任少卿详解智能驾驶世界模型:一个真实场景,生成万千平行世界,AI在想象中学习推理
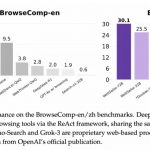
“智驾领域NWM性能强于Sora”
一凡 整理自 NIOIN 2024
智能车参考 | 公众号 AI4Auto
AI大牛任少卿,发布世界模型。
在蔚来科技日上,蔚来智能驾驶副总裁任少卿登台,发布了蔚来世界模型NWM(NIO World Model)。
该模型和端到端架构结合,能够进一步提升算法对复杂场景的处理能力。
NWM类比人脑,具有想象推演和想象重建能力,可以根据一个真实场景,生成一万个“平行世界”。

以下为任少卿演讲全文
成绩回顾
我是任少卿,来自蔚来的智能驾驶研发团队,很高兴第二年与大家在NIO IN见面。
去年NOI上,朋友告诉我故事说得不错,技术做得也不错,但是讲的人话不太多,所以今年争取讲一些大家能听懂的。
去年我们发布了蔚来的全域领航辅助 NOP+,通过线路共享、汇线成网的方式,做城区的开通。从去年9月到今天,全域领航辅助NOP+已经开通了非常多城市,389.9万公里已经覆盖。可以看到,我们的蔚来用户是一群非常喜欢自驾也非常喜欢开车的用户。
所有前面这些道路开通,这样的里程实际上都要得益于底层的群体智能系统,在过去一年帮助了我们很多。我们实际的车云算力有高达287100POPS,4.2亿公里的实际道路验证里程,在这4.2亿公里里面,每个月都可以发现2.2亿个样本去帮我们做相应的问题发现,帮我们做相应的问题解决和迭代。以上所有帮助我们的行车以及安全的功能持续地在快速迭代和演进。

其实智驾已经进入了一个新的阶段,除了城区的开通,今年越来越多地说端到端的架构。出门的时候,做技术的同学会问一问你们的端到端上车了吗?你上的是哪种端到端?实际上我们265的版本上已经上车了。首先要技术升级,安全落地。265的版本上,基于端到端架构的AEB功能,已经在很多用户的车上。去做这个主动安全,其实最大的挑战是需要去覆盖真实的场景,同时又要去减少误制动。大家看到的是法规的场景,它是一些平行、垂直的场景,前面有辆车,正向向它开着的时候,车能刹住。
法规在最新的法规标准上加了一些转弯的场景。
但是对标真实的场景,法规的场景还是远远简单。我们去统计了相应的数据,法规场景只能占真实世界场景的10%。
如何解决真实世界的复杂性?
真实世界的复杂性怎么去解决它,使得大家更加安全,才是我们要做的。解决这个问题实际上需要有新的技术。我们引入了端到端的、主动安全的技术,通过这一技术,在路口无论两轮车从什么角度切入,我们的车都能在安全的地方刹停,如果有必要的话。这背后其实是一个技术的升级,同时也是对于数据的巨大的挑战。实际在应用里面,我们收集了20亿公里真实的驾驶场景事故。平均有一万个事故。同时我们有10轮4亿真实道路验证,所有这些事故的、验证的数据,加起来赋能我们端到端的主动安全。刚才是比较感官的视频,这里是比较真实的数据。AEB所覆盖的场景比标准AEB覆盖的场景高达6.7倍之多。基于整体端到端的架构,我们会把主动安全升级成蔚来智能安全辅助2.0。它里面就包括我们端到端的AEB,也包括后面会推出的端到端的GOA,大幅提升了我们响应的场景。之前智能响应讲法规的场景非常多,现在可以相信真实的场景,真正从标准场景走向真实世界里面的解决这些复杂的问题。除了覆盖场景变多,我们最大刹停速度也在持续提升。现在主动安全的端到端AEB已经上线,端到端GOA,不标准物体的也会持续上线。2.0会帮助大家开得更安全。
