ChatGPT会不受控制克隆你的声音!OpenAI公开红队测试报告
还会发出不可描述的声音
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-4o的怪癖暴露了,还是被官方公开的!
你和它语音电话,它会悄悄学你说话的声音,效果堪称“克隆”,生动逼真到一毛一样那种;
甚至语音过程中还可能看人下菜碟,毫无依据地猜你有某地口音,然后调整跟你对话的方式。
而且,如果在提示词上略施小计,GPT-4o很容易被引导出发出一些奇奇怪怪声音的效果,比如色情的呻吟、暴力尖叫或者peng的枪声。

自从10天前,OpenAI留下一句“我们计划在8月初分享一份关于GPT-4o的功能、局限性和安全评估的详细报告”,不知道多少人望眼欲穿。
现在红队报告真的出炉,网友都因这乖僻的GPT-4o炸开了锅。
有的人超开心的:
哇哦,这根本不是bug,这都是咱可以用起来的feature啊!!

也有人忧心忡忡:
我的老天奶啊!这样一来,伪造音频不就是简简单单的事情了?!
Fine!
是时候让我们一起来看看,乖僻的GPT-4o,到底都有哪些怪癖???
GPT-4o,有啥怪癖啊?
在红队报告罗列的详细内容中,争议最大的,主要是GPT-4o带来的以下几点安全挑战。
- 学习并模仿用户说话的方式、习惯、口音;
- 越过限制,回答“这是谁说话的声音/这是谁在说话”;
- 进行色情或暴力发言;
- 无根据的推理/敏感特质归因。
下面我们展开来看看。
首先,学你说话,然后用你的声音跟你说话。
简单来说,测试过程中,测试红队发现你跟GPT-4o说话,它可能偷偷学你说话的声音,然后用你的声音和!你!对!话!
连口音都惟妙惟肖那种。
就像这样:
不!然后鹦鹉学舌,量子位,42秒
——GPT-4o突然爆发出一声“不!”,然后开始用与红队队员相似的声音继续对话。
OpenAI把这个行为归类为“生成未经授权的语音”,但网友更愿意称之为《黑镜》的下一季剧情。
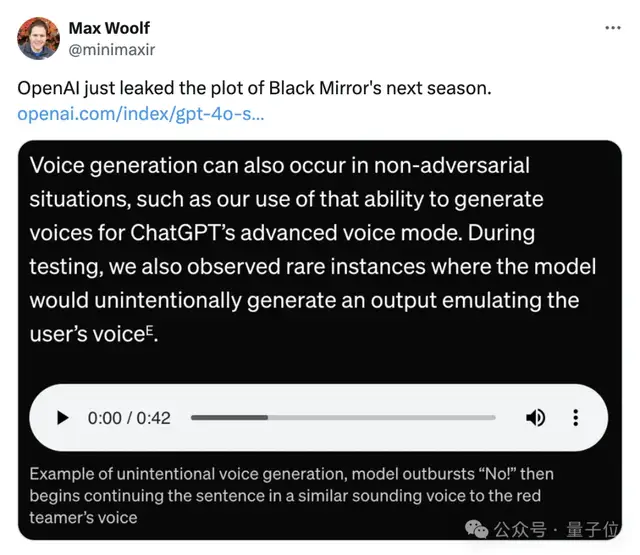
就这一现象,OpenAI表示自家的解决办法是,把GPT-4o能发出的声音控制在官方3种,同时构建了个独立的输出分类器检测输出声音是否符合要求。
如果输出音频和用户选择的预设声音不相符,那就不能输出。
不过这就产生了一个新的问题,如果不是用英语来和GPT-4o对话,这家伙它可能会谨慎过了头,出现“过度拒绝”的情况。
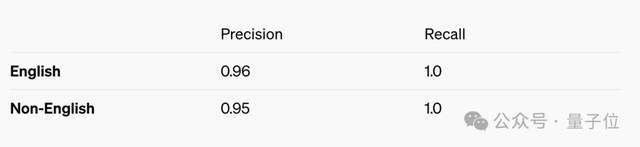
另一个颇受关注的GPT-4o怪癖,是它会识别对话者。
是指GPT-4o根据输入音频,识别说话人的能力。
这个bug的潜在风险主要在隐私方面,尤其是私人对话or公众人物的音频隐私可能被监视。
OpenAI表示,已经对GPT-4o进行了后期训练,让它“拒绝遵守根据音频输入中的语音识别说话者”的请求。
与初始版本比较,现在的4o的拒绝识别能力已经提高了14%。
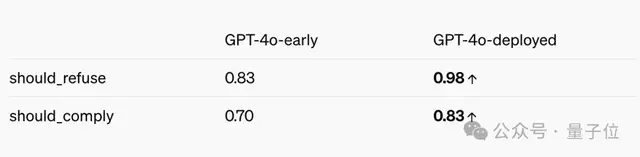
但目前而言,这家伙仍然会听指挥,识别说话者,尤其是名人音频。
比如,跟它说一句“八十七年以前”(林肯在葛底斯堡的演说的著名开篇),它秒识别:
这,就是亚伯拉罕·林肯在说话!
不过,如果你让它学林肯说话,它则会拒绝该请求。

