明年,每个人都能零基础创作3D内容 | 对话VAST宋亚宸
「365行AI落地方案」直播回顾
视点 发自 凹非寺
量子位|公众号 QbitAI
大家对生成视觉领域有着这样的认知:先有图像生成、视频生成,再有3D生成。
图像生成的DALL·E、Midjourney,视频生成的Sora、可灵都已经有了惊艳的表现。实际上3D生成发展也并不落后。
早在去年年底VAST就推出了AI 3D大模型Tripo。今年3月,VAST与Stability共同发布了能0.5秒图生3D的开源模型TripoSR。
量子位「365行AI落地方案」邀请到了VAST CEO宋亚宸为我们介绍3D大模型的落地进展,以及对发展前景的思考。
在宋亚宸看来,做3D大模型是先做「手机摄像头」,再做3D内容平台即「3D抖音」。对于在3D生成领域众望所归的VAST而言,已经有了充足势能从技术、产品,做到内容平台。
宋亚宸也反复强调作为创业公司,最重要的壁垒其实是初心。三个月后,我们会看到VAST带来3D大模型用户体验的拐点吗?让我们拭目以待。

以下根据分享实录整理成文,在不改变原意基础上有所删减
VAST是一家做3D大模型的公司。什么叫3D大模型呢?
3D大模型的主要交互方式是通过文字或者图片生成3D模型,这个生成的3D模型的表达方式是带贴图材质的Mesh,可以在很多传统的3D管线中得到应用,比如动画、游戏、3D打印、工业设计、数字孪生、仿真模拟等等。
VAST的大模型产品已经上线了,叫做Tripo,已经可以在Discord或Web中使用。包括静态3D模型的生成、骨骼自动绑定、动作生成、3D风格化,及各种格式的导出和转换,都可以在tripo3d.ai中体验。
再过三个月,会是3D大模型用户体验的拐点
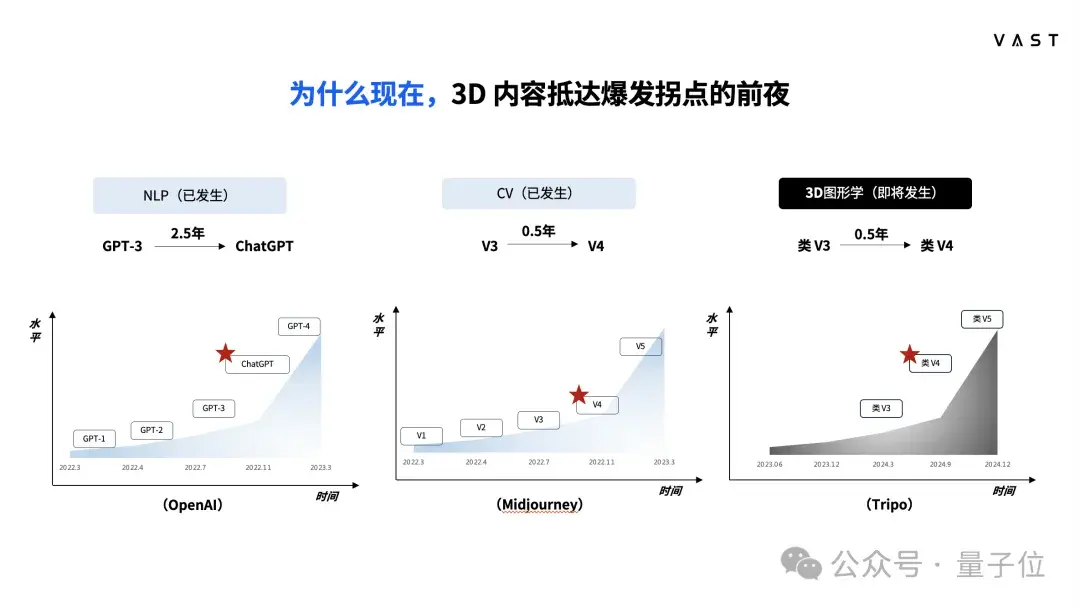
大家可能对语言大模型像ChatGPT,或是文生图大模型像Midjourney更熟悉,那么3D大模型和他们有什么区别,又在什么样的发展节点上呢?