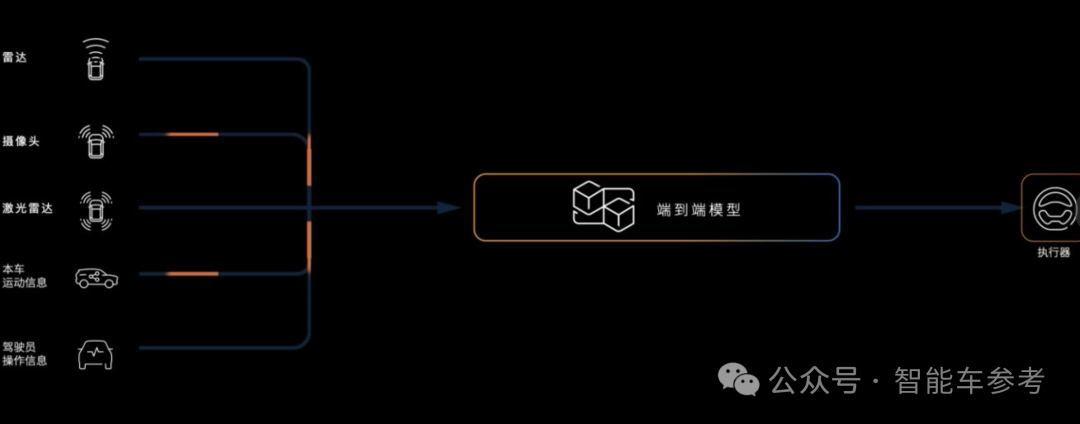
前面主要介绍功能,功能背后说了很多端到端的功能,实际上是算法的提升。传统的主动安全为什么做得这么困难?刚才说了要去解决真实的场景,同时它又要做到非常非常小概率,十万公里以上,才能有一次误刹,否则会带来非常大的困扰。传统通过感知算法的提出,在后面让人工去针对一个一个的场景去写规则,这些场景怎么处理。法规场景可以去计数,但是真实场景千千万。对于真实场景,让研发工程师一个一个写规则已经不可能了。所以我们需要去升级这个算法,使它变成端到端的。从人工写规则解决问题,研发工程师一个人分多少个case,变成一个模型收集数据,数据去教模型解决问题。基于这样一个端到端的算法,刚才看到了它的性能提升非常大。
总结来说,实际上有两大优点。第一个是从人工的写规则变成了模型,依靠模型和数据去做迭代。能充分地利用这个数据。第二个就是我们前面所说的,在人工写代码的过程中有很多信息的损失,基于模型能自动地抽取信息,减少了很多信息损失。使得我们对于数据的利用更加充分。但是,我们还想回答一个问题,大家都在说端到端。到底端到端够了吗?以及我们人在开车的时候或者在做其他事情的时候,它还有没有一些其他的、跟端到端不一样的、比它更强的能力。我们的车,车上智驾的智能体是不是也能学会这些能力,使得它开得更好?
好的,我们带大家做一个实验,我们是一个冥想实验。请大家坐坐好,闭上眼睛。像NOMI一样,天黑请闭眼。好的,我们一起想象,有一棵树,这棵树生长了十年,枝繁叶茂。现在是个夏天,夏天的午后,太阳晒在树上,微风吹过,发出沙沙的声音,时光荏苒,三个月很快过去。从夏天到了秋天,秋天的树一片金黄。又过了三个月,从秋天到了冬天。下雪的日子里,树上一片雪白。好的,感谢大家,我们睁开眼从大家想象的世界,回到现场,回到现实世界。
实际上刚才是一个大脑的探索之旅。大家之前可能不会意识到,其实我们做的时候,每一个做AI的人都会感叹人类大脑的能力。这里面我们显示了一个人类的大脑。从左边的眼睛,往上到蓝色的区域是下丘脑,到黄色的区域是大脑皮层。
它建立了一个叫做内在模型的大脑模型。这个有什么用呢?就像刚才我们大家所感受到的,当我们闭上眼的时候,虽然眼前没有这棵树,但是大家的脑海里面出现了一棵树。
而且看起来还很真实,这是第一个。第二个晚上睡觉的时候,会做梦,梦里面会出现各种各样的场景,那是你平时遇到的,或者很多年前遇到的。我昨天晚上准备PPT的时候,躺在床上,也浮现了第一页大概什么样,第二页大概什么样。相信大家都会有这样的经历。
这是第二个例子。第三个例子,我们走在家里的小区的路上或者你平时经常走的路上,那时候可能也没太在看这个路,在打电话或者在吃东西。但是实际上这条路上旁边会有什么,大概的路的形状是什么样,在你脑海里面一清二楚,早就建立了整体这个路的所有形状。
