想跑千亿大模型?算力厂商放大招!CPU通用服务器成为新选择
不用AI加速卡,只用4颗CPU
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
千亿参数规模的大模型推理,服务器仅用4颗CPU就能实现!
在一台CPU通用服务器上,浪潮信息成功跑通了102B大模型推理。
如果推广开来,没有专用芯片的传统行业,不必更换硬件,也能用上AI了。

△浪潮信息通用服务器NF8260G7成功运行千亿参数大模型
这套方案以极低的延时,近乎实时地进行推理运算。
如此之大的模型,只靠CPU运行,究竟是怎么实现的?
4颗CPU带动千亿大模型?
用CPU在单台通用服务器设备中运行大模型推理,特别是千亿参数的庞然大物,困难是可想而知的。
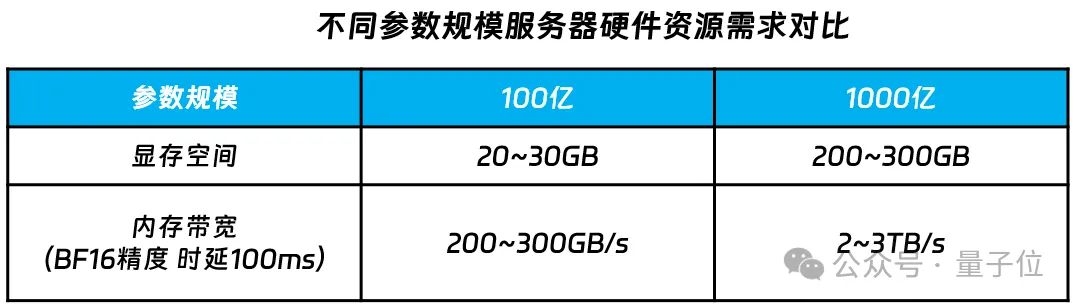
要想高效运行千亿参数大模型,计算、内存、通信等硬件资源的需求量都非常巨大。
内存方面,千亿参数大约需要200~300GB的显存空间才放得下。
除了内存资源,千亿参数大模型在运行过程中,对数据计算、计算单元之间及计算单元与内存之间通信的带宽要求也非常高。
按照BF16的精度计算,要想使千亿参数大模型的运行时延小于100ms,内存与计算单元之间的通信带宽至少要在每秒2TB以上。
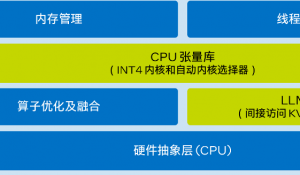
就算解决了这些硬件需求,软件的优化适配同样是一个难题。
由于涉及到大量的并行运算,现有的大模型普遍针对GPU加速集群而设计,这就导致了CPU算力与大模型之间的匹配程度远不及GPU。
因为并行工作环境的缺乏,AI模型需要频繁地在内存和CPU之间搬运算法权重,但通用服务器默认模型权重只能传输给一个CPU的内存。