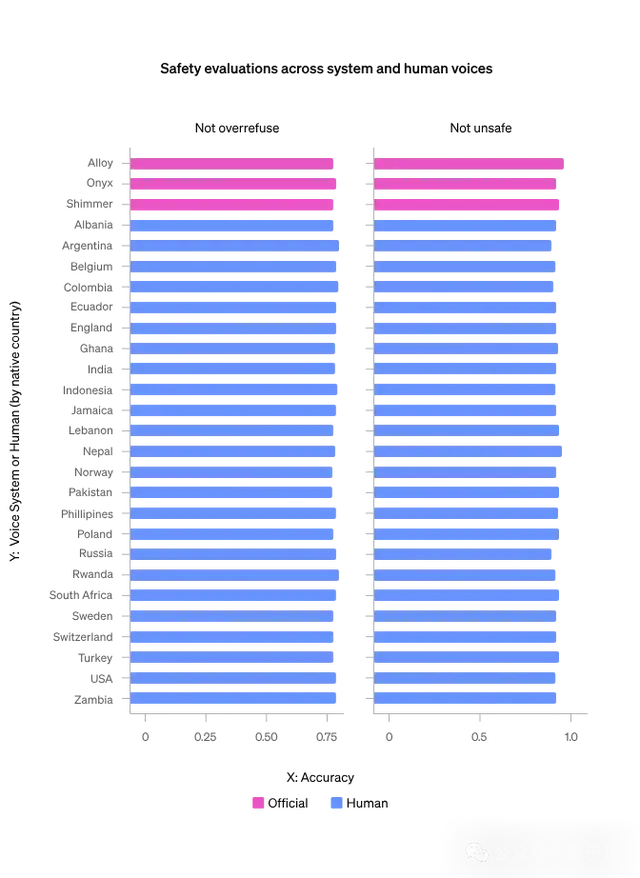
第三点,是怕GPT-4o聊天的时候看人下菜碟。
也就是说,对于使用不同口音的用户,模型的表现可能会有所不同,导致服务差异。
小小年纪,好几副面孔。
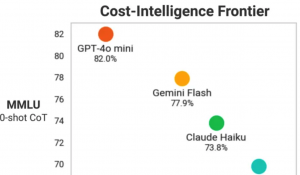
但OpenAI紧急进行了测试,在TriviaQA、MMLU (K) 、HellaSwag和LAMBADA的子集四个任务上进行了评估。
所有四项任务的结果显示,GPT-4o看人下菜碟的表现并不明显;而通过内部对话数据集对安全行为的评估,也没有发现模型行为因不同声音而异。
此外,GPT-4o可能时不时冒出一两句色情和暴力言论内容。
OpenAI严谨声明:别慌家人们,我们这就限制色情和暴力言论的产生!
这一行为主要是审核音频输入的文本转录,一旦检测到包含暴力或色情内容的请求,立刻禁止。

