Mamba写代码真的超越Transformer!原始论文入选顶流新会议
Mistral AI和Mamba强强联合
西风 发自 凹非寺
量子位 | 公众号 QbitAI
“欧洲OpenAI”和“Transformer挑战者”强强联合了!
Mistral AI刚刚推出了其第一个基于Mamba2架构的开源模型——Codestral Mamba(7B),专搞代码生成。

与Transformer架构不同,Mamba架构可进行“线性时间推理”,理论上能够支持无限长度输入。
Mistral AI:这也就是为啥我们用Mamba架构推出的代码推理模型抗打。

Mistral AI表示已经在最多256k token上下文中测试了Codestral Mamba。
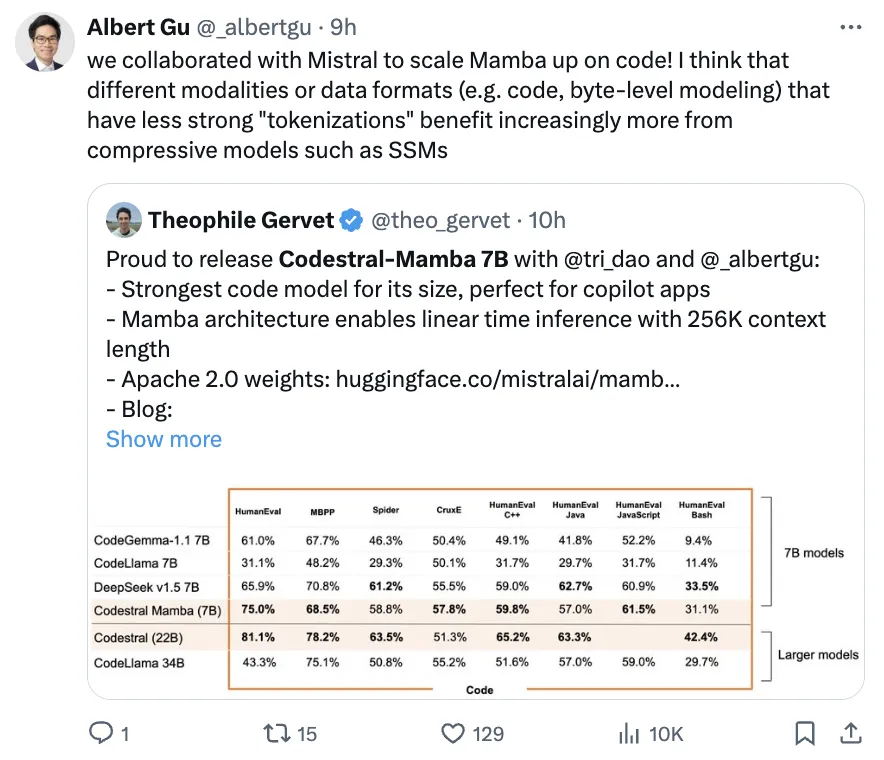
基准测试中,Codestral Mamba总体性能超越CodeGemma-1.1 7B、CodeLlama 7B、DeepSeek v1.5 7B、CodeLlama 34B。
有网友表示,这一波是Mistral AI要带飞Mamba架构的节奏。
Mamba架构作者之一、CMU助理教授Albert Gu表示:
具有较弱“tokenizations”的不同模态或数据格式(例如代码、byte级建模)会越来越多地从压缩模型(如SSM)中受益。
除了Codestral Mamba,Mistral AI这次还同时发布了一个新的数学模型——Mathstral(7B)。
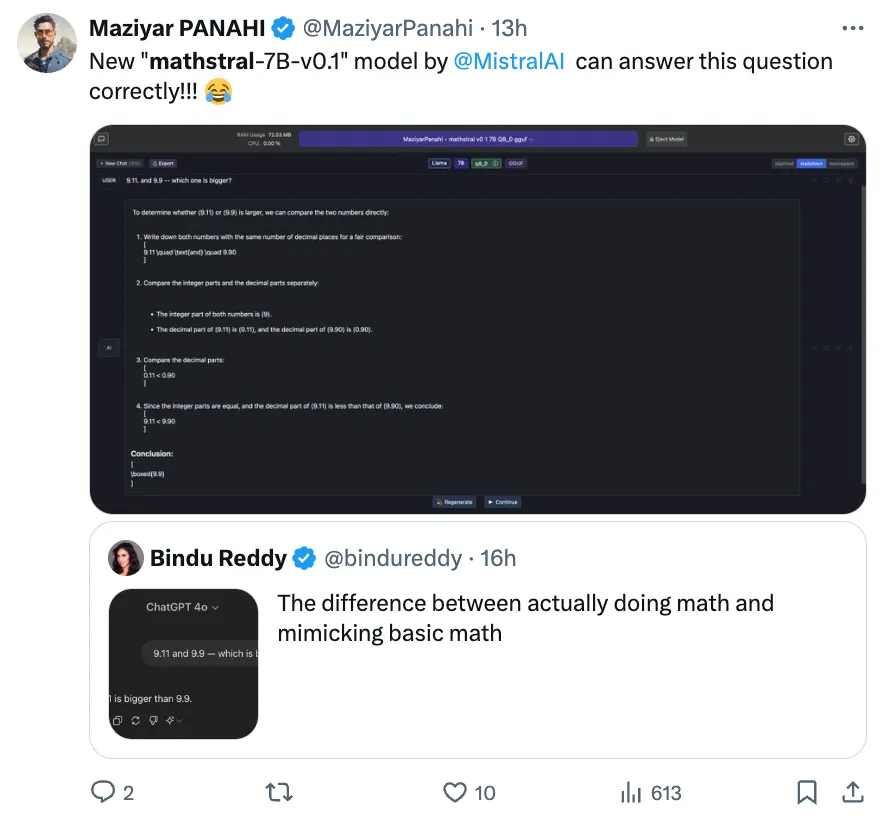