总结来说大脑有两个非常核心的能力。第一个能力是空间理解能力,也叫想象重建能力:就是刚才跟大家说的,我们要想象一棵树的时候,你并没有看见它,但是你的眼前就出现了。
第二个能力是时间理解能力,或者叫想象推演能力:想象一棵树从夏天变成秋天,从秋天变成冬天,它在你的脑海里面,时间的变化。现实中六个月的时间变化,在你脑海中两秒钟就完成了,时间的变化在你脑海里面完全被重构。
这两个能力合起来构成了我们说的时空的认知能力——对于我们生活的三维空间和一维的时间所发生的所有变化和可能性的认知能力。这个能力对于我们人类来说,生活在这个地球上非常重要。对于我们的智能体来说,如果去开车的是一个机器人,也同样重要,我们去建立了一个在它的脑海里面的,能够构建抽象的世界的能力。它是符合相应的规则规律的,尤其是物理规律,也叫时间模型。
我们认为聪明的智能体需要像人一样,具备空间认知、想象重建,以及时间认知、想象推演的能力。但是回到那个问题,端到端就够了吗?我们认为是不够的,因为端到端的模型并不必然具备刚才我们说的这两个核心能力。我们希望去构建一个模型,它像我们人类的大脑一样,有这样的内在模型,有这样的对于空间的想象、对于时间的推演能力。实际上在我们去年NIO IN上已经说了,有这样的世界模型的模块在。经过一年发展,可以跟大家聊一聊这一块的工作,我们准备在接下来的日子里面把它们进行量产。总结一下,蔚来世界模型NWM——NIO World Model就是这样一个东西。希望这个模型学到人对于空间的认知,做想象重建,以及对于时间的推演。
蔚来世界模型NWM介绍
第一个部分学会对于空间的认知,要想象重建。我们认为重建是对于这个空间理解的最高表现。回到刚才大家想象的这棵树,这是一棵真正的树的图片。
有些人想的是这样,但是应该很少,想得不太丰富。还有更加丰富的信息会变成这样,树苗,它想象的信息更多了,说明对于空间的理解更多了。相信在座的各位想象的至少是这样,它是一颗会动的、非常真实的、实际存在的树。当然也是我们所说的Banyan。会动的树,对于我们来说,代表了大家对这个树非常熟悉。第二有非常强的想象重构能力,第三对空间认知很深,也是特别聪明的智能体。
我们希望模型干这件事。怎么干呢?我们简化了模型的输出,希望模型能输入视频也能输出视频。输入一个树,输出一个会动的树。输入一个真实世界的行车视频,输出另外一个更平行的世界。这是我们模型的基本能力。
实际上智能驾驶的发展过程都是在做空间理解的升级。这是大家最初看到的原始的视频,很清楚。
五年前的智能驾驶算法,把一个视频变成了刚才大家看到的这样,底下有框有线。车是一个框,地上是车道线。提取了信息,但是不是很多。
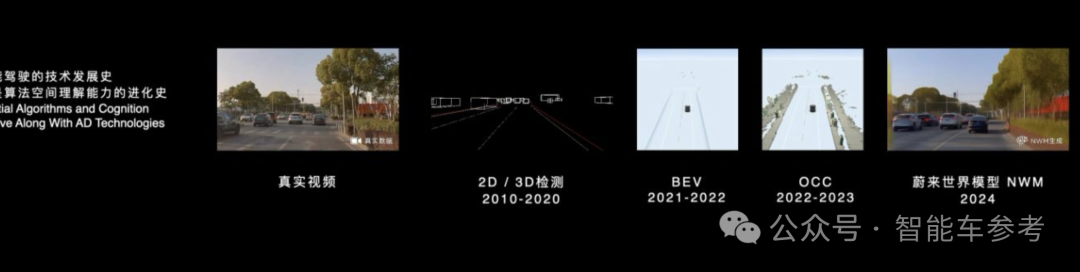
后来,算法演进了。我们把BEV的算法提出来,提取的信息并且比五年前要多。但是它实际上还缺了路边沿的信息。我们又推出了OCC,从2D信息的表达变成了3D,有点像小时候打的马赛克游戏,信息丰富了非常多。
但是如果我们对比一下OCC的视频和真实世界的视频,实际上还缺了信息。比如路上的材质,比如现在是下雪天,比如细小的物体,这边进入一个收费站,有一些抬杆,就不会有。
OCC已经很好了,但是还是不够,对于空间的理解已经不错了。我们希望它能进一步加强,进一步加强是什么呢?