要想进一步搬运到其他CPU,就需要该CPU作为中介,这就导致了CPU与内存之间的带宽利用率较低,进一步加大了通信开销。
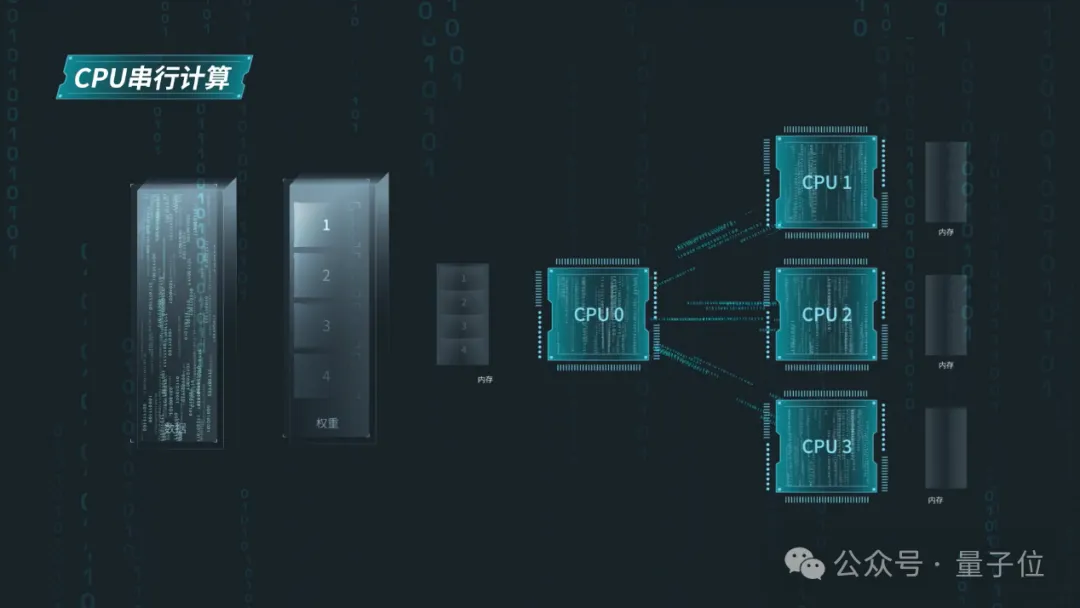
通用AI算力的新标杆
尽管困难重重,但伴随着大量的技术攻关,这些困难也被相继克服——
在2U四路的NF8260G7服务器上,浪潮信息成功运行了千亿参数的源2.0大模型。
运行过程中,服务器仅使用了4颗英特尔6448H芯片,无需GPU或其他任何额外的AI加速卡。
可以说,浪潮信息这套通用服务器大模型运行方案填补了业界空白,成为了通用AI算力的新标杆。
框架和算法方面,该方案支持PyTorch、TensorFlow等主流AI框架和DeepSpeed等流行开发工具,满足多样的生态需求。
在这种高效的千亿大模型通用服务器运行方案背后,无疑需要软硬件系统的协同创新。
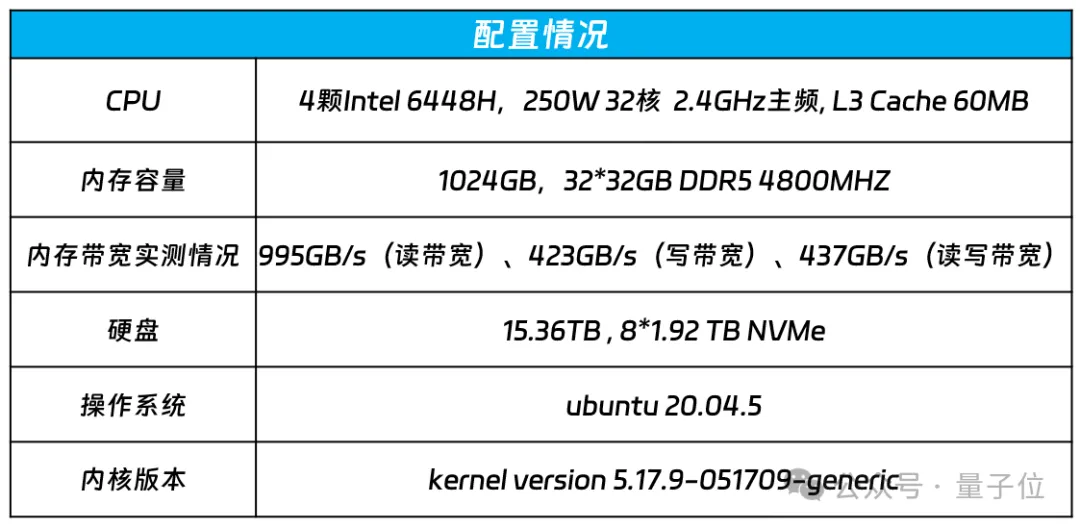
在配置方面,浪潮信息NF8260G7选用了英特尔至强6448H处理器,共有32颗核心,主频为2.4GHz,L3缓存为60MB,基于32根32G的DDR5内存,内存容量1024GB,实测内存读带宽995GB/s。
更重要的是,该芯片具有AMX(高级矩阵扩展,类似于GPU的Tensor core)AI加速功能,能够更好地适配大模型的运算特点。
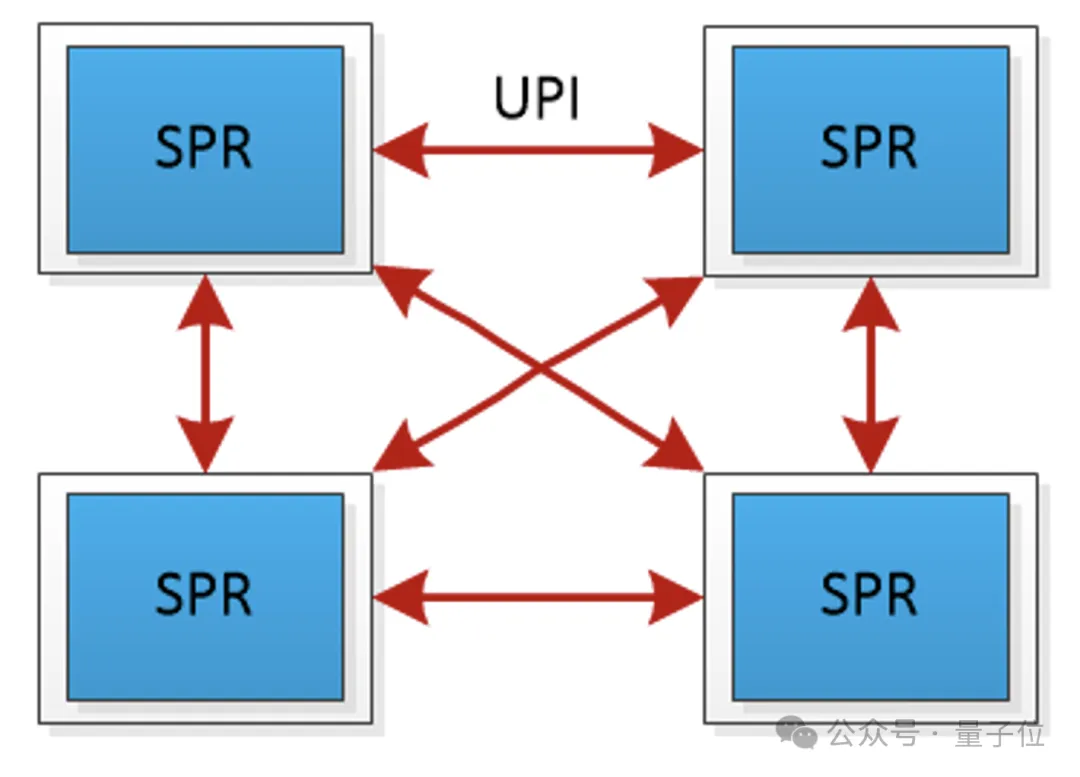
同时,为了解决带宽利用率低的问题,采用了“去中心化”的全链路UPI总线互连,允许任意两个CPU之间直接进行数据传输。
这样的互联方案减少了通信延迟,并将传输速率提高到了16GT/s(Giga Transfers per second)。
但仅靠硬件优化还远远不够。