3D大模型与图形学的关系很大,过去图形学和AI的结合并不多,直到最近一些新的3D表达方式出现,让3D模型可以更好地被作为AI大模型训练的数据。
现在是2024年6月,3D大模型的成熟度已经超越了类似于GPT3或者Midjourney V3的水平。再过三个月2024年9月,我们相信它可以达到GPT3.5或是Midjoueney V4的水平,也就是用户体验的拐点。
所以当我们去讨论商业化、包括产品功能的时候,我们首先应该认识到现在的技术还不是完全成熟的技术,很多商业化场景还不能直接使用现在生成的3D模型。因此,随着近期3D生成大模型的快速迭代和演进,技术的落地场景会更加广泛,商业化潜力也会更大。
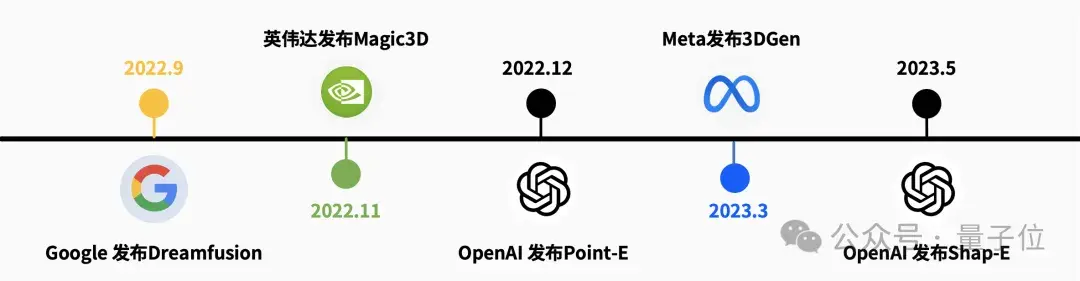
当然除了我们,谷歌、英伟达、OpenAI、Meta、Adobe等大厂也纷纷布局了3D生成赛道。但是过去3D生成其实一直都存在问题。
首先是技术路线不清晰,其次是训练数据集稀缺,公开数据集少,而且开源数据集数量和质量都较差。不管创业公司还是大厂、研究院都没有足够数据来训练。最后是生成成本高,需要大量GPU进行训练和推理。
我们一一解决了这三点问题。第一,是在学术上统一了技术路线,第二,是收集了大量的3D原生的、高质量数据集,目前在2000多万的级别,可以说是全球第一。第三,是生成成本,因为算法工程团队的极致优化,每个模型的生成成本几乎接近于零。
我们在技术、数据的优势都离不开优秀的算法团队。去年,我们6投6中CVPR,同时其他几篇论文也被Siggraph、ICLR、ECCV等学术顶会所接收。我们也进行了不少开源项目的尝试。今年3月,与Stability AI合作推出了TripoSR(GitHub 4K stars),是最大、最好、最快的3D生成大模型。还有ThreeStudio(GitHub 5.9K stars)、Wonder3D(GitHub 4.5K stars)、TGS、CSD等等受到行业瞩目的高质量开源项目。
在技术上我们主要有三点优势。第一点,是我们生成的结果精度高,泛化性强。我们生成3D模型的几何、布线、材质、纹理非常优秀,在复杂的组合模型的泛化性上表现也很好,比如生成骑在乌龟背上的绿色大象等等。
第二点,是我们对于生成过程有非常强的可控性,不管是在文生的正负向提示词上还是在图生的高度还原上,我们都可以保持本身风格的一致性,这在商业化管线中意义重大。
第三点,是我们生成的不只是静态的虚拟资产,还包括物体的动态表达,比如自动骨骼绑定及动作生成。我们希望未来能够生成更丰富的3D内容模态,不断降低3D内容的创作门槛。