我们对于整体的世界做再一次的重构,变成类似于原始的信息。视频右下角标了。这是蔚来世界模型NWM生成的世界,是模型想象出来的。它看到了右边真实的世界,想象出来一个平行世界。从信息抽取的角度来说,我们觉得它是一个更加终极的状态。智能驾驶整体技术发展史,实际上是算法的空间理解能力的进化史。
有了重构的能力,意味着算法模型可以对真实世界有更深的理解。
真实世界就像刚才大家所想象的树一样,每个人想得不一样,有的是榕树,有的是松树。我们希望模型也能干这件事,这个模型就去学习了,去生成了。这是雨天、雪天、夜晚的时候、白天的时候以及其他的所有的场景,包括我们的城区,我们的高速,我们的小路。这些视频都是模型生成出来的,并不是真实的视频。
前三秒是真实的视频,后面所有都是模型生成出来的。相当于模型看了很多很多视频,学习了真实世界的千万种可能,在它的脑海里面想象重构出来。它能想象出来,其实某种程度上代表它具备了解决这些场景中驾驶问题的能力,有了把这个场景开好的基础。
世界模型的优势
前面说的想象重构,我们说了比较多的视频例子,实际上从算法端来讲,架构还有额外的好处。第一个,它是一个自监督的过程,不太需要数据标注,更高效,我们可以比较容易地做到千万级的数据收集。第二个是重建的视频,任务更困难,监督信息更多,收集速度更快。前面是我们说的第一个能力,想象重构的能力。
第二个,我们还希望在时间维度上去做推演,从秋天到冬天,去想象它的变化。我们认为这个想象变化的能力才是大家对于时间乃至时空的真正理解。想象的真实度和丰富度,大家对于这个理解深度的体现。去年Sora大火,整个Sora生成视频模型,为什么轰动世界?总结几点。

第一个生成视频看起来真实。第二个生成的各种场景都可以。第三个相比于之前的很多算法,生成视频长度多了很多。物理的模型,时空的认知虽然不是很完全,但是这确实是人工智能方向界的进步的一大步。我们希望蔚来世界模型NWM也能够做想象推演。除了前面所说的,输出图片,我们也希望模型持续地去想象,持续地以自回归的方式去输出视频,在时间维度上去做推演。这个是我们的模型生成的一个长视频,这个视频两分钟以上,实际上是超过了现在绝大多数的视频生成软件。对于驾驶环境,即使它开得很慢,30公里每小时,两分钟也开了一千米以上。这体现了需要生成非常复杂的背景,非常复杂的变化,后面还有堵车的场景,真实多变,同时符合真实的物理规律。
它就使得我们这个模型对于这个时空的理解更深。这是表现。内在理念,为了做好这件事情,有非常多的困难。第一件事情需要想象重建的能力更精确,依赖于模型的好,也依赖于数据的真实和数据的多。这跟人其实有点像。大家对很熟悉的场景,比如树每天都能看到,你想象的时候就会非常具体、非常真实。如果是一个每天看不到的事情,一年两年只能接触一次,想象的时候就非常模糊。模型也一样,需要大量的数据去进行学习。
第二个,它是一个很长的视频,我们希望在时间轴上能够做到很好的连贯,因此需要新的算法,开发了新的时空encoding的方式。其他还有工程上的困难,今天不过多说了。主要在数据训练和内存上。这是我们现在看到的在智能驾驶领域,去做这个视频生成最好的模型。在这个领域,比Sora的性能还好,我们是领域内的一个模型。
除了做这样的让模型去想,想得很长。大家刚才看视频,跟我们人类做梦或者是你闭着眼想象,画面挺像的。但是除了我们希望它开放式地想象,也希望它能接受我们一些指令。