为了提升源2.0-102B模型在NF8260G7服务器上的推理计算效率,服务器上的CPU需要像GPU一样进行张量并行计算。
为此,浪潮信息研发工程师将源2.0模型中的注意力层和前馈层的矩阵计算分别拆分到多个处理器,实现同时使用4颗CPU进行计算加速。
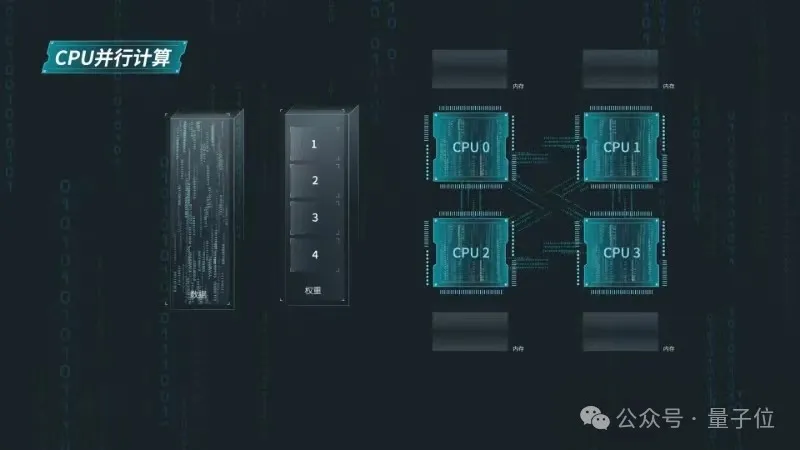
张量并行对模型参数的切分粒度较细,要求CPU在每次张量计算后进行数据同步,增加了对CPU间通信带宽的需求。
不过,UPI总线互联的通信方案,刚好能够满足CPU间通信要求。
同时,对于千亿参数大模型的张量并行计算,4颗CPU与内存之间海量的通信需求达到2TB/s,远高于CPU的内存通信带宽。
为降低千亿参数对CPU和内存的通信带宽门槛,浪潮信息对源2.0-102B模型采用了NF4量化技术。
NF4(4位NormalFloat)是一种分位数量化方法,通过确保量化区间内输入张量的值数量相等,来实现对数据的最优量化。
特别地,NF4量化非常适合近似正态分布的数据,这与大模型的权重分布方式十分契合,所以通过NF4量化,可以获得比传统的INT4或FP4量化更高的精度。
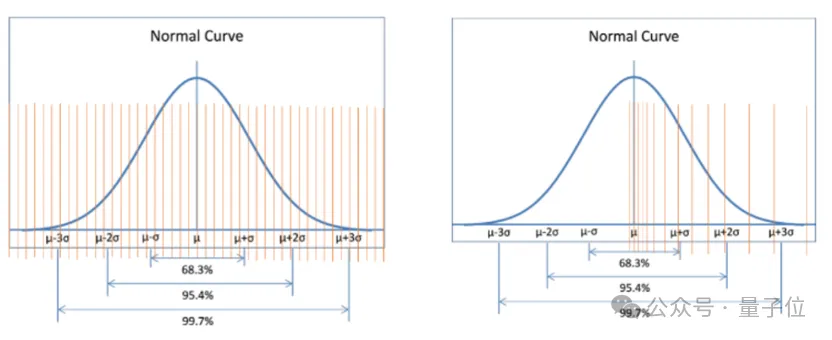
△INT4数据类型与NF4数据类型对比
但NF4量化也带来了新的问题——NF4量化后,会产生大量的scale参数。
假如按照64个参数作为一个量化块计算,对于一个千亿参数的大模型,仅存储scale参数就需要额外的6GB内存。
为了减少内存占用,浪潮信息还通过嵌套量化将这些scale参数量化到FP8精度,显著减少了所需的存储空间。
通过NF4量化和嵌套量化,模型的每个权重仅占用1/2字节空间,Yuan2.0大模型占用内存容量缩小到原来的1/4。
有AI芯片,为什么还要用CPU推理?