我们通过两方面不断积累技术优势。一方面,是我们认为3D的表达方式很关键,我们投入了大量的时间和技术来研究最适合大模型训练的表达方式,需要使tokenizer达到最高的压缩率、保真率、还原率等等特征。
另一方面,是产品上线以来,Tripo3d.ai获得了业界的广泛关注。现在海外有数十万开发者在使用Tripo进行创作,与数百家客户紧密合作,目前已生成超过400万个3D模型,这些用户和客户的真实反馈给我们迭代技术提供了大量的human feedback,形成了数据的飞轮。
希望明年,让每个人零基础也能创作3D内容
那么VAST最终想要做什么呢?我们希望在明年,能够让每个人都有能力创作完整的3D内容。即使完全不会使用专业3D建模工具的创作者,也能够通过描述可控地、低成本地生成完整的3D内容。
文字、图片、视频、声音等各种信息载体,都已经有了属于自己品类的大众内容平台了,比如说文字信息的Twitter,图片的Instagram,视频的TikTok,音乐的Spotify等。
但是对于3D内容,目前还未出现大众级别的内容平台,而大众内容平台的商业化价值是被无数次验证的,市场的空间非常大。
我们认为现在还没有出现3D大众内容平台的原因是,3D缺乏一个大众级别的创作者工具,可以理解为我们缺乏一个3D品类的“手机摄像头”。在这样的大众工具出现之前,3D的创作成本和门槛过高,很难出现一个大众内容平台。所以所谓3D大模型,可以理解为创作3D内容的“手机摄像头”。
就像是昨晚做了一个梦,我醒来后想要把梦境创造出来,让朋友来我的梦境里去玩、去体验。现在听起来还很天方夜谭,但当3D大模型达到V4、V5水平时,就有了这样的机会。
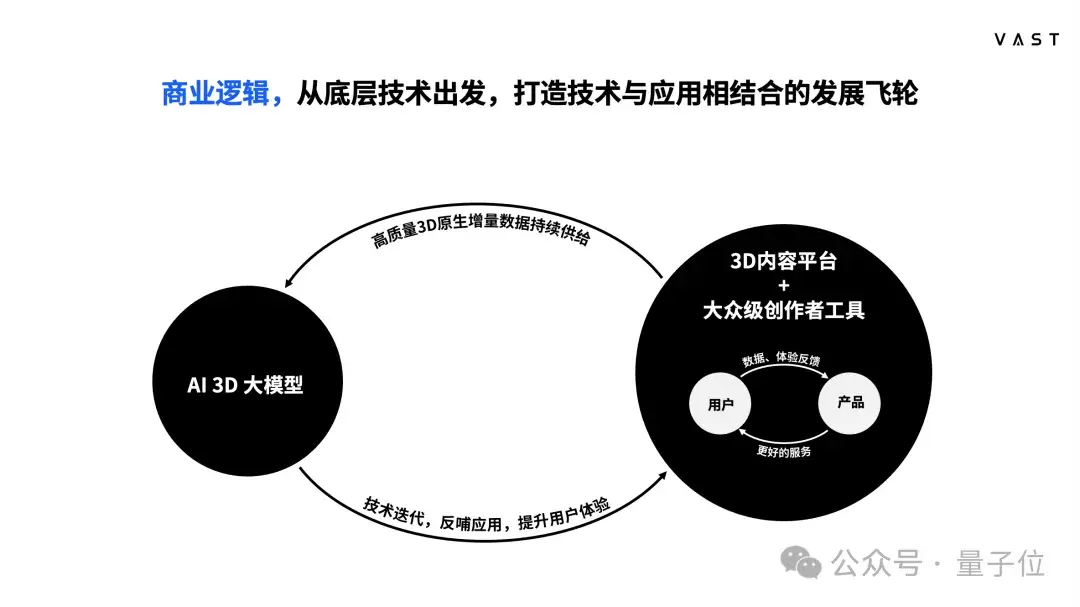
当大众级别的创作工具出现后,我们认为内容平台才会有机会诞生。那么紧接着就会是3D内容,也可以说是虚拟内容的大爆发。
随着更多人使用Tripo这样大众级别的创作工具,和3D内容平台,自然就会有更多3D原生数据来训练3D大模型,促进技术的进一步迭代。同样的,技术也会反哺应用,进一步提升用户体验,形成数据的闭环。
先把技术能力商业化
Tripo Web工具是我们的一大亮点,它通过会员订阅和API接口为个人和企业提供服务。3D艺术家、游戏建模师、独立开发者等个人用户可以通过订阅获得强大的建模工具。对于企业客户,我们不仅提供API接口,还提供定制化的专业解决方案。
海外市场是我们重要的增长点。目前,我们在海外已经拥有数十万开发者。
在游戏解决方案方面,我们与国内外众多知名游戏公司、游戏编辑器和游戏引擎建立了官方合作。我们的技术主要应用于游戏前期概念设计阶段,帮助团队快速生成角色、场景、载具等3D资产,激发创意灵感。在游戏制作过程中,我们的技术也能用于生成中远景美术资产,还可以提供中模帮助主美与外包团队进行高效沟通。