比如我们在这里面加入了我们的智驾相关的指令,包括左转右转、左变道、右变道等,以及任意打方向盘的角度、控制速度等微观细节。我们可以让模型按照我们的控制,去进行这个想象的行为。
这里实际上是一个视频,中间是我们的真实视频。我们让模型按照我们想要的方式,去想象了这个世界的一万种平行世界的可能。中间是我们跟着一辆红色的卡车,它开得比较慢。我们希望看看,是不是有可能从左边变道超过去,或者跟在它后面,所有这些可能会是怎么样。
实际上这里面我们只列了模型生成的非常多种可能性中的很小一部分。它能想象万千的世界。这些想象都比较真实,同时又很多变。覆盖了我们在开车的各种场景。我们认为这样的一个模型,它对于时空的变化理解已经很深刻了。它能想象出来万千世界,也能从万千世界里面找到最好的一种开车的方式,最安全最舒适。或者是最高效,开得快一点。
因为我们前面一个星期跟同事在聊,大家看了这个之后,想到了一个很有意思的场景。前两年有一个很火的题材,无论是视频、电视剧,有一个很火的题材是穿越。《开端》是两年前很火的一个作品。主角遇到了公交车爆炸,他在公交车爆炸之前穿越回另外一个平行世界,去找到可能的解决的办法,让他不停穿,看看能不能找到逃生的机会。实际上在我们的蔚来世界模型NWM里面也能做这件事情。平时开车的时候不小心有一些剐蹭,我们可以让模型穿回到事故前的三秒钟,让它去看看如果遇到这种场景,它能怎么做。我们完全没有教这个模型急刹车、打一下方向盘避让之类的能力。量产的对于高速场景的功能,经过很多人工调校都还是比较稀有的能力。这个模型只是看了视频自然而然地学会了。左边这个场景踩个急刹车,右边这个场景打了方向盘,去穿越到了一个更安全的世界。
前面是我们两个非常非常重要的人脑的能力。想象重建去做这个空间认知,想象推演去做时间认知,合起来是我们的时空认知。所有这些拼起来,构成了蔚来世界模型NWM的最核心的能力和它的大脑。
最终我们其实还是一个智驾的模型,有这样的空间、时空认知能力,最终希望的是它能够去开车,去输出它规划的轨迹——怎么去开这辆车。有了轨迹规划的能力之后,我们就在生成的同时让它想象在一个平行世界里面,去看看这个车应该怎么开。这里面图像、视频,中间绿色的点就是它的驾驶轨迹。
图像的右上角,是有期望的方向盘的角度以及速度。基于这样一个想象的世界,很容易就可以学会怎么去开这个车。实际上而言,蔚来世界模型NWM的脑海里面,每0.1秒会生成216种可能的轨迹,并对每一个轨迹进行评估,选出来最好的。下一个0.1秒,蔚来世界模型NWM会根据外界信息输入去更新,再生成新的216种轨迹,再往前开。以上是我们的想象重构、想象推演、轨迹规划,构成了蔚来世界模型NWM。更多细节,后面有机会再跟大家展开。
相比于常规的端到端的模型,新的世界模型有三个我们认为主要的优势。第一个是在空间理解上,通过生成式模型,从重构传感器的方式,更加泛化地抽取了信息。通过自回归模型,自动建模长时序环境。第三个,万千世界需要更多数据,通过自监督的方式,无需人工标注,它是一个多元自回归生成模型结构,让我们学得更好。以上整体的介绍就是我们的蔚来世界模型NWM——NIO World Model。
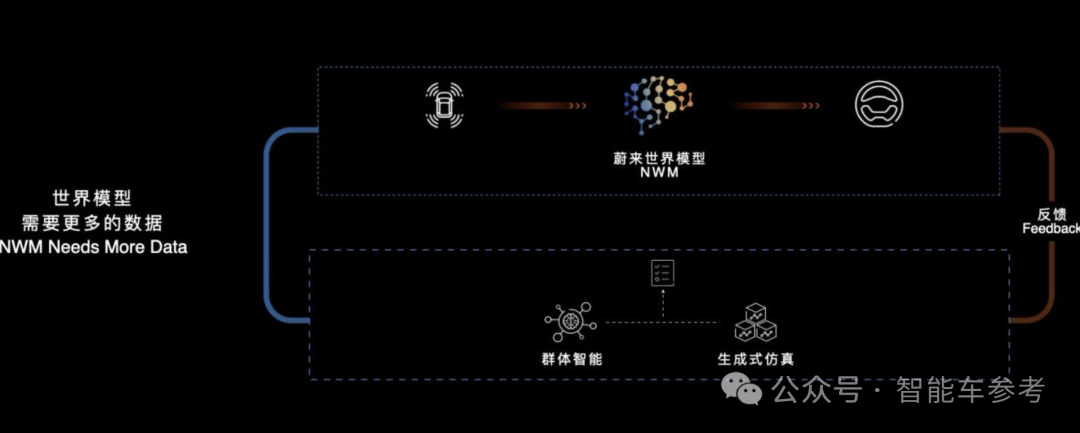
有了新的模型之后,它的能力很强。它就更吃数据,尤其是一个世界模型,需要更多数据。
