
专治大模型“刷题”!贾佳亚团队新基准让模型只挑错不做题,GPT-4得分不到50
涵盖多个学科,难度等级也有区分
MR-Ben团队 投稿
量子位 | 公众号 QbitAI
大模型测试能拿高分,实际场景中却表现不佳的问题有解了。
贾佳亚团队联合多家知名高校提出了一种全新的测评方法,让一些模型立马现出了原型。
这下不用担心大模型“刷题”太多,测试集无法体现真实水平了。

这个新的测评数据集叫做MR-Ben,利用的是GSM8K、MMLU等数据集中的现有题目。
只不过,大模型在测试中的身份从“答题学生”变成了“阅卷老师”,任务是要给已有的解答步骤指出错误。
这样一来,模型无法再通过背诵或猜测撞对题目,测试题泄露也无需担心了。
利用MR-Ben,贾佳亚团队评测了GPT4-Turbo、Cluade3.5-Sonnet、GLM4、Qwen2-70B等许多开源和闭源模型。
目前,该数据集涉及的所有代码和数据均已开源。
熟悉的试题,全新的任务
目前,大模型测试的主流方向是使用人类的标准化考试——选择题和填空题的方式去进行大模型评测。
这套测试方式的优点是标准明确、指标直观,且量化结果天然具有话题性。
但作者认为,由于现在的大模型普遍采用逐步作答的思维链方式生成最终答案,导致这种方式并不“靠谱”。
预训练模型在预训练时早已见过数以万亿级别的token,很难判断被评测的模型是否早已见过相应的数据,从而通过“背题”的方式回答正确。
而因为评测的方式主要靠检查最终的答案,因此模型是否是基于正确的理解推理选出正确的选项,也不得而知。
尽管学术界不断地对诸如GSM8K、MMLU等数据集进行升级改造,如在GSM8K上引入多语言版本的MGSM数据集,在MMLU的基础上引入更难的题目等,依然无法摆脱选择或填空的窠臼。
并且,这些数据集都已面临着严重的饱和问题,大语言模型在这些指标上的数值已经见顶,并逐渐丧失了区分度。
为此,贾佳亚团队联合MIT、清华、剑桥等多家知名高校,与国内头部标注公司合作,标注了一个针对复杂问题推理过程的评测数据集MR-Ben。
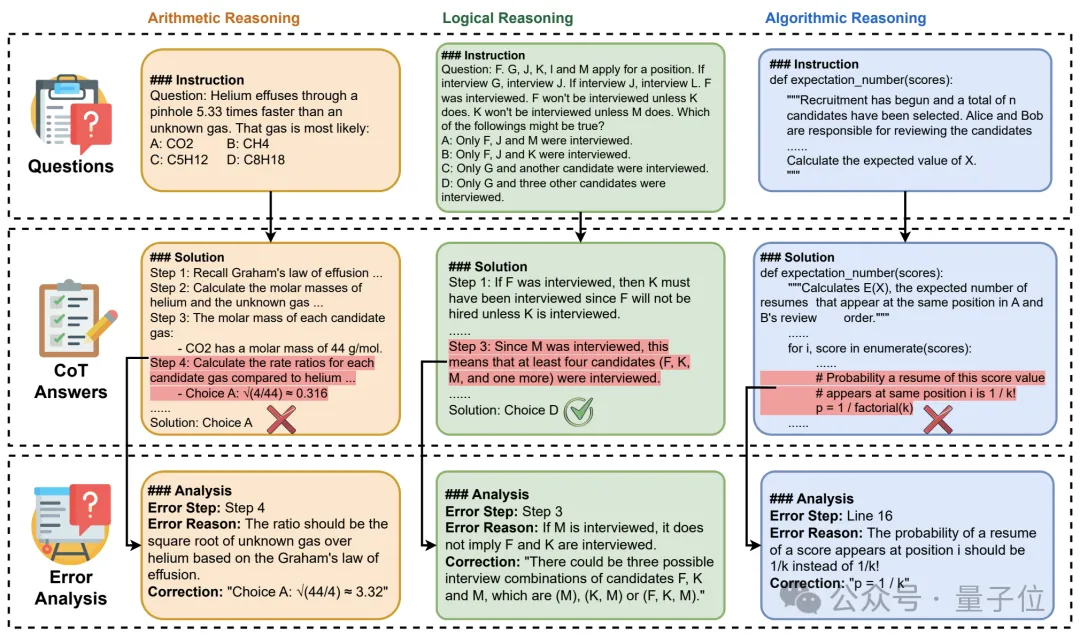
MR-Ben基于GSM8K、MMLU、LogiQA、MHPP等大模型预训练必测数据集的题目,进行了“阅卷式”的范式改造,生成的新数据集更难、更有区分度,更能真实地反映模型推理能力!
不用重新找题出卷,也不用把题目变形来测试模型的鲁棒性,MR-Ben直接让模型从“答题者”变成“阅卷者”,对数据集中已有的答题过程进行评判,通过让大模型当老师来测试它对知识点的掌握情况!