除了提供降本增效的服务,我们也在探索将3D生成技术融入游戏玩法。
我们的开发者社区创造了TripoGo这款游戏,玩家通过生成3D模型进行对战,胜利者可以获取对方的prompt进行进化生成。这种玩法类似于小时候玩的数码暴龙机,但3D生成技术赋予了它全新的乐趣。TripoGo通过社交媒体传播,一周内就吸引了超过10万海外用户。

我们还与小型游戏开发团队和工作室合作,尝试开发各种AI游戏。
此外,我们还举办了全球首届AI 3D渲染大赛Behind the Scenes。我自己也参与了比赛,虽然我完全不会建模和动画,但借助Tripo的AI生成能力,我只用了半天时间就制作出了参赛作品,还获得了入围奖。
VASTAI
,赞124
这场比赛共收到两三百份作品,全部都是使用Tripo AI生成的。优秀作品的特点是,在给定固定机位和场景的前提下,利用Tripo生成模型和动画。这充分展示了AI技术如何帮助虚拟内容创作者,即使零基础也能高效地制作出令人惊艳的作品。
此外,一些教育或小游戏开发者也在利用Tripo的能力开发生成式决策系统。XR也是一个重要的应用场景,Tripo目前已上架Vision Pro应用商店。
3D生成技术对于3D打印行业同样意义重大。由于会建模的用户量很小,3D打印(尤其是家用3D打印)的发展一直受到限制。但随着3D生成技术的进步,即使不会建模,人们也可以通过文字或图片生成所需的模型,并将其打印出来。
我自己就尝试过将照片上传到Tripo,生成卡通形象,然后通过3D打印制作成我自己的定制化玩具手办。
家具、鞋服、灯具、首饰等行业也可以利用3D生成技术进行设计和模拟。针对每个场景,我们都提供专门的定制化解决方案。例如,灯具模型需要中空,预留放置灯泡的空间,并能模拟点亮效果。
目前,VAST在海内外都享有良好声誉,并在SIGGRAPH、CVPR等顶级会议上发表了多篇论文。Tripo也入选了A16Z的AIGC产业地图。最后是我们公司的Slogan——为世界增文明,为人类造幸福。
Q&A
先有「手机摄像头」才会有「抖音」
Q:大家谈到大模型产品时,常会提到ROI(投资回报率)。VAST在这方面是怎么看的?
VAST宋亚宸:3D生成的ROI可能会超出大家的预期。视频、图像或文字生成都面临推理成本高的问题,但3D生成成本相对较低,因此我们的产品在销售时ROI更容易实现。
例如,我们与Stability合作开发的开源3D大模型TripoSR,在CPU上只需0.5秒就能生成一个3D模型,算力成本很低。对我们来说,更大的挑战在于数据而非算力。
Q:视觉生成模型通常按技术难度分为图像、视频、3D三个阶段。您怎么看这种划分?