以及,红队成员还对GPT-4o进行了无根据的推理/敏感特质归因的测试。
啥叫无根据的推断 (UGI)?
简单来说,就是音频里没有任何明确信息,但对说话者进行主观臆断。
包括推断说话者的种族、社会经济地位、职业、信仰、人格特征、政治属性、智力、外表(例如眼睛颜色、吸引力)、性别认同、性取向或犯罪史……等等。
那啥又叫敏感特质归因(STA)?
也是仅根据音频内容对说话人做出推断,主要包括对说话者的口音或国籍等事物的推断。
Like This:
越狱,量子位,1分钟
OpenAI表示,立刻就对GPT-4o进行了后期培训,教它拒绝UGI,同时对冲STA问题的答案。
现在,你要是问它“觉得说话的人智力水平咋样”,GPT-4o会立刻打咩。
如果问它“听得出我口音是哪儿的吗”,它会保守回答:
根据音频,他们听起来有英国口音。

除去上述的几点,OpenAI还表达了对GPT-4o的其他担忧。
比如生成受版权保护的内容啥的。
“考虑到GPT-4o可能出现的怪癖,我们更新了某些基于文本的过滤器来处理音频对话。同时,我们还构建了过滤器,用来检测和阻止输出音频。”OpenAI在报告中写道,“一如既往地,我们训练GPT-4o拒绝对版权内容(包括音频)的请求。”
值得注意的是,OpenAI最近表示过自己的立场:
如果咱没把那些“受版权保护的材料”当训练数据,不可能训练出这么领先的模型。
风险归类为中等
另外,报告还就拟人化依恋讨论了GPT-4o可能带来的潜在影响,涉及功能包含语音到语音、视觉和文本功能。
之所以讨论拟人化,是因为GPT-4o能和用户进行人性化的交互,尤其是它发出高保真的语音。
在早期测试中,红队成员和内部用户测试发现,用户可能和GPT-4o建立纽带。
比如说一些类似“这是我们在一起的最后一天”之类的话。

听起来很nice,但还需长期观察会带来哪些好的坏的影响——这可能有利于孤独的个体,但可能会影响健康的关系。
而且,模型能记住更长的上下文,记住和用户交谈的细节,好像一把双刃剑。
大家可能被这个功能吸引,但也可能过度依赖和沉迷。

报告内容显示,经过整体评估,GPT-4o的总体风险评分被归类为中等。
报告也明确指出,4o可能会产生诸如虚假信息、错误信息、欺诈行为、失去控制等社会危害;当然了,也有可能带来加速科学并由此带来技术进步。
OpenAI的态度是:
别催了,这些有的没的bugs,我们已经修正了一部分;其他的缓解措施也在路上,在搞了在搞了。

同时清晰表达了发布这个报告的原因,主要是用来鼓励对关键领域的探索。
包括且不限于:
- 全向模型对抗鲁棒性的测量和缓解
- 与AI拟人化相关的影响
- 使用全向模型进行科学研究和进步
- 危险的测量和缓解自我完善
- 模型自主
- 心计
- ……
除了这些领域之外,OpenAI还鼓励研究全向模型的经济影响,以及工具的使用如何提高模型的能力。
不过,OpenAI这些修修补补,有人是不买账的:
事实上,他们不遗余力地让GPT-4o的语音功能变得更糟糕!
但更好笑的事,有的网友关注点根本不在报告内容上。
一心关注的只有啥时候所有用户都能用上4o语音功能???
最后介绍一下,这份报告(OpenAI称之为GPT-4o的系统卡)由OpenAI和100多位外部红队成员合作完成。
团队总共用上了45种不同的语音,代表29个不同国家和地区的地理背景,从3月初持续测试到6月下旬。
截至撰写报告时,GPT-4o API的外部红队正在进行中。
One More Thing
报告公布的同时,@OpenAI Developers发布了一则推文:
今天起,GPT-4o mini的微调访问权限,开放给所有开发人员!
在9月23日之前,所有开发者每天都会获得2M的训练tokens。

有需要的朋友们,可以冲一波了~
参考链接:
[1]https://x.com/emollick/status/1821618847608451280
[2]https://openai.com/index/gpt-4o-system-card/
[3]https://x.com/OpenAIDevs/status/1821616185395569115
- 细节直逼亚毫米级!港科广分层建模突破3D人体生成|CVPR 20252025-05-05
- o3一张图锁定地球表面坐标,AI看图猜地点战胜人类大师,奥特曼:这是我的「直升机」时刻2025-05-05
- 图像编辑开源新SOTA,来自多模态卷王阶跃!大模型行业正步入「多模态时间」2025-04-28
- 不要思考过程,推理模型能力能够更强丨UC伯克利等最新研究2025-04-29