具体来说,贾佳亚团队针对市面上主流的评测数据集GSM8K、MMLU、LogiQA、MHPP等数据集进行整理,并分成了数理化生、代码、逻辑、医药等多个类别,同时区分了不同的难度等级。
针对每个类别、收集到的每个问题,团队精心收集了对应的分步解题过程,并经由专业的硕博标注者进行培训和标注。
标注过程中,解题过程是否正确、出错的位置、出错的原因都会被细致指出,比对大模型的阅卷结果和人类专家的阅卷结果,就能知道模型对知识点的掌握情况。
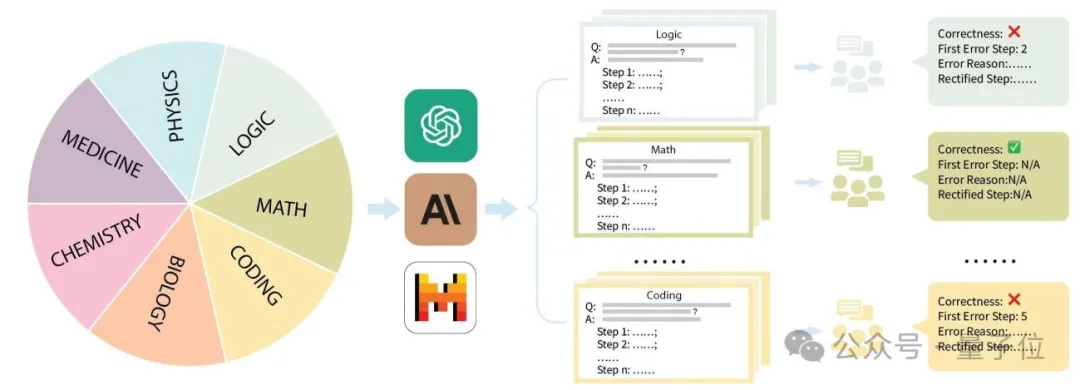
从评测方式来看,MR-Ben所提出的方法,需要模型对于解题过程的每一个步骤的前提、假设、逻辑都进行细致分析,并对推理过程进行预演来判断当前步骤是否能导向正确答案。
这种“阅卷”式的评测方式从难度上远超于仅答题的评测方式,但可有效避免模型背题所导致的分数虚高问题。而只会背题的学生很难成为一名合格的阅卷老师。
GPT4-Turbo表现最佳
贾佳亚团队针对目前几款知名的大模型进行了评测,部分模型有多个版本参与测试。
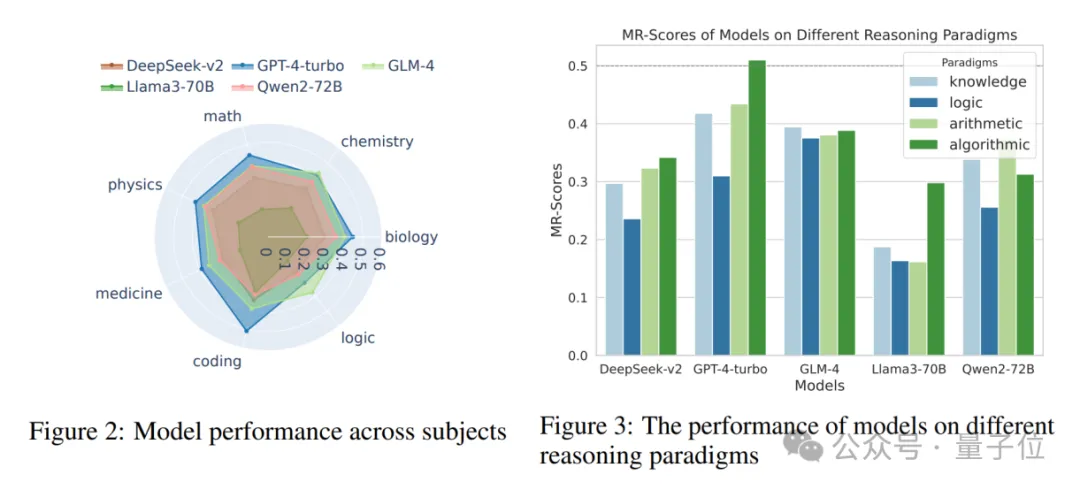
可以看到,闭源模型中,GPT4-Turbo的表现最佳(虽然在“阅卷”时未能发现计算错误),在绝大部分的科目里,有demo(k=1)和无demo(k=0)的设置下都领先于其他模型。
智谱团队的GLM模型表现在榜单中位列第二,超过了Claude最新的3.5-Sonnet。
不过不同模型间的区分度较大,最强的GPT4-Turbo在MR-Ben数据集上获得的成绩也不到50分,可以看出其表现仍未饱和。
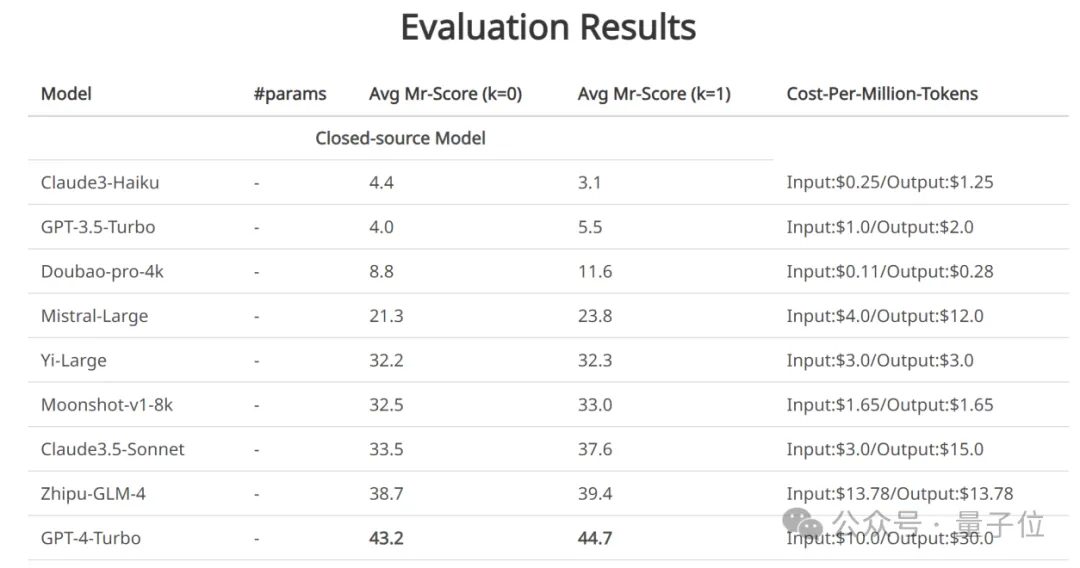
另外,一些表现较强的开源模型,效果已经赶上了部分商用模型。
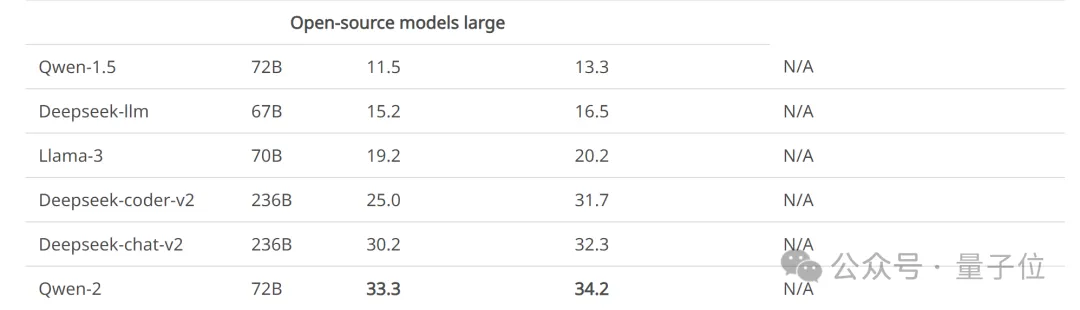
