智谱AI版Sora来了!人人免费不限次,有手机就能玩,API也开放了
PC、APP、小程序均可使用
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
就在刚刚,智谱AI版的Sora横空出世,名曰清影。
话不多说,直接来看一下通过清影生成的一部短片。
视频地址:https://mp.weixin.qq.com/s/XmXR-XZtMvhZHtLTCxU4ZQ
在文生视频方面,例如给清影一段Prompt,可以挑战一下它的想象力:
在霓虹灯闪烁的赛博朋克风格城市夜景中,手持跟拍的镜头缓缓推近,一个机械风格的小猴子正在用高科技工具维修,周围是闪烁的电子设备和未来主义的装修材料。赛博朋克风格,气氛神秘,4K高清。
视频地址:https://mp.weixin.qq.com/s/XmXR-XZtMvhZHtLTCxU4ZQ
赛博朋克、未来感味道十足,是比较贴近我们脑海中想象的那种画面了。
而除了文生视频之外,清影这次把图生视频的能力也一道发布了出来。
现在,让我们一同来比较一下你的想象力,和清影的创造力,到底谁更胜一筹。
请看第一张图——洞穴文明:
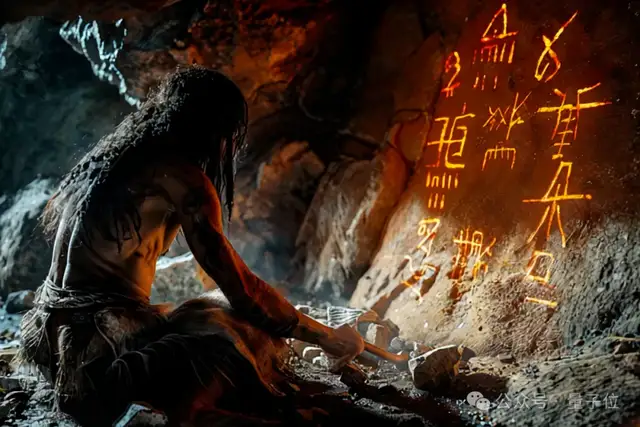
然后下面这段视频便是清影用AI Power创造并配乐的版本:
视频地址:https://mp.weixin.qq.com/s/XmXR-XZtMvhZHtLTCxU4ZQ
视频的最后,清影竟然还学会了在关键帧处晃动下镜头,让视频更具神秘的味道。
接下来,我们再来Round 2,依旧是先一起来看图——火龙吐息:

清影根据这张图所制作视频的打开方式是这样的:
视频地址:https://mp.weixin.qq.com/s/XmXR-XZtMvhZHtLTCxU4ZQ
是能想象到这条龙准备喷火,但是却没想到是烧了地上的村庄,不过也是合情合理的那种。
但纵观智谱AI的整活发布活动,高清、画面一致性的效果还仅仅是亮点中的一隅,更重要的是它把福利值给拉满了!
全民免费,不用排队,不限次数!
而且效果上,更是直接把自家视频生成大模型CogVideo的能力马力全开,不搞饥饿营销。
据智谱AI介绍,仅需30s的时间,就能生成出6s的1440×960视频,模型推理的速度足足提高了6倍之多。
不仅如此,现在在智谱轻言的PC版和APP上,文生视频/图生视频的功能都已经开放;小程序方面,目前则是暂时只支持图生视频。
对开发者来说也有个利好的消息,这次视频生成大模型的API也已经全面开放了,是国内首个哦!