有意思的是,网友让它做这几天大模型频频翻车的“9.11和9.9哪个大”的问题,Mathstral先比较整数,然后再比较小数部分,最后成功做对。
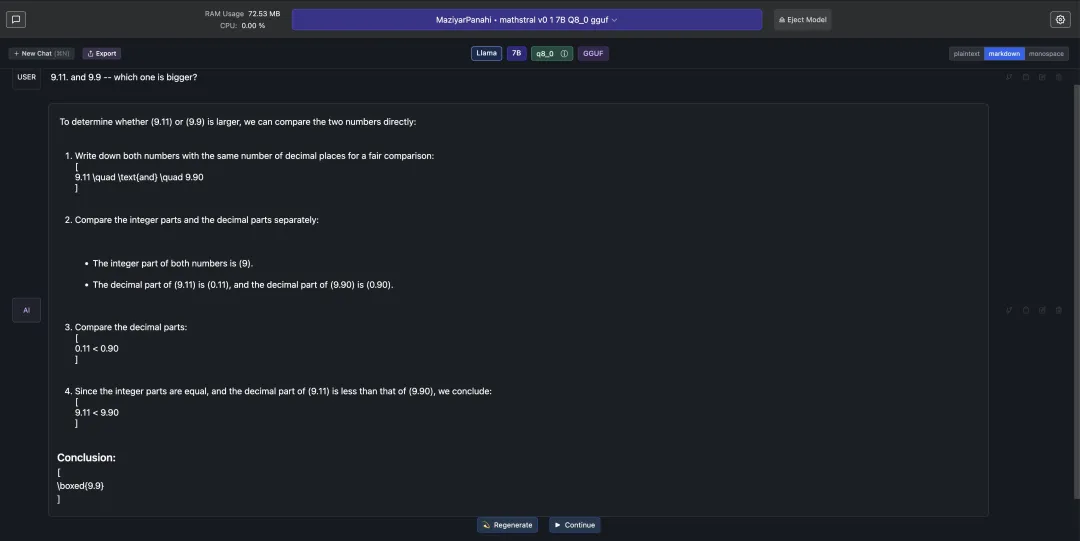
7B性能接近22BTransformer
Codestral Mamba完整基准测试结果如下:
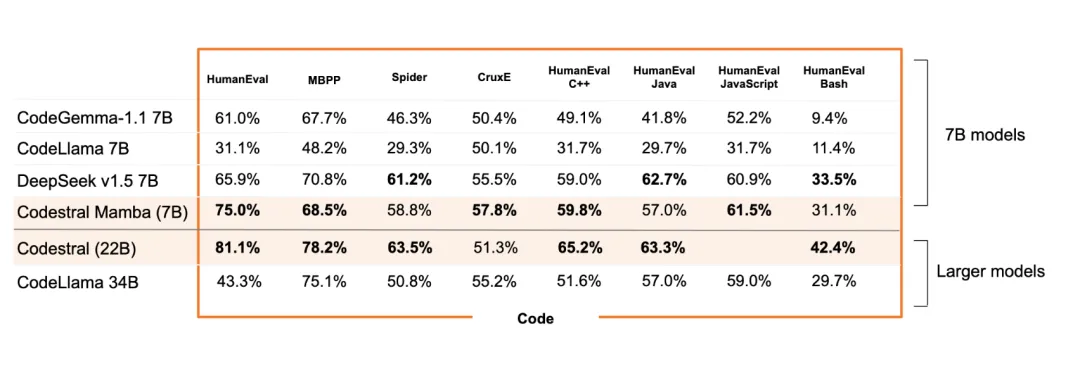
在HumanEval C++/Java/JavaScript/Bash等所有基准上,Codestral Mamba全面超越CodeGemma-1.1 7B、CodeLlama 7B,且超越比它更大的CodeLlama 34B。
Mistral AI此前自家的最强开源编程模型Codestral 22B也没有和Codestral Mamba拉开太大差距。
除此外,DeepSeek v1.5 7B在基准中也比较突出,和Codestral Mamba打得有来有回。
DeepSeek v1.5 7B在Spider(复杂跨域语义分析和文本到SQL任务)、HumanEval Java、HumanEval Bash、MBPP等方面优于Codestral Mamba。
除了基准测试结果,Codestral Mamba最令人关注的当属它是首批Mamba2架构模型。
Mamba架构由FlashAttention作者Tri Dao和CMU助理教授、Cartesia AI联合创始人及首席科学家Albert Gu在去年年底提出。

此前,ChatGPT等Transformer架构大模型有一大痛点:处理长文本算力消耗巨大。其背后也是因为Transformer架构中注意力机制的二次复杂度。
