视频上下文学习!大模型学会“照猫画虎”生成,结合模拟器还能精准控制真实环境交互,来自MSRA
模型与现实世界的交互变得更多样
Vid-ICL团队 投稿
量子位 | 公众号 QbitAI
视频生成也能参考“上下文”?!
MSRA提出视频上下文学习(Video In-Context Learning, Vid-ICL),让大模型学会“照猫画虎”式模仿生成。
Vid-ICL通过一段示例视频来指导模型在新场景下的生成,使得生成结果可以在新场景下“模仿”示例视频中完成的任务。
比如,示例视频镜头视角向下移动(左),生成视频同样视角向下移动(右):

示例视频物体向上移动(左),生成视频同样向上移动(右):

物体抓取也能模仿:

△左:示例视频,机械臂抓取物体;右:生成视频
打开抽屉也可以按示例进行:

△左:示例视频,打开中间的抽屉;右:生成视频
在相同的电风扇场景下,用不同示例视频指导模型生成效果belike:

△左:示例视频,镜头左移;右:生成视频

△左:示例视频,镜头右移;右:生成视频
要知道,在一个理想的世界模型中,模型与外界环境的交互应当是多样的。而大部分现有工作都聚焦在用文本作为主要的交互方式,这使得对生成结果细节和多样性的控制变得困难。
而视频是高度具象且通用的,能够传递广泛的信息如完成各种任务的示例,包括移动或抓取对象等。
研究团队提出的Vid-ICL方法提供了语言和图像之外的一个新的接口,使模型与现实世界的交互变得更为多样。

除了上面展示的生成视频之外,Vid-ICL也可以与模拟器结合,用生成视频和当前状态来预测与环境正确交互的相应动作,从而实现与真实环境的交互。
下图中展示了Vid-ICL与真实环境交互,从t=0时的状态开始,与RoboDesk模拟器交互完成“Push_red”任务。Vid-ICL对环境交互提供了更精确的控制:

好家伙,电影《铁甲钢拳》照进现实了。
Vid-ICL究竟是如何做到的?
Vid-ICL框架解读
Vid-ICL以视频为基本单元进行运作。
具体而言,给定一个查询视频片段和k个示例视频片段,Vid-ICL的目标是生成一个视频片段,该视频片段应首先保持与查询视频片段在感知上的连贯性,同时在语义(如镜头移动、动作)上与示例视频一致。
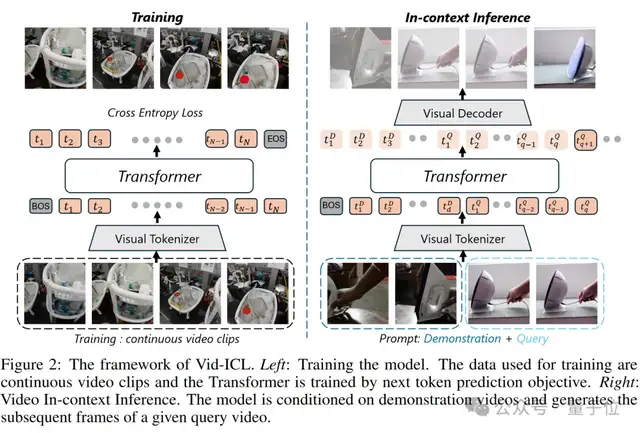
- 自回归模型训练
Vid-ICL采用Transformer作为模型结构。
Transformer作为文本大模型的基座架构,在语言的上下文推理、生成任务上展现了强大的能力。视觉信息的生成式Transformer训练包括两个阶段:
第一,训练视觉编码器,如 VQ-VAE,将每个图像转换为离散Token;
第二,每个训练样本被构建为Token序列,Transformer解码器的目标是恢复该Token序列。
具体实现上,Vid-ICL采用Llama架构,利用RMSNorm归一化和旋转位置嵌入(RoPE),以自回归方式训练 Transformer解码器。在训练阶段,每个序列是从一个原始视频中采样的,没有拼接来自不同视频的视频片段。
- 零样本能力
研究团队在本文中提到一个关键的观察:
模型可以从没有显式上下文形式的视频数据,即连续视频片段中自发地学习出上下文推理能力,即对于Video In-context Learning的“零样本能力”。
这可以归因于两个关键因素。首先,每个视频帧之间没有插入特殊的分隔符,这允许模型在训练期间,将连续的视频序列隐式地视为示例视频+查询视频的格式。这意味着模型已经学会了处理类似示例-查询结构的序列。
其次,Transformer的自回归特性使其能够将单一场景的视频序列预测能力拓展到示例和query来自不同视频的场景,将文本上下文学习的范式无缝地泛化到视频上下文学习上。
- 融合其他模态
虽然Vid-ICL主要关注视频作为示例,但是可以扩展到其他模态如文本上。
为此,只需通过预训练的语言模型将原始文本描述转换为潜在表示,然后在训练Transformer以及进行上下文推理时将该潜在表示作为前缀,通过投影层对齐到Transformer的隐空间内。
实验表明,Vid-ICL可以同时接收文本和视频作为示例,并且加入文本可以进一步增强生成结果的质量。
- 数据与模型大小
可以看到,Vid-ICL可以学习到示例视频中包含的语义信息,并迁移到新的场景上进行生成,这要求训练数据中主要包含的是因果关系清晰、交互性强的视频。
因此,研究人员选择了两个数据集作为主要训练数据源: Ego4d和Kinetics-600。
此外,为了增加视频内容的多样性,一小部分Webvid中的数据也加入到训练集中。
团队还验证了受限于互联网视频中包含的语义信息较为模糊和发散,简单地通过添加更多的互联网视频来增加数据规模并不能帮助提高模型的上下文性能。
模型大小上,团队训练了300M,700M和1.1B三种大小的模型,并且发现模型生成视频的质量和上下文性能都遵循了Scaling Law。
实验结果
Vid-ICL主要通过对一条相同的查询视频提供不同语义的示例视频,来评估视频上下文学习的有效性和精确性。
例如,对一个将物体向左移的查询视频,通过给向左移、随机移动、向相反方向移动的示例视频来生成不同的视频,对该生成结果的评测来判断模型是否真的生成了示例相关的视频。
定性结果方面,下图中给出了不同示例视频下的生成视频(更多样例可参照论文原文)。
可以观察到:
1)对于单个视频生成的质量,Vid-ICL保持了生成视频与查询视频的连贯性,且都有不错的生成质量;
2)对于生成视频和示例视频的语义一致性,可以观察到生成的视频都跟随了示例视频的过程,这表明Vid-ICL有自发获取示例视频语义信息并生成相应视频的能力。
如下图中,对同一个查询视频片段,Vid-ICL根据示例视频中镜头的移动,选择对生成视频进行相应的移动。

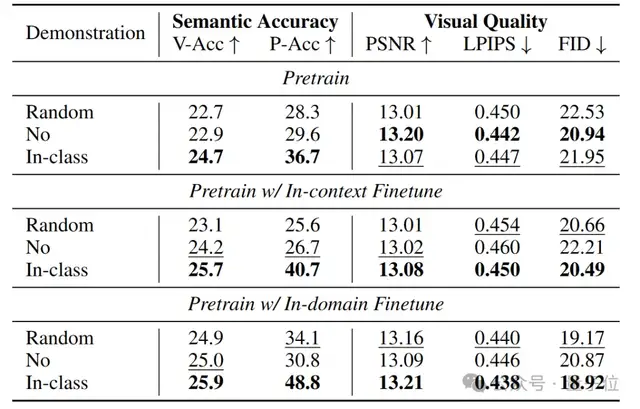
定量结果方面,研究团队提出了两个方面的自动评测指标:
1)视频质量上,采用传统视觉任务上基于像素匹配或分布的指标,如PSNR,FID等;
2)语义一致性上,采用基于分类准确率的两个指标:视频分类准确率和探针分类准确率。
在不同的指标上,Vid-ICL均表现出了超出基准模型的效果。可以看出,在同类示例视频的引导下,Vid-ICL均生成了更加真实、语义一致的视频。
更多细节请参考原论文。
项目主页:https://aka.ms/vid-icl
论文链接:https://arxiv.org/abs/2407.0735
- 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品2025-04-14
- 4090玩转大场景几何重建,RGB渲染和几何精度达SOTA|上海AI Lab&西工大新研究2025-04-13
- 阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent2025-04-09
- 又一上海人形机器人加入开源!全套图纸+代码,来自傅利叶2025-04-11