
对话商汤绝影王晓刚:端到端上车,新的降维打击开始了
“车企低估了AI难度”
贾浩楠 发自 副驾寺智能车参考 | 公众号 AI4Auto
“端到端和传统技术范式的区别,打个比方,就是人脑通用性之于动物的区别”。
王晓刚博士这样解释自动驾驶赛道如今这个“言必称”的火爆概念。
他是商汤科技联合创始人、首席科学家,也是商汤智能汽车业务绝影的负责人。

去年6月全球计算机视觉顶会CVPR 2023,他带领的商汤技术团队的成果一举斩获最佳论文——简称UniAD。
如果要标记中国自动驾驶里程碑的话,商汤提出UniAD,可能是一个新赛程的重要起点:
中国,以及业内首个感知决策一体化的自动驾驶通用大模型。
体现着彻底以全局任务为目标的“一段式”结构,并非对以往技术模式的妥协和改良。
以及UniAD还很有可能是中国第一个真正实现量产上车的端到端自动驾驶体系:商汤科技的楼下,测试车来来往往川流不息。
王晓刚透露,已经有很多车厂表现出了浓厚的兴趣和合作意愿。
“人与动物”,区别在哪?
从去年CVPR 2023最佳论文到现在整整一年时间,王晓刚分享商汤绝影做了这么几件事。
首先是UniAD的产品化、工程化不断推进,已经从几千行代码,完成了向符合汽车工业标准规范的量产产品的演变。
对于一般的自动驾驶公司来说,这一步可能就是目标和终点,也是最难、最紧迫的挑战。能全力交付端到端的产品,就能活到下一轮出牌,至于功能、体验,都可以后期OTA。
但商汤绝影不止步于交付一个单一的自动驾驶模型,更进一步,提出了两个新的技术和应用:
自动驾驶大模型DriveAGI,和车载AI Agent,几个月前北京车展期间就曾提及,刚刚结束的WAIC人工智能大会上,又被王晓刚博士着重强调。
同出一源,都是商汤原生多模态大模型,同时又都以UniAD端到端大模型为基础,和自动驾驶、智能座舱的功能、体验深度关联。
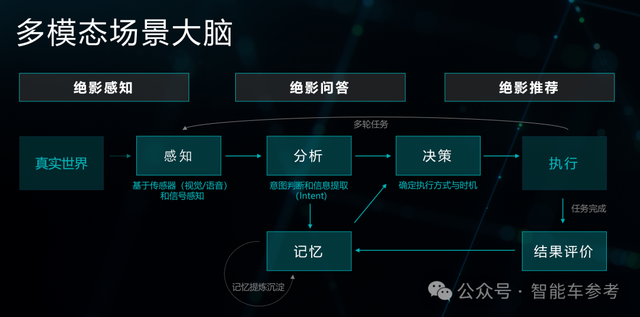
比如DriveAGI,在无高精地图,甚至是针对某种类型目标0样本学习的前提下,也能仅依靠视觉感知实际道路情况,准确地完成包括大角度转向、避让占道车辆及施工区域、绕行跑步行人等一系列高难度操作,做到“像人一样开车”:

在路上遇到救护车,它还可以自动避让;遇到潮汐车道或公交车道时,它能根据限行规则自动规避:

除此之外,它也可以切换不同的驾驶风格,当需要赶时间时,你可以告诉DriveAGI开得更快⼀些;如果是想要放松⼀下,你还可以让它开得平稳⼀些。
到这里你会发现,因为多模态大脑的存在,智驾和智舱,两种完全隔绝的技术、体验,第一次产生联动和协作。智能汽车的体验和交互方式,和以往完全不同了。
现在正值欧洲杯,我们“一边开车一边去找一个看比赛的餐馆”。你直接告诉车载智能助手:订一个晚上能够看欧洲杯比赛的餐馆。
商汤绝影基于多模态大模型的车载AI Agent,会把要求拆解成三个步骤。首先,到小红书看大家的点评,根据你的喜好和地理位置给出推荐,接着在美团进行这个预定,最后打开导航,告诉DriveAGI要去的目的地。

王晓刚特别提到,包括对任务的分拆,以及后续对不同APP的调用、信息内容的总结和操作等等步骤,都是多模态模型凭借理解认知能力“一气呵成”,不存在对某一APP或某一类任务的单独调整适配。
对于智舱来说,多模态大模型就相当于一个超级管家“贾维斯”,所见即所得。
对于智驾,多模态大模型相当于一个“点读机”,图像、视频数据哪里不会点哪里,不理解的目标场景,都能给出准确的解释。
听王晓刚博士讲到这里,可以明显感知到商汤绝影对于端到端的描述和布道,已经和业内主流思路有了底层的区别:从应对自动驾驶挑战,上升到了AGI在车端应用。
是不是太早了?
王晓刚不这么认为。相反,他认为现在谈AGI上车,时机刚好,甚至还有点紧迫,因为AGI应该是端到端的必要条件和前提。
所谓端到端,就是驾驶全流程的AI化,传感器信息输入,直接输出决策数据信号。直接的好处,就是可以让AI模型直接学习成熟的驾驶行为,理论上具备和人一样的驾驶能力。