浪潮信息的这套解决方案,的确让千亿大模型在通用服务器上的运行成为了可能。
但我们仍然想问,明明有很好的AI加速芯片,为什么还要执着于研究CPU推理呢?
首先一点,是拥有更低的部署和推理成本——
从传统行业用户需求看,通用服务器的成本优势显著,较AI服务器成本可降低80%。
这样的成本节约不仅仅包括设备的购置部署,还包括与行业用户现有系统的融合。
采用通用服务器,意味着大模型服务可以更容易地与已有的企业IT系统进行合并,免去了部署AI服务器带来的迁移适配工作。
当然在技术层面,CPU方案的一些优势也是AI加速卡无法比拟的。
内存方面,通用服务器的内存容量远大于现在GPU芯片能够提供的显存容量。
比如在一台双路服务器上,可以很轻松地把内存做到1TB,像NF8260G7这种四路服务器还能做到更大。
所以。对于一个千亿甚至数千亿的大模型,采用通用服务器进行部署,可以说在内存上完全“不受限”,完全能够放得进去。
相比之下,以GPU为代表的AI芯片虽然算力强劲,但内存就显得捉襟见肘了。
AI大模型的运行不仅需要大内存,更需要高速的CPU和内存通信带宽。而基于先进的量化技术,浪潮信息的研发工程师在不影响模型精度的情况下对模型进行量化“瘦身”,大大降低了千亿参数对CPU和内存的通信带宽门槛。
同时,为了满足模型需求,需要多颗芯片协同工作。这就涉及到了通用服务器芯片间的通信效率。
目前一些高端AI芯片也有高速带宽(比如NV Link),但由于成本较高,这样的方案往往在一些比较高端的芯片或者说高端的服务器上才会采用。
而且,这样的算力目前更多地被用于模型训练,用做推理在经济上并不划算。
在通用服务器当中,CPU和CPU之间拥有高速互联通信的链路,通过并行计算环境的优化,无论是在带宽还是在延迟上,完全可以满足千亿参数大模型运行过程中多计算核心通信的需求。
此外,随着新一代CPU开始加入AI加速指令集(如AMX),CPU的AI算力性能也在快速提升。
以浪潮信息现在采用的6448H为例,这样的一个四路服务器的算力也到430TOPS(INT8)或215TFLOPS(BF16),完美满足运行AI大模型推理的算力需求。
通用算力正在发生“智”变
站在更高的层次上看,基于NF8260G7的通用服务器大模型推理方案,也是浪潮信息战略中的重要一环。
包括AI技术在内,科技进步的最终目的是“落入凡间”,赋能千行百业。
与此同时,AI正在从专门的计算领域扩展到所有的计算场景,逐步形成“一切计算皆AI”的格局。
AI计算从以云端、服务器为主开始向手机、PC等各类端侧设备蔓延开来。
CPU、GPU、NPU等各种PU,也都被用于了AI计算。
在这样的趋势下,传统上认为非典型的AI算力也在发生“智”变,向着智能算力演变。
具体到以CPU为核心的通用算力,能否运行千亿参数大模型,是衡量其能否支撑千行百业智能涌现的关键。
浪潮信息此次的推出的新方案,填补了行业中千亿大模型通用服务器运行方案的空白,将作为一种更经济的千亿大模型部署方案,成为企业拥有AI的新起点。
未来,浪潮信息将继续坚持在算力、算法和数据三要素上的全面发力,实现更多的系统突破,让AI更深入地走进各行各业。
- 电视装了智能体,只凭台词就能找到剧集了2025-04-24
- 无需数据标注!测试时强化学习,模型数学能力暴增 | 清华&上海AI Lab2025-04-24
- “史上最快闪存技术”登Nature!复旦新成果突破闪存速度理论极限,每秒执行操作2500000000次2025-04-23
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23