真实数据并不是那么容易获得,包括大语言模型,包括机器人。实际上我们认为智能驾驶是这些所有AI应用里面数据闭环最为成熟的,但是最有可能做大规模的安全性应用落地的。在我们的体系里面,群体智能和生成式仿真是数据层面的杀手锏,它可以满足整体的世界模型的数据需求。
群体智能今天介绍了很多,在这样一个场景里面,因为我们有大量的量产车,可以把蔚来世界模型NWM的版本去分发到十万辆级的量产车上。可以对比人类驾驶的状态,也可以去对比前面的稳定版本,虽然没有这么聪明,但是它更稳定,是生长得更成熟的智驾方案的结果。看看开得好的场景是什么,拿到智驾场景。同时可以把仿真数据更好地去教这个模型。
我们来看看仿真是在干嘛。这个是使用了真实的视频去重建了世界。它可以切换到任意角度,可以去分析现在的细节信息,这里面是深度。分析了所有数据之后去重建三维世界,这个车已经不太去开原来的轨迹,可以回到任何轨迹,去重建这个世界。同时这些动态的物体可以根据我们所需要去动态地编辑。
所以,所有的这些实际上让我们有了一个能力,去基于这个真实世界的视频去重建一个虚拟的可以任意编辑的世界。大家之后看到这个左边的标记,就是蔚来Simulation的结果。仿真的生成结果给我们提供了更多可能。有什么用呢?我们的蔚来世界模型NWM,原始视频去想象接下来可能发生的结果。
它可以想象很多,这里面举的例子,想象了左转、直行、右转的情况。真实世界只有一种情况,真实世界是直行。蔚来世界模型NWM,把真实世界直行的结果和它想象出来直行的结果,做验证、做对比、做学习。只有一个真实世界能去让它学习。但是有了刚才说的蔚来Simulation的仿真之后就不一样了。蔚来世界模型NWM可以想象出千万种可能,仿真也可以根据它的想象,根据输出的轨迹,去生成千万种可能。所有一一去做对比,可以在千万个变化的世界里面去共同地验证模型,去训练这个模型。让万千世界想象的结果更真,让它驾驶的输出更好。
这里是一个真实的例子。蔚来世界模型NWM想象了各种可能性,在仿真世界里面按照它的轨迹去开。我们一一在平行世界里面去做对比,使得这个模型学得更好。以上我们说的,多元自回归的生成模型——蔚来世界模型NWM,端到端的主动安全模型,以及相应的处理机制和安全机制。构成了我们算法的第二代的架构。相比于去年的架构,有了天翻地覆的变化。基于全新的架构,也把我们产品端的功能收敛到两个产品,一个是点到点的全域领航2.0,第二个是智能安全辅助2.0。这两个功能会持续地为用户提供更轻松、更安全的行车体验。
基于新的架构,新的这两个功能,点到点的领航辅助功能下半年会上车。智能安全辅助2.0的功能,端到端AEB已经在265上车。包括端到端GOA也会持续上车。刚才说的很多模型实际上都是非常新的,包括生成式的模型,世界的模型,AI技术一日千里,这些模型对于算力的要求更高。4个Orin-X的平台,ADAM的平台有充足的算力储备为用户提供长期的领先体验。同时,我们刚才所推出的神玑 NX9031 芯片,汇聚了芯片同事、智驾同事的很多智慧和心血。天生为了我们这样的世界模型而设计。值得大家更多的期待!
以上所有的技术的提升和产品的升级,都是为了我们的核心的目标和价值,就是解放精力,减少事故,让大家开车更轻松更安全。
谢谢大家!以上是我们智能驾驶的最新进展的介绍。
- 蔚来拼了!19万开走9系大型SUV,李斌一夜封神2025-07-11
- 9个功能点看完蔚来乐道L902025-07-10
- 蔚来李斌“电池太大压坏马路”热搜了2025-07-08
- 李想自曝常和雷军吃饭,不舒服的建议也会提2025-07-07