
四大成果同期发布|2024WAIC“探索下一代大模型的基础研究”论坛成功举办
会上同期发布了4个重磅成果及产品,以创新实践阐述技术动态与趋势
上海,7月4日 —— 在2024世界人工智能大会论坛上,国内外院士、专家学者齐聚“超越边界:探索下一代大模型的基础研究”论坛,共同探讨“AI for Science 基础设施建设”和“下一代通用人工智能方法”两大前沿技术话题。本次论坛由世界人工智能大会组委会办公室主办,上海算法创新研究院和北京科学智能研究院承办,上海市人工智能行业协会提供支持。论坛旨在搭建推动下一代人工智能技术交流协作的平台,推动基础设施建设,激发创新效能。
本论坛不仅邀请到多位国内外院士,业内专家学者出席会议研讨交流,并特设置两组圆桌对话进行观点碰撞。值得一提的是,会上同期发布了4个重磅成果及产品,以创新实践阐述技术动态与趋势。
“AI for Science在材料、生命科学、能源化工等领域落地成果的不断涌现,让我们看到其带来的巨大前景。但AI for Science带来的不仅仅是点状的突破,而是系统性地带动科学研究基础设施的建设,推进迈向“平台科研”时代。”
论坛伊始,中国科学院院士鄂维南为大会带来了引导发言。他深入分析了AI for Science目前所处的发展阶段,以及推动AI for Science的基础设施建设的重要性,并设计了“四梁N柱”架构,鄂院士提到,“回顾科学研究的基本资源和基本方法,无论哪个科研方向,都少不了基本原理、实验、文献、算力的支撑。因此,构建科学研究的通用基础平台,即基本原理和数据驱动的模型算法与软件、替代文献的数据库与知识库、高效率、高精度的实验表征方法、高度整合的算力平台,可以推动共性问题的解决。AI方法大大提升了我们的科研能力,但是离真正解决问题还有距离,随之而来的问题是,这剩下的“最后一公里”该如何打通。
同时,虽然目前人工智能算法、大模型已经取得了突出的进步,但在建立人工智能的底层能力,探索更加可持续、能够解决当前大规模能源资源消耗问题的通用人工智能方法等方面,还需继续前行。要实现下一代通用人工智能,需要在算力资源、数据资源、AI数据库能力、下一代模型和人才资源等方面持续发力。人工智能方法还是有很多没有被探索,需与场景结合,从应用到底层技术进行创新。
我们欣喜地看到,业内已经有产品化与平台化的成果产出,本论坛发布的四个产品就是这一趋势的实践案例。
OpenLAM 大原子模型
OpenLAM是“平台科研”与“开源共建”的一个典型代表。“语言数据的爆炸性增长孕育了大语言模型,同样地,微观尺度数据的累积也催生了一种创新的模型——大原子模型。”北京科学智能研究院院长、深势科技创始人张林峰表示“这一模型的诞生,将带来仿真设计在时空尺度与覆盖范围的量级式提升,实验表征信号将能被更好地解析,它将成为原子级生产制造的重要组成部分。”
OpenLAM计划已于2023年底正式发起,北京科学智能研究院协同DeepModeling开源社区以及30多家共建单位,并邀请了原子级建模、表征、制造以及AI产业的多位院士、专家组成顾问团,共同推动构建大原子模型的“社区模式”。秉承“广泛覆盖、谨慎评估、开源开放、开箱即用”的开发理念,本论坛上最新发布了在合金、动态催化、分子反应、药物小分子、固态电池、半导体、高温超导7个领域模型解决方案,这些模型均以开放社区的形式发展而来,并在科学智能广场可下载。“实验科学家的语言和视角还未与AI技术和数据库形成有效的连接,为此我们开发了‘晶体造句’APP,希望更多实验科学家通过这个APP的窗口,来发现并合成更多人们尚未充分探索的材料。”

Science Navigator 1.0: 新一代科研文献开放平台
AI for Science的各项基础设施正在全面落地建设,不仅仅是OpenLAM,本次论坛还同期发布了AI for Science的另一重要基础设施,替代文献的数据库和知识库的优秀实践产品——Science Navigator 1.0。
