
OpenAI的《Her》难产,是被什么困住了手脚?
固定网络、固定设备、固定物理环境
两个月又两周过去了,我们仍然没有见到公开发布版的OpenAI《Her》。
5月14日,OpenAI发布GPT-4o和端到端实时音视频对话模式,现场演示AI对话丝滑如人类。
它能感受到你的呼吸节奏,也能用比以前更丰富的语气实时回复,甚至可以做到随时打断AI,效果非常惊艳。
可万众期待中,不时有推迟的消息传出。

是什么拖住了OpenAI的后腿?根据已知情报:
有法律纠纷,要确保语音音色不会再出现与“寡姐”斯佳丽·约翰逊这样的争议。
也有安全问题,需要做好对齐,以及实时音视频对话开启新的使用场景,被当成诈骗工具也会是其中之一。
……
不过,除了以上这些,还有什么技术问题和困难需要克服吗?
渡过最初的热闹后,内行们开始看门道了。
眼尖的网友可能已经注意到,发布会现场演示手机可是插着网线的。

在业内人士眼中,GPT-4o发布会演示效果如此丝滑,还是有几大限制:
需要“固定网络、固定设备、固定物理环境”。
真的公开发布后,全球用户能否获得与发布会相比不打折扣的体验,也还是个未知数。
发布会现场还有一个有趣的细节,帅气的研究员小哥Barret Zoph,在演示视频通话时被ChatGPT当成桌子。
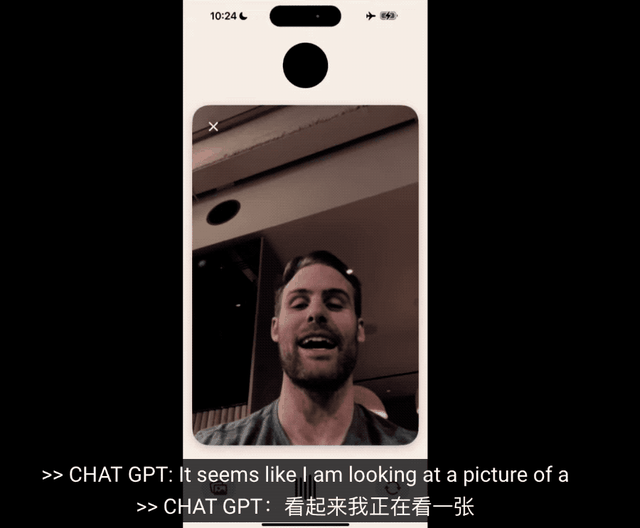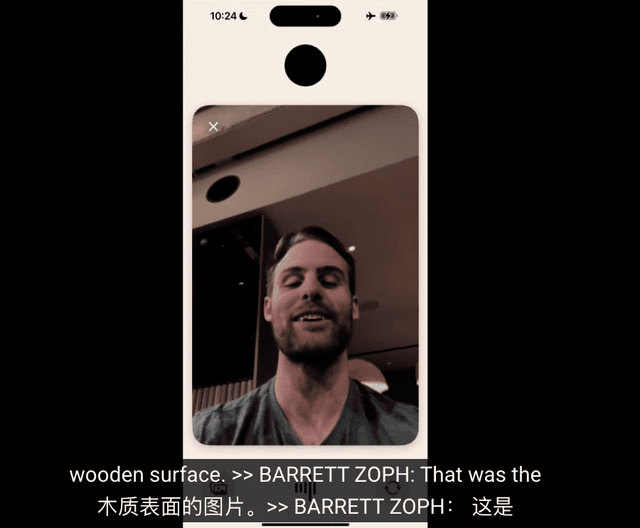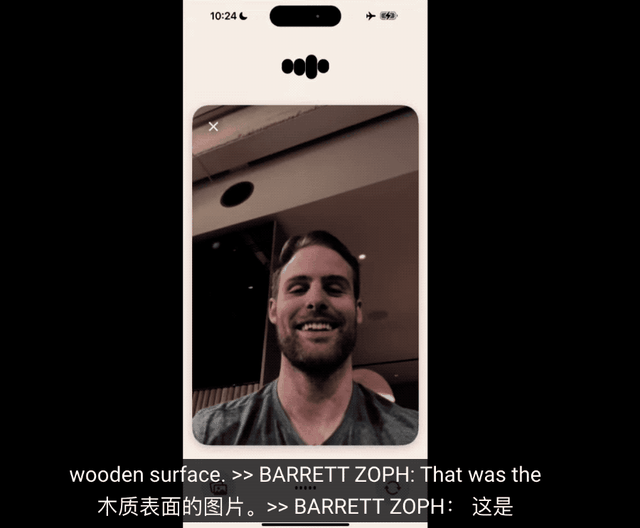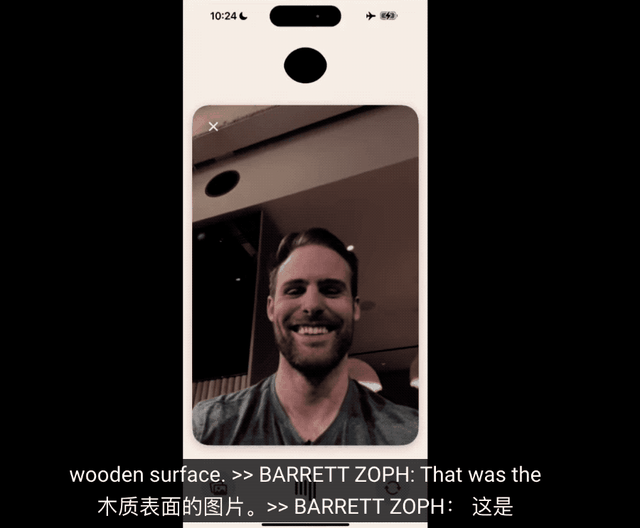
视频通话部分的延迟可见一斑了,语音部分提问已经处理完了,视觉部分还在处理上一个镜头,也就是手机刚被拿起来时摄像头拍到的木桌。
试想最终发布后,很多人用它的场景是什么?
宣传片中一个最为人津津乐道的案例,盲人在AI语音的帮助下招手打车,一时间被网友津津乐道。