不得不说,便捷和高效这块,智谱AI这次也是拿捏到位了。
那么接下来,是时候用智谱AI的视频生成功能来搞事情实测一波了。
实测智谱AI版Sora
我们先来测一波文生视频的效果。
打开智谱轻言APP或PC版,文生视频的入口就在主对话里了。
以APP为例,界面是这样的:
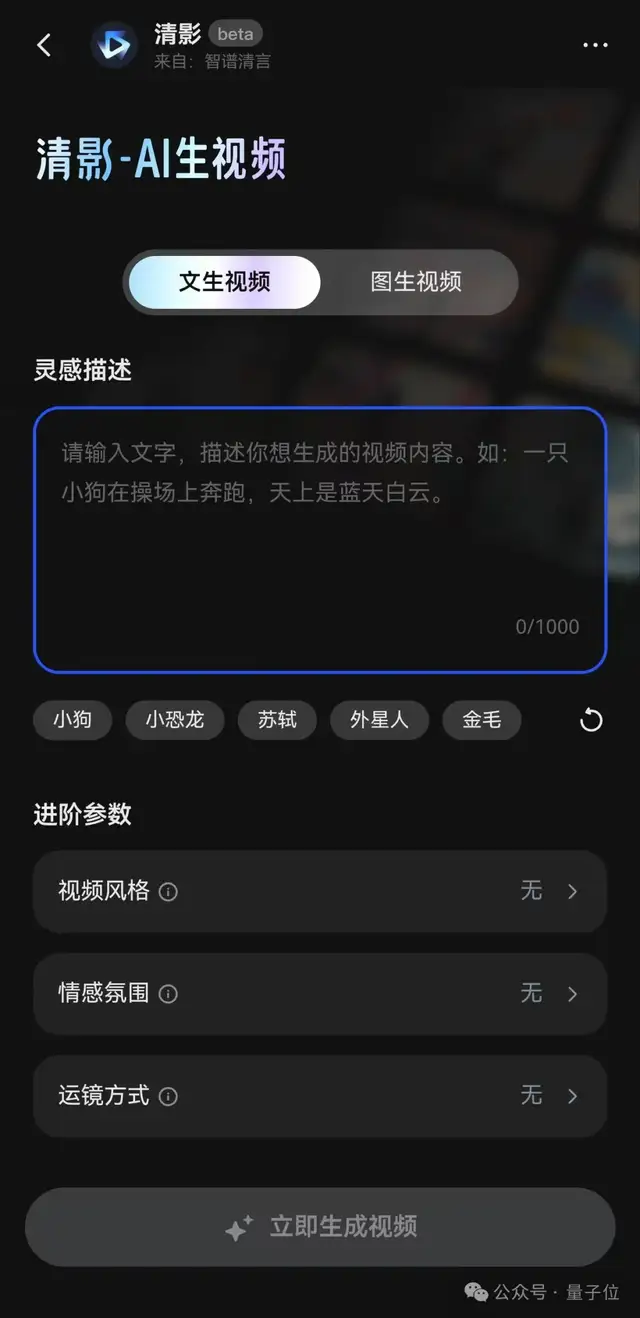
然后万事俱备,只差输入Prompt了。
但需要注意的是,这却是决定视频生成效果成败关键中的关键。
一个最重要的原则就是:结!构!性! 公式如下:
- 简单公式:[摄像机移动]+[建立场景]+[更多细节]
- 复杂公式:[镜头语言] + [光影] + [主体 (主体描述)] + [主体运动] +[场景 (场景描述)] +[情绪/氛围/风格]
那么效果会差多少呢?
例如如果只输入:小男孩喝咖啡,生成的结果是这样的:

中规中矩,但却是一眼AI的感觉。
但如果把提示词按照公式丰富一下,那么打开方式就截然不同了:
摄影机平移,一个小男孩坐在公园的长椅上,手里拿着一杯热气腾腾的咖啡。他穿着一件蓝色的衬衫,看起来很愉快,背景是绿树成荫的公园,阳光透过树叶洒在男孩身上。
视频地址:https://mp.weixin.qq.com/s/XmXR-XZtMvhZHtLTCxU4ZQ
这不,电影感一下子就出来了。
但除了刚才的公式,还有几个重要的原则也可以参考一下。
首先,重复就是力量。
在Prompt的不同部分重复或强化关键词有助于提高输出的一致性。例如,摄像机以超高速镜头快速飞过场景(其中的“超高速”、“快速”就是重复词)。
其次,尽量让你的Prompt集中在场景中应该出现的内容上。例如,你应该提示晴朗的天空,而不是没有云的天空。
有了这些公式和原则之后,我们就可以大展拳脚地尝试一番了。
小王子和狐狸在月球一起看星空,狐狸时不时看向小王子。
写实描绘,近距离,猎豹卧在地上睡觉,身体微微起伏。
除此之外,根据智谱AI的介绍,多试几次,说不定会出现意想不到的效果(反正是免费的)。
在文生视频之后,我们就再来测试一波图生视频。
这里也有两个比较关键的技巧。
首先就是上传的图片要尽量清晰,比例最好是3:2,格式方面则是jpg或png。
其次依旧是Prompt,一定要有主体,然后可以根据“[主体]+[主体运动]+[背景]+[背景运动]”这样的公式来撰写Prompt。
当然如果没有Prompt也是可以的,但AI就会根据自己的想法天马行空地生成视频了。
例如我们“喂”一张唐僧的照片:

然后根据刚才给的公式技巧,Prompt如下:
唐僧伸出手,戴上墨镜。
由此,玩法(搞事情)就变得多起来了。
例如让甄嬛和沈眉庄“破壁”相拥:
甄嬛眉庄跨屏拥抱。
老照片复活也不在话下:
胡适,转身离开。
从种种效果来看,智谱AI的清影,是一个可以拿来直接上手用的那种类Sora了。
那么接下来的一个问题是:
怎么做到的?