端到端对传统自动驾驶技术范式的降维打击,是用数据驱动替代规则驱动,解决系统能力上限被锁死,以及后期无休止高投入、维护难的问题。
这样的诱人前景让现在所有玩家都跟进押注。但无论是出于成本考虑还是技术实力所限,现实的情况是大部分产品实现端到端,都是靠“两段式”方法,即感知模型后面,串一个决策和规控模型。
但商汤绝影坚持搞“纯粹”的一段式端到端模型:输入一段视频,输出一段预测的轨迹。

王晓刚给出的理由是两段式首先解决不了信息丢失的问题,但更致命的是后串决策规控模型,“实际上规模很小”。
小模型永远无法激发出应对复杂场景的通用能力,永远无法产生自动驾驶的ChatGPT。
所以端到端天然就应该是原生大模型,也只有这样,才能解决自动驾驶从感知向认知转变的问题。
所以商汤绝影的DriveAGI诞生,把商汤原生多模态大脑能力应用在车端,能够同时输入、处理多种数据类型的模型,可以是文本、语音、图像、视频等等。
实际上相当于给端到端自动驾驶系统,安装了一个和人类基本认知能力相同的大脑。
底层的思路是这样:既然大语言模型的学习、认知能力已经和人类差别不大了,那为什么不能用语言模型基础的范式框架去处理其他数据类型的任务呢?
实际上就是用大模型语义理解能力去看、去分辨图像、视频或者任何类型的数据。
现在都说只有端到端才能真无图,没有无图就没有端到端…这样的观点背后暗含着系统能够“认知”世界的前提,但这是狭义端到端模型本身完成不了的任务。
实际上几乎所有和智能车参考交流过的业内人士,都说现在根本不存在绝对的无图,各家方案都或多或少要用到相关信息。
或者说“端到端”这个大黑盒,决策过程、思维能力等等开发者根本就无从知晓,“菩提本无树”。
现阶段,商汤绝影根据历史研发积累和技术发展趋势给出的最佳解决方案,就是利用多模态大模型展现出的通用AI能力,解决自动驾驶的认知问题。
王晓刚说,商汤其实早在2021、2022年就已尝试过构建大感知模型,当时达到了320亿参数,是世界上最大的之一。然而,尽管模型庞大且数据喂养充足,但其任务仍是识别简单元素,比如车辆、人物和标注框,高难度数据占比很少。换句话说你让模型看什么、学什么,它就专注于此。

语言模型ChatGPT的创造性震惊世界,由此衍生出推动各行各业生产力革命的多种产品雏形,其训练方式并非简单的识别任务。以往语言模型中的翻译或识别意图等任务型训练,根本无法产生像ChatGPT这样的模型。
所谓人和动物的区隔,分水岭明显。
“如果要比特定的任务,跑步人跑不过猫科,嗅觉比不上犬科。但这些动物,只在专有的任务里很强,永远不会进化。”
“但人是有大脑的,人的特点就是通用性强,能不断的培养出新的技能,用新的工具发明创造,搞出很多远远超过动物能力范围之外的东西。”
商汤绝影为什么要在端到端竞争还未明了的时间节点大谈AGI?
王晓刚认为,目的就是要把智能汽车的大脑培育出来,给自动驾驶一个“点读机”,一张没有高精地图的“高精地图”,给智能座舱带来革命性的交互方式变革…
解决了制约自动驾驶、智能座舱功能体验的技术问题,多模态大模型上车带来的AGI潜力,会展现出更多的应用模式,新的东西就会应运而生。
“智能汽车”就不会只停留在现有的维度上了。
“车企低估了AI的难度”
商汤智能汽车业务绝影,本质是商汤追求布局AGI的过程中,被适时“点亮”的一个技能。
商汤进军智能车领域始于2016年,当时本田来中国寻找智能驾驶方向的合作伙伴,最后选定了那时以AI视觉知名的商汤。
2017年末,商汤与本田正式对外官宣了合作,并且商汤也正式明确将把AI之力带给主机厂。
当时商汤提出的产品已经体现出了和其他厂商的不同。