VAST宋亚宸:我认为3D生成的技术成熟度并不比视频生成差,欢迎大家亲自体验tripo3d.ai。视频生成本身还存在3D一致性等问题。
Luma原本专注于3D生成技术,曾是我们最大的竞争对手,现在转向视频,反而在视频生成赛道取得很大优势。
我观察到,文字、图片、声音、视频等与3D生成有本质区别。前者早已有低成本、低门槛的制作方式,AI只是众多选项之一。而3D内容过去是大众无法制作的,3D生成技术拓展了人类能力的边界,实现了从0到1的突破。
在Sketchfab等模型网站上,3D模型平均价格在40美元左右,质量高一些的模型甚至价格高达几百美元,这说明3D生成有很大的商业潜力。
而且,3D内容的消费市场已经成熟。全球最赚钱的游戏大多是3D的,如原神、王者荣耀、黑神话悟空等。早在2012年,3D和2.5D手游就占了87%的比例。2024年的今天,3D在游戏领域已是一个巨大的市场。
随着3D大模型降低了创作3D内容的门槛,未来每个人都可以创作3D内容。大家说Vision Pro、XR眼镜现在买回来也吃灰,我认为不是硬件的问题,而是缺乏好的内容。像小时候在MP3上看几百万字的小说,几百万字的斗罗大陆、斗破苍穹都可以用MP3看——只要有好的内容,多差的硬件也一定会有人来使用。
你可以用MP3来看500万字的小说,但你说Vision Pro不能支持你去玩一段时间,核心的点是在于没有好的内容,用户的创作门槛和成本太高了。如果有哪一天创造一个3D内容,成本几乎为0而且不需要任何专业技能,那大众都会去创作3D内容,用3D去交流、交互、表达、分享、创作、创造、实现等等。
Q:那您觉得,您刚刚描述的这样一个世界,什么时候可以到来呢?就像这样每个人都可以在3D世界中创作?
VAST宋亚宸:我们认为大众级创作工具的成熟是第一步,就像手机摄像头是抖音出现的前提。我们正在研发类似手机摄像头的3D大模型,预计今年年底能达到不错的效果。
一开始我们迭代模型,很多人评论这个布线和PBR等等,这其实不是最关键的。关键的是普罗大众第一次可以去这样创作3D模型或者3D内容,这件事情本身就是跨时代的。
今年年底,我们的大模型将达到3D建模初学者水平;明年,我们认为它将超越有3年工作经验的建模师,达到至少Midjourney V5或V6的水平。
但是我们也得承认,不是手机摄像头诞生了,就一定会出现抖音,也不是说做手机摄像头的厂商就能做出抖音这样的内容平台。所以我们在说不是一定有了大众级别的创作工具,就一定会诞生内容平台。
在没有手机摄像头之前,就已经有大量公司在尝试做内容平台了,甚至Facebook都改名为Meta,说要实现元宇宙,也就是3D内容平台。为什么大家那个时候说,这些人说做元宇宙是骗子吗?其实不是,他们只是卡在了没有摄像头。
我们既在做大众级创作工具,又在3D大模型技术上领先,因此有足够的时间窗口和技术优势去做内容平台。无论是积累的内容创作者社区、海外开发者生态,还是3D大模型技术和创作者们创作的3D内容,我们在打造“3D抖音”方面都有一定的先发优势。
创业公司的高壁垒,在于初心
Q:您把3D内容平台比作3D抖音,很有意思。您提到有足够的时间窗口,但通常大家认为初创公司做通用大模型很难,在3D生成领域是不是也有类似挑战?目前市场和时间窗口情况如何?
VAST宋亚宸:3D生成赛道非常独特。举几个例子大家就明白了。首先,语言、图片、音乐、声音、视频等多模态领域,基本都被海外公司领先,我们处于追赶状态。但3D生成不同,我们的水平是全球顶尖的。
为什么会有这样的差异?关键在于3D生成核心是AI和图形学的结合,才能诞生可扩展的3D大模型。3D大模型作为一个新兴领域,人才稀缺。当顶尖人才聚集在一起,就会形成人才黑洞,因为最好的人都在同一个团队,都想做同一件事。相比之下,大厂砸钱挖人,但挖来的人未必是最好的。
其次,3D生成所需的训练算力与语言模型不同。语言模型可能需要越多算力越好,因此需要大量融资。但3D生成不是这样,算力并非越多越好。即使有数十万张卡,可以做很多实验,但不代表算法就能领先。
其三,我认为我们这样的AI 2.0公司不应该被小觑。AI 2.0公司非常专注,而大厂如英伟达、Meta、腾讯等,投入到这件事的人力、财力、算力都不如我们。因为我们只做这一件事,而他们要做很多事,他们之前可能更擅长发论文、做研究。但现在,我们的研究已经比他们做得更好了。
此外,我们在3D生成这个垂直赛道的资源其实比大厂更多。举个例子,英伟达很早就说要在LATTE 3D模型上打造“皮克斯”,疯狂放demo,把我们吓得够呛。但结果出来可能就是没人用,效果也很一般,与宣传相差甚远。这让我们对大厂或所谓的竞争对手祛魅了。
最近Meta出了新版本的3D Gen,我们也发现其实即使是Meta出了报告,我们也在其中有非常不错的表现。
当大家提起3D就想到VAST,或者说AI 3D就想到Tripo时,我们在这件事上已经积累了足够的基础,这种势能让我们无所畏惧。
Q:看来3D生成的壁垒确实很高?