当前,对学科交叉检索、原文内容溯源、科研数据解读的需求已经远远超出了传统文献检索工具的能力范围,新一代科研文献开放平台Science Navigator应运而生。“Science Navigator 强大的自然语言对话式检索能力,能够迅速定位到科研工作者所需的信息,且回答可溯源到文献原文。”北京科学智能研究院副院长李鑫宇介绍道,“AI向量数据库叠加大语言模型让训练和推理成本大幅降低,等效实现3-6倍参数量模型效果。Science Navigator 1.0不仅仅是一个为科研工作者量身打造的AI平台,它更是一个全新的科研生态系统。Science Navigator开放了绝大部分能力的API接口,使用者可以在这个平台的基础上构建自己的应用和智能体,以满足科研复杂的个性需求,释放更多的时间精力在解决关键问题与创新思考上。”
忆³大模型
那么下一代通用人工智能模型是什么样的?论坛上的专家们也给出了各自的见解。其中之一是类比人脑记忆与思考方式的记忆分层大模型。目前记忆分层的大模型已经在上海算法创新研究院实现。
会上,上海算法创新研究院大模型中心负责人熊飞宇发布了最新科研成果——忆³大模型(Memory³),该模型创新地引入了显性记忆机制,显著提高了性能并降低了训练与推理成本。忆³在传统的模型参数(隐性记忆)与上下文键值(工作记忆)之外,增加了第三种形式的记忆——显性记忆。模型无需训练即可将文本转换为显性记忆,并在推理时快速且稀疏地使用记忆。通过外部化模型存储的知识,显性记忆减轻了模型参数的负担,进而提高了模型的参数效率与训练效率,使基准测试上忆³能够实现约3倍参数量模型的性能。
基于忆³架构的AI搜索引擎,利用显性记忆的快速读写,使回答的时效性更强,准确率更高,内容更完整,还能够根据用户的反馈实时更新和优化答案。隐性记忆使搜索引擎能够理解复杂的上下文关系,提供更精准和个性化的搜索结果。基于忆³的特性,这款AI搜索引擎不仅提高了用户的搜索体验,还在信息检索领域树立了新的标杆。此外,忆³已在金融、媒体等行业落地应用。

MyScale AI 数据库
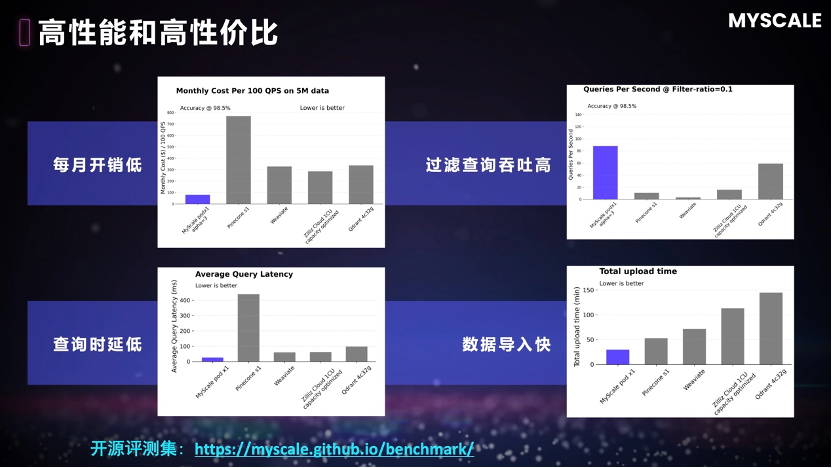
随着以深度学习、大模型为代表的 AI 技术迅速发展,图像、视频、文本、语音等的非结构化数据处理的需求和能力也有了爆发式的增长。高维向量是非结构化数据的统一语义表征,但主流的向量数据库存在通用数据管理能力不足,面对海量数据时性能、可扩展性不佳的问题,难以应对大规模复杂 AI 应用的需求,而 MyScale 的初衷就是克服这些问题并成为 AI 时代的数据底座。
墨奇科技联合创始人/CTO汤林鹏介绍道,“MyScale 是国际上首个专为大规模结构化和非结构化数据处理设计的 AI 数据库,支持海量结构化、向量、文本等各类异构数据的高效存储和联合查询,综合性能比国内外其他产品提高 4-10 倍。在实际生产中,MyScale AI 数据库成功扮演了大模型+大数据双轮驱动下的统一 AI 数据底座。在金融文档分析、科研文献智能问答分析、企业私域知识管理、工业/制造业智能化、零售行业客户服务、人力资源行业智能化、法律行业智能化等应用场景中均帮助客户创造了巨大价值,加速了大模型和场景数据结合的技术创新和应用落地。”
未来,从现在出发。在不断探索人工智能边界的道路上,培植下一代通用人工智能方法、完善AI for Science的基础设施极为关键,它将推动科技向前发展,解锁以前难以想象的创新可能性。
- 阶跃星辰推出开源 SOTA 图像编辑模型,一个月连发三款多模态模型2025-04-27
- 清华系智谱×生数达成战略合作,专注大模型联合创新2025-04-27
- 夸克AI超级框上新“拍照问夸克” 加码多模态能力2025-04-27
- 一季度超百万辆!比亚迪凭实力书写行业 “霸榜” 传奇2025-04-27