不过也要注意到,这会是一个非常依赖低延迟特性的场景,如果AI指导来的稍慢一点,出租车也就开过去了。

室外场景网络信号都不一定能保证稳定,更别提机场火车站、旅游景点这些人多设备多挤占带宽的场景,难度还要增加不少。
此外,室外场景还会出现噪音的问题。
大模型本来就深受“幻觉”问题困扰,如果噪音影响到用户语音的识别,出现一些与指令不相关的词语,那回答就不知道拐到哪去了。
最后,还有一个容易被忽视的问题,多设备适配。
可以看出目前OpenAI发布会和宣传片,清一色用的新款iPhone Pro。
否能在较低端的机型也获得一致体验,也要等正式发布后再揭晓了。
OpenAI宣传GPT-4o可以在短至232毫秒、平均320毫秒的时间内响应音频输入,与人类在对话中的反应速度一致。
但这只是大模型从输入到输出的时间,并非整个系统。
总而言之,仅仅把AI能做好,还搞不出《Her》一般丝滑的体验,还需要低延时、多设备适配、应对多种网络条件和嘈杂环境等一系列能力。
光靠AI,还做不出《Her》
要做到低延时、多设备适配等,靠的就是RTC(实时通信,Real-Time Communications)技术了。
在AI时代之前,RTC技术已广泛用于直播、视频会议等场景,发展的较为成熟。
在RTC视角下,用户的语音提示词在输入大模型之前,还要经历一整套复杂流程。
信号采集与预处理:在手机等端侧设备,将用户的语音采集成原始信号,并对其进行降噪、消除回声等处理,为后续识别做好准备。
语音编码与压缩:为尽量节省传输带宽,要对语音信号进行编码和压缩。同时,还要根据网络实际情况自适应地加入一些冗余和纠错机制,以抵抗网络丢包。
网络传输:压缩后的语音数据被切分成一个个数据包,通过互联网送往云端。如果距离服务器物理距离较远,传输往往还要经过多个节点,每一跳都可能引入延迟和丢包。
语音解码与还原:数据包到达服务器后,系统对其进行解码,还原出原始的语音信号。
最后才轮到AI出手,先通过Embedding模型将语音信号转化为tokens,才能真正让端到端多模态大模型能够理解并生成回复。