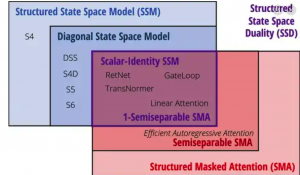
而Mamba是第一个真正实现匹配Transformer性能的线性时间序列模型,也是一种状态空间模型(SSM,State Space Model)。
Mamba建立在更现代的适用于深度学习的结构化SSM(S4, Structured SSM)基础上,与经典架构RNN有相似之处。
主要有三点创新:对输入信息有选择性处理、硬件感知的算法、更简单的架构。
Mamba架构一问世就引起了圈内广泛关注。Stability AI创始人、英伟达科学家Jim Fan等都对它的出现感到兴奋。


Mamba初代论文年初被ICLR拒稿,当时在圈内引起热议。
不过,最近已经被新生代顶流会议CoLM2024接收了。
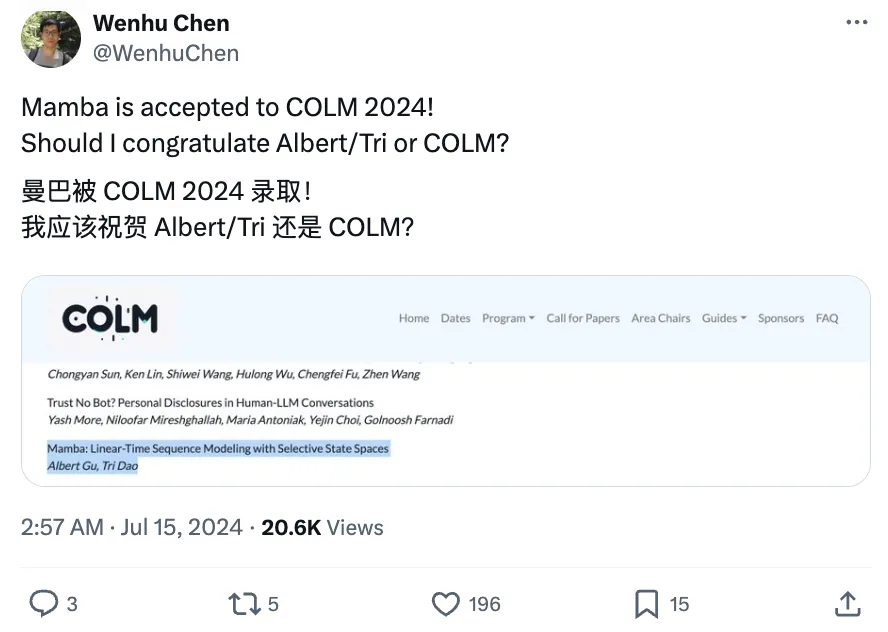
Mamba2是其二代,状态空间扩大8倍,训练速度提高50%。
Mamba2论文中更是发现,Transformer中的注意力机制与SSM存在着非常紧密的数学联系,论文成功入选ICML 2024。

还发布了一个数学模型
除了Codestral Mamba,Mistral AI还同时推出了一个开源数学模型——Mathstral(7B),作为对阿基米德诞生2311周年的纪念。
Mathstral在Mistral 7B基础之上,专注于STEM(科学、技术、工程、数学),上下文窗口32k。
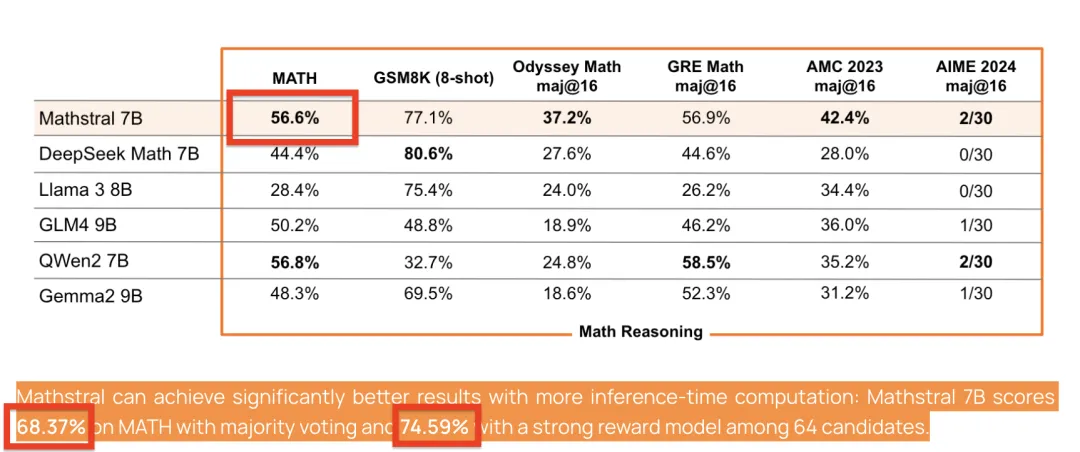
在基准测试中,Mathstral MATH得分56.6%,MMLU达到了63.47%。
重点是,Mathstral还可以通过更多的推理时间计算获得更好的结果:
