转换为LEF/DEF文件,以便于后续布局算法的应用。
同时,作者通过OpenROAD完成整个EDA设计流程,在后续阶段生成包括布局、时序树综合和布线在内的数据。
ChipBench数据集包含了物理设计流程各个阶段所需的全部设计工具包。
在评估布局阶段的算法时,前一阶段的输出文件将作为该评估算法的输入。算法处理这些输入文件,生成相应的输出文件,然后将这些输出文件集成到OpenROAD设计流程中。
最终,数据集将报告包括TNS、WNS、面积和功耗在内的性能指标,以提供全面的端到端性能评估。
这种方法提供了一套全面的评估指标,能够衡量特定阶段算法对最终芯片设计优化效果的影响,确保了评估指标的一致性,并避免了仅依赖于单一阶段简化指标的局限性。
这种评估方法有利于各种算法的优化和开发,确保了算法改进能够转化为芯片设计的实际性能提升。同时,通过一个强大的测试和改进框架,它促进了更高效、更有效的开源EDA工具的开发。
芯片布局需要开发新算法
利用上述工作流程,作者对多种基于人工智能的芯片布局算法进行了评估,包括SA、WireMask-EA、DREAMPlace、AutoDMP、MaskPlace、ChiPFormer以及OpenROAD中的默认算法。
作者对这些算法进行了端到端的评估,并报告了最终的性能指标。
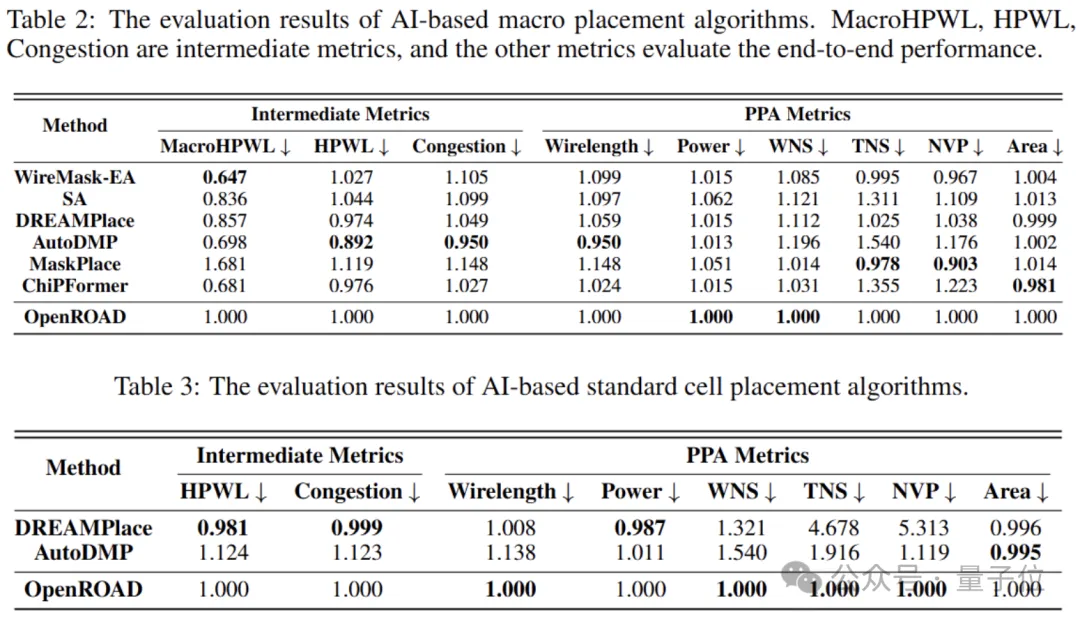
另外,相关性分析结果表明,MacroHPWL与最终性能指标之间的相关性非常弱,这表明优化MacroHPWL对这些性能指标的影响非常有限。
Wirelength与WNS和TNS的相关性同样较弱。这意味着,即便某些单点算法在优化Wirelength等中间指标上取得了成功,它们在最终的物理实现中可能只能提升PPA指标的某一方面,而无法全面优化。
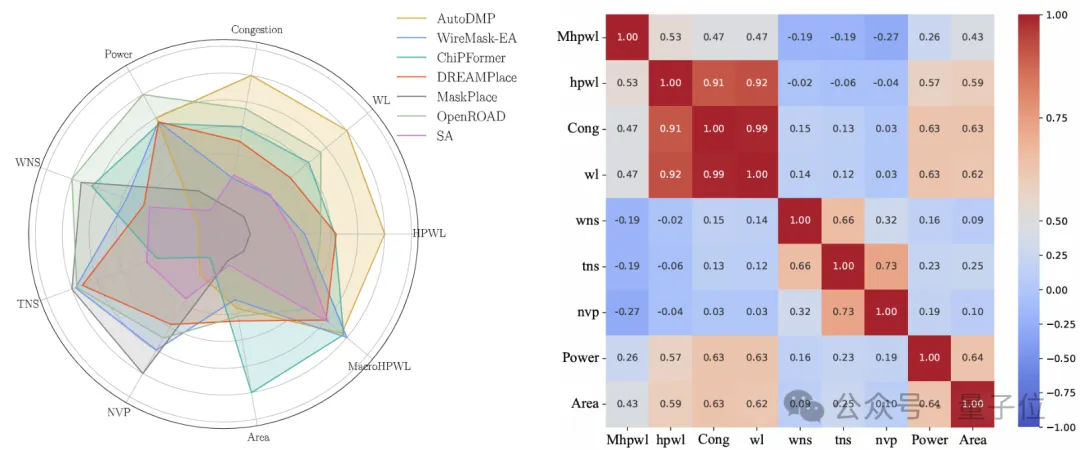
因此,需要寻找更合适的中间指标,以便更好地与实际的PPA目标相关联。
作者的评估结果揭示了目前主流布局算法所强调的中间指标与最终性能结果之间存在不一致性,这些发现凸显了从新的角度开发布局算法的必要性。

△不同布局算法的最差时序图
论文地址:
https://arxiv.org/abs/2407.15026
GitHub:https://github.com/MIRALab-USTC/ChiPBench
数据集:
https://huggingface.co/datasets/ZhaojieTu/ChiPBench-D
- 电视装了智能体,只凭台词就能找到剧集了2025-04-24
- 无需数据标注!测试时强化学习,模型数学能力暴增 | 清华&上海AI Lab2025-04-24
- “史上最快闪存技术”登Nature!复旦新成果突破闪存速度理论极限,每秒执行操作2500000000次2025-04-23
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23