在视频生成这个领域中,输出内容的一致性和连贯性,是决定最终效果的关键因素。
为此,据智谱AI所述,团队自研了一个高效的三维变分自编码器结构(3D VAE),将原视频空间压缩至2%大小,大大减少了视频扩散生成模型的训练成本及训练难度。
在模型结构方面,智谱团队则是采用因果三维卷积(Causal 3D convolution)为主要模型组件,移除了自编码器中常用的注意力模块,使得模型具备不同分辨率迁移使用的能力。
与此同时,在时间维度上因果卷积的形式也使得模型具备视频编解码具备从前向后的序列独立性,这么做的目的是方便通过微调的方式向更高帧率与更长时间泛化。
从工程部署的角度,智谱AI是基于时间维度上的序列并行(Temporal Sequential Parallel)对变分自编码器进行微调及部署,使其具备支持在更小的显存占用下支持极高帧数视频的编解码的能力。

但除了内容的一致性和连贯性之外,视频生成还存在的一个问题是——现在的视频数据大多缺乏对应的描述性文本或者描述质量低下。
为此,智谱AI自研了一个端到端的视频理解模型,用于为海量的视频数据生成详细的、贴合内容的描述。
如此一来便可以增强模型的文本理解和指令遵循能力,让生成的视频更符合用户的输入,能够理解超长复杂Prompt指令。
最后,智谱AI还自研的一个将文本、时间、空间三个维度全部融合起来的Transformer架构。
它摒弃了传统的cross attention模块,而是在输入阶段就将文本embedding和视频embedding concat起来,以便更充分地进行两种模态的交互。
然而两种模态的特征空间有很大差异,团队通过expert adaptive layernorm对文本和视频两个模态分别进行处理来弥补这一差异,这样可以更有效地利用扩散模型中的时间步信息,使得模型能够高效利用参数来更好地将视觉信息与语义信息对齐。
其中注意力模块采用了3D全注意力机制,先前的研究通常使用分离的空间和时间注意力或者分块时空注意力,它们需要大量隐式传递视觉信息,大大增加了建模难度,同时它们无法与现有的高效训练框架适配。
位置编码模块设计了3D RoPE,更有利于在时间维度上捕捉帧间关系,建立起视频中的长程依赖。
以上便是智谱是如何炼成清影背后的关键技术实力了。
One More Thing
除了这次免费版之外,智谱AI还推出了付费版本,价格是这样的:
- 5元:解锁24小时的高速权益
- 199元:解锁一年的高速权益
年费换算一下,也就是每天仅5毛4。
嗯,着实有点香。
体验链接放下面了,感兴趣的小伙伴可以去试试喽~
https://chatglm.cn/video
- 14.9万元,满血流畅运行DeepSeek一体机抱回家!清华90后初创出品2025-04-29
- 全球第一车企,集齐中美双版Waymo2025-04-30
- 全栈AI基础设施支撑,跑出全球首个开放使用视频生成DiT模型2025-04-28
- 亚马逊云计算Troy Cui:敦煌网飙升AppStore第二,企业如何应对激增流量是关键 | 中国AIGC产业峰会2025-04-27