当然,大模型生成回复后还要走一套相反的流程,再把回复的音频信号最终传回给用户。
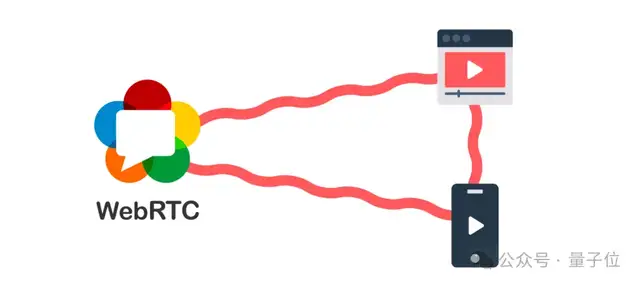
整个一套流程走下来,每一个环节都需要极致的优化,才能真正把AI音视频对话做到实时。
其中对大模型本身的压缩、量化等手段毕竟会影响AI能力,结合音频信号处理、网络丢包等因素联合优化,就显得尤为重要了。
据了解,OpenAI也并不是独立解决这个问题的,而是选择与第三合作。
合作伙伴为开源RTC厂商LiveKit,目前凭借支持ChatGPT语音模式成为业界关注焦点。
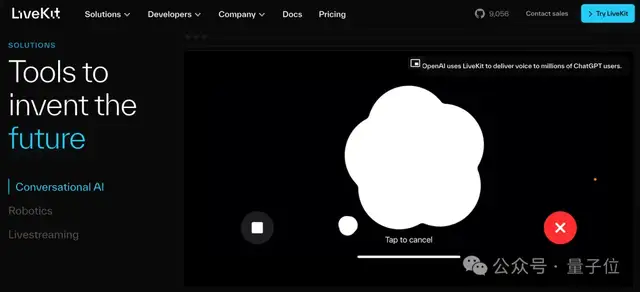
除OpenAI之外,LiveKit与Character.ai、ElevenLabs等相关AI公司也都展开了合作。
可能除了谷歌等少数有较为成熟的自研RTC技术的巨头之外,与术业有专攻的RTC厂商合作,是AI实时音视频对话玩家目前的主流选择。
这一波当然也少不了国内玩家参与,不少国内AI公司已经在加紧研发端到端多模态大模型以及AI实时音视频对话应用。
国内AI应用能不能赶上OpenAI的效果,大家又什么时候能真正亲自上手体验到呢?
由于这些项目基本都在早期阶段,公开透露的消息并不多,不过他们的RTC合作伙伴声网倒成了一个突破口。
量子位从声网处打听到,以目前国内的技术水平,已经能把一轮对话的延迟压到1秒左右,再辅以更多优化技巧,实现能及时响应的流畅对话已不成问题。
- Qwen上新AI前端工程师!一句话搞定HTML/CSS/JS,新手秒变React大神2025-05-10
- DeepSeek新数学模型刷爆记录!7B小模型自主发现671B模型不会的新技能2025-05-01
- 自动化所:基于科学基础大模型的智能科研平台ScienceOne正式发布2025-04-30
- 小扎回应Llama4对比DeepSeek:榜单有缺陷,等推理模型出来再比2025-04-30