使用多数投票机制时,Mathstral 7B在MATH测试中的得分为68.37%,而在64个候选模型中应用一个强效奖励模型时,得分能够提升到74.59%。
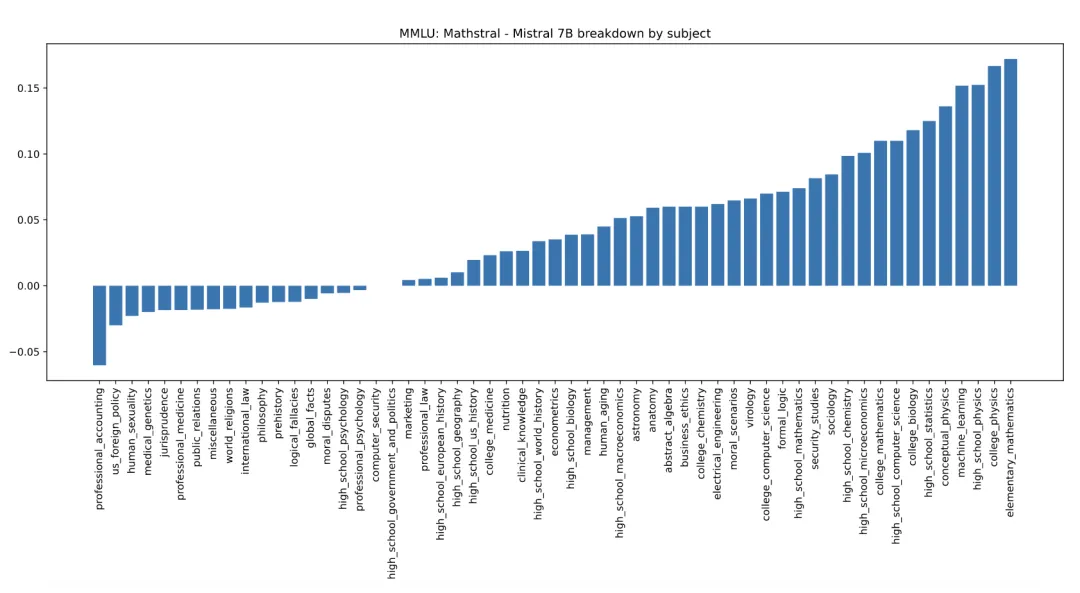
以下是Mathstral 7B和Mistral 7B在MMLU各科目中的表现差异:
参考链接:
[1]https://mistral.ai/news/codestral-mamba/
[2]https://mistral.ai/news/mathstral/
[3]https://x.com/MistralAI/status/1813222156265791531
[4]https://x.com/GuillaumeLample/status/1813231491154899012
[5]https://x.com/theo_gervet/status/1813226968600469824
[6]https://x.com/tuturetom/status/1813238885453033540
[7]https://x.com/WenhuChen/status/1812562112524226569
- 阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent2025-04-09
- 周光:VLA模型将成智能驾驶体验颠覆性拐点2025-03-31
- 摸DeepSeek过河也得自身硬! 想开后的文小言,真香!2025-03-31
- 7B模型搞定AI视频通话,阿里最新开源炸场,看听说写全模态打通,开发者企业免费商用2025-03-27