有两个关键点,首先是SenseAuto Empower绝影赋能引擎,包括算法工具箱、数据管理、回灌和仿真评测系统等工具链,供车企灵活定制方案。
但最关键的,是这里面内嵌了商汤最强的视觉感知能力,以及大模型体系支持的AGI能力。
第二个关键,就是从2018年开始,商汤开始布局算力基础设施SenseCore商汤大装置,截至2024年第一季度的总算力规模已达12000 petaFLOPS。
所以等到商汤的智能汽车业务2021年以“绝影”之名首次对外公布时,其实已经是一个有30+车企合作,智驾、智舱方案定点上车2000万辆的重要玩家了。
不过不同于其他任何玩家,商汤绝影不是以单一自动驾驶技术或智能座舱产品交付为目标,而是把汽车作为AGI能力的载体。

以AI技术立身,尤其擅长计算机视觉的商汤,先后在互联网、城市等领域实现场景验证,在落地的一线战场上,商汤很早意识到AGI是解决千行百业各种挑战难题的“最优解”。
这个过程中,逐渐建立了自己的“日日新大模型体系”,涵盖大语言模型、文生图/视频模型、多模态模型等等,能够解决众多开放式任务,率先摸到了通用人工智能的门槛。
而把积累的AGI和大模型能力迁移到具体场景中,王晓刚认为目前汽车是最合适的载体。
因为AGI的基本思路变了,以前是根据任务去开发训练专用模型,而大模型时代,关键是训练出一个很有潜力的能力很强的模型,然后基于这个模型去点亮它各种新功能,不断去挖掘。
就比如OpenAI最新的ChatGPT-4o,展现的就是端到端的多模态融合能力。
但是ChatGPT-4o展示时是用手机,智能手机以大屏幕为主的设计理念,本质是照顾以文本输入为主,和视觉听觉被动接收这样的交互方式。
和手机对话或比划动作、表情,其实对大部分用户来说都很不自在,否则苹果的Siri也不至于这么多年做不起来。
但智能汽车天然就是一个主动式的、以语音图像为主的交互平台。
所以在商汤绝影的理解中,未来可能AGI落地最广的会是人形机器人,但这个10年中,无论是终端搭载规模,还是天然的交互模式,智能汽车就是AGI进行落地的最好的场景和载体。
但是王晓刚又强调,打造通用AI大脑的2.0时代,难度和门槛完全不同。
一个是基础设施的投入,至少需要几千块卡去进行稳定的定向训练,而且训练中怎么进行数据配置,有很多Know How,基本是“资源和金子堆出来的”。
比如多模态模型,每增加一个模态,它的难度就会乘一个系数。
语言模型加进图像的模态,会发现语言的能力会大大退化,因为加入的图像需要跟语言配对,而这种配对的数据十分稀少,而且以往人工标注描述图像的文字干瘪不准确,所以放进来以后,模型语言能力就会降低很多,必须得想各种办法再补回来…
AGI越往后难度越高,尤其是自动驾驶领域,没什么开源,只能靠团队本身去克服各种障碍。

所以端到端的自动驾驶壁垒不断变高,将来能够支撑的团队会越来越少。
至于今天业内很多车企尝试自研,王晓刚认为也不奇怪:拿一些开源的模型试一试,也可以做个七七八八,但低估了AI的难度。
如果把规控改成一个模型,就叫端到端了,那还真不难,的确自己就能做。但如果想做出体验、功能持续迭代能力都很优秀的产品,难度会高很多,因为乏持续高投入的条件。
所以截至目前,王晓刚认为车企和AI公司的合作模式,还不够理想,需要更多的磨合和探索。
“车厂说今天出了个事故,你给我看一看,赶紧把这个bug解了”…这是我们现在跟车厂的合作模式。
但这样一来,我们没有办法看底层数据、拿到最有价值的那一部分,自然很难再去激发大模型新能力,去产生新的应用,产生降维打击。
AGI时代的合作,应该超越过去主机厂采购,供应商供货,然后提供售后服务的简单模式。
王晓刚说绝影愿意白盒交付,帮助车企伙伴理解和掌握大模型技术,只有基于此,才能更加积极配合团队共同开发,加速产品迭代,打造真正以用户为中心的AI大模型产品。
另一方面,作为战略合作伙伴,绝影和主机厂之间也要实现信息和数据的共享,主机厂分享不涉及隐私的数据给绝影,更好的训练出车载原生的大模型,这是共创共赢的。
这一点可能需要更快达成共识,因为有很强的AI技术能力、有10万块GPU、又拥有终端数据的特斯拉FSD,可能就要在一年、一年半之内落地中国。
王晓刚博士谈到这点,透露出罕见的担忧:
中国车企和科技公司的合作闭环里,不能只会解bug。
- 中国Robotaxi出海提速:头部玩家已攻入4大洲30城2025-05-06
- 哈弗全面押注四驱!新能源全系标配Hi4技术,两驱价格享四驱性能2025-04-27
- 中国首款自研V8+上车坦克300虎克版,硬核越野布局全球市场2025-04-27
- 上海车展L4商业化黑马:最强芯片激光雷达同时上车,全无人可换电2025-04-25