除此之外,MR-Ben团队在工作过程中还发现了一些有意思的现象,例如:
- 低资源场景下,小模型也有不少亮点,MR-Ben评测中Phi-3-mini在一众小模型里脱颖而出,甚至高于或持平几百亿参数的大模型,展现出了微调数据的重要性。
- MR-Ben场景包含复杂的逻辑解析和逐步推断,Few-shot模式下过长的上下文反而会使得模型困惑,造成水平下降的后果。
- MR-Ben评测了不少生成-反思-重生成的消融实验,查看不同提示策略的差异,发现对低水平的模型没有效果,对高水平的模型如GPT4-Turbo效果也不明显。反而对中间水平的模型因为总把错的改对,对的改错,效果反而略有提升。
- 将MR-Ben评测的科目粗略划分成知识型、逻辑型、计算型、算法型后,不同的模型在不同的推理类型上各有优劣。
贾佳亚团队已在github上传一键评测的方式,测试一次消耗的token量大约为12M,开发者可以在自家的模型上评测并提交,MR-Ben团队会及时更新相应的leaderboard。
论文地址:
https://arxiv.org/abs/2406.13975
项目主页:
https://randolph-zeng.github.io/Mr-Ben.github.io/
Github Repo:
https://github.com/dvlab-research/Mr-Ben
- “史上最快闪存技术”登Nature!复旦新成果突破闪存速度理论极限,每秒执行操作2500000000次2025-04-23
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23
- 装满智能体AI的手机,正在呼唤一个“Type-C时刻”2025-04-16
- 最强视觉生成模型获马斯克连夜关注,吉卜力风格转绘不再需要GPT了2025-04-17