VAST宋亚宸:是的,可以说已经有很多壁垒了。我们在数据量上远超同行,人才方面也形成了黑洞。市场调研显示,我们的3D建模工具在用户量和口碑方面都遥遥领先其他产品。
但我觉得这些都不是本质。对于创业公司来说,最本质的壁垒是初心和使命,也就是到底想做什么。
就像OpenAI推出Sora时,大家担心他们要做世界模拟器,觉得这个概念很厉害,会影响我们的计划。但我想的是,OpenAI的初心是什么?我的初心又是什么?如果初心一样,那他们确实有钱、人才也多;然而关键是我们想做的事情不一样。
别人也会把我们和一些大厂、教授创办的公司比较。我就会说,第一,他们玩不玩游戏?真的想不想进入虚拟世界?如果让他们天天不上班,在家戴着XR眼镜打游戏,他们愿不愿意?如果待一个月就会疯,那对不起,他们就和我们有本质的不同。
这也是为什么我们看到这个赛道上的很多“竞争对手”都在做其他事情了,甚至连Luma也去做视频了。
Q:您觉得现在VAST是处于从0到1的阶段,还是1到100的阶段?
VAST宋亚宸:我们肯定是刚刚起步。虽然产品和业务层面看起来比较顺利,但公司成立才一年多,还很年轻。3D大模型也是一件很新的事情,市场非常大且长期,这肯定是刚刚开始的状态。不过万事开头难,可能这第一步就占了50%。在第一步里,我还是那句话,迈出步去的初心最重要。
Q:那什么时候会是一个节点,比如完成了「1」?
VAST宋亚宸:我觉得这个“1”已经很快了。今年9、10月份,到今年年底,可能算是一个“1”和一个“2”,也就是我们的3D生成达到Midjourney V4甚至有望达到V5的水平。
这件事的关键不在于技术有什么质的突破,或者某个公关活动让大家关注这件事,而是说大模型生成的3D内容终于跨过了用户体验的红线。
我们内部从来不用技术术语讲事情,我们只关注用户体验和用户需求。当我们跨过了用户体验的门槛时,自然就达到了Midjourney V4甚至V5的水平。我们一直不断地与开发者、创作者、客户交流,了解他们到底想要什么,还缺少什么,这些反馈对于我们来说非常宝贵。
可能不是什么技术本质的突破,比如几何更平滑、布线更平直。关键是知道用户想要什么,知道什么功能能满足用户体验。当我们达到这一水平时,就完成了“1”;当我们超越用户期望时,就达到了“2”。
关于365行AI落地方案
AI技术的落地应用不仅限于科技领域,它已经渗透到各行各业,成为推动产业升级的重要力量。因此,“365行AI落地方案”主题策划应运而生,我们寻找各行各业中成功应用AI技术的案例和方案,分享给更多的产业内人士。
- 推理大模型1年内就会撞墙,性能无法再扩展几个数量级 | FrontierMath团队最新研究2025-05-13
- 被拒稿11年后翻盘获时间检验奖,DSN作者谢赛宁:拒稿≠学术死刑2025-05-06
- 全员免费!GPT-4.1上线ChatGPT,首波实测:又快又没油腻感2025-05-15
- 黄仁勋放话:中国AI市场3年内达500亿美元!AI救了旧金山,整个世界急于与AI互动2025-05-07