半小时教你手搓AI视频通话,还有懒人版代码已开源
不等OpenAI了
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-4o的“AI视频通话”一鸽再鸽,但网友却是急不可耐想要体验。
于是,一位名叫Santiago(我们叫他三哥)的博主,用160行Python代码尝试了复刻。
虽然技术路线和《Her》有所差别,但从直观效果来看,也算得上是给网友们带来了新的玩具。
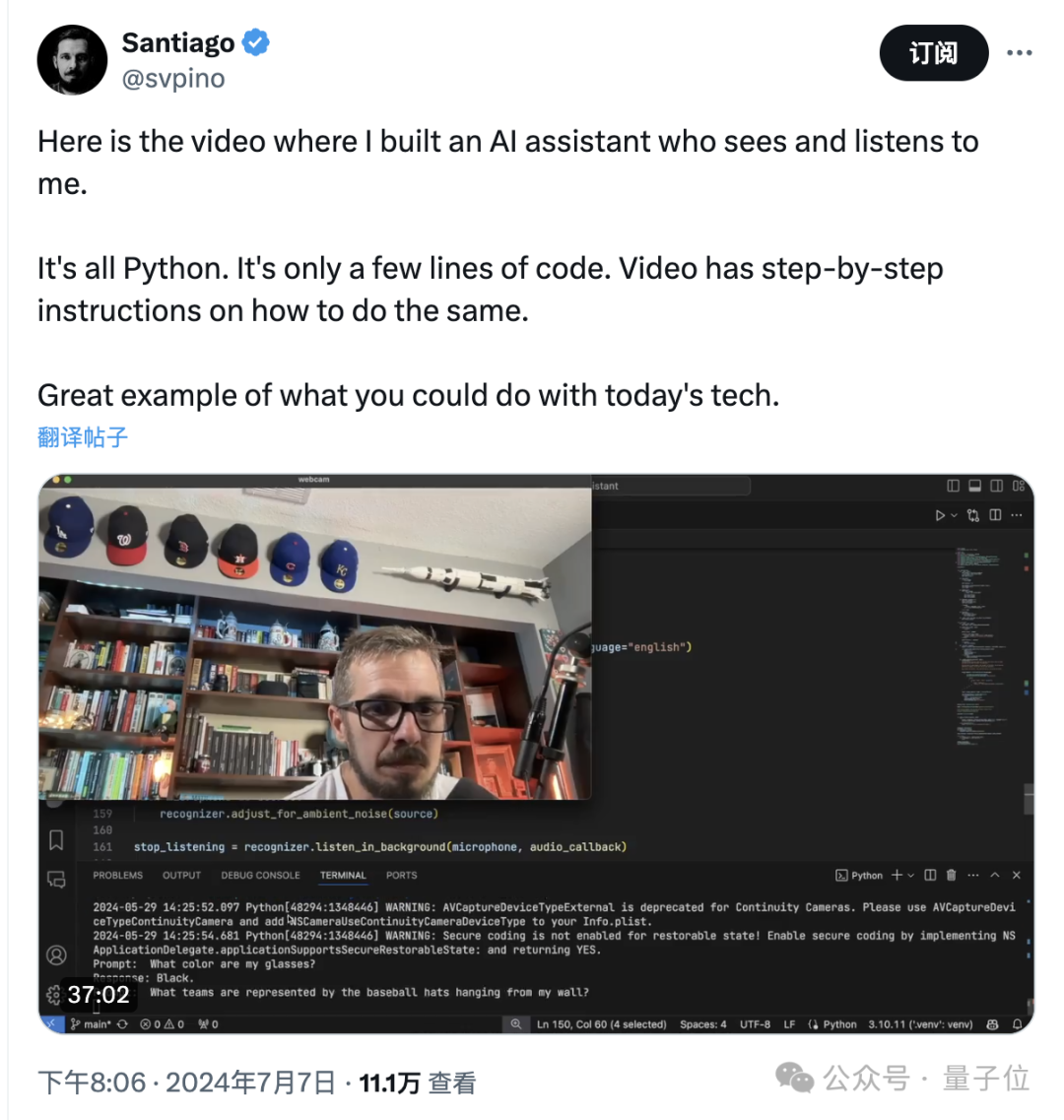
而且不仅是炫技,三哥是真的在试图把网友教会,用了半个多小时的时间讲解他的操作过程。
不过,三哥的自我介绍中说,自己是一个讲授硬核机器学习知识的博主,之前也推出过不少课程。
所以讲课这件事对三哥来说,也可以算是老本行了。
对三哥这次推出的新课,网友给予了很高的评价,表示不仅内容很赞,而且讲解得也很好。

甚至为了防止你觉得学起来太麻烦,三哥直接就把程序代码给公开了。
还有网友在线催更,有的想要增加屏幕读取的功能,还有人想要移动版……
用Python实现AI视频通话
三哥做的视频通话程序名叫Alloy Voice Assistant(简称Alloy),在视频中他演示了这样几组对话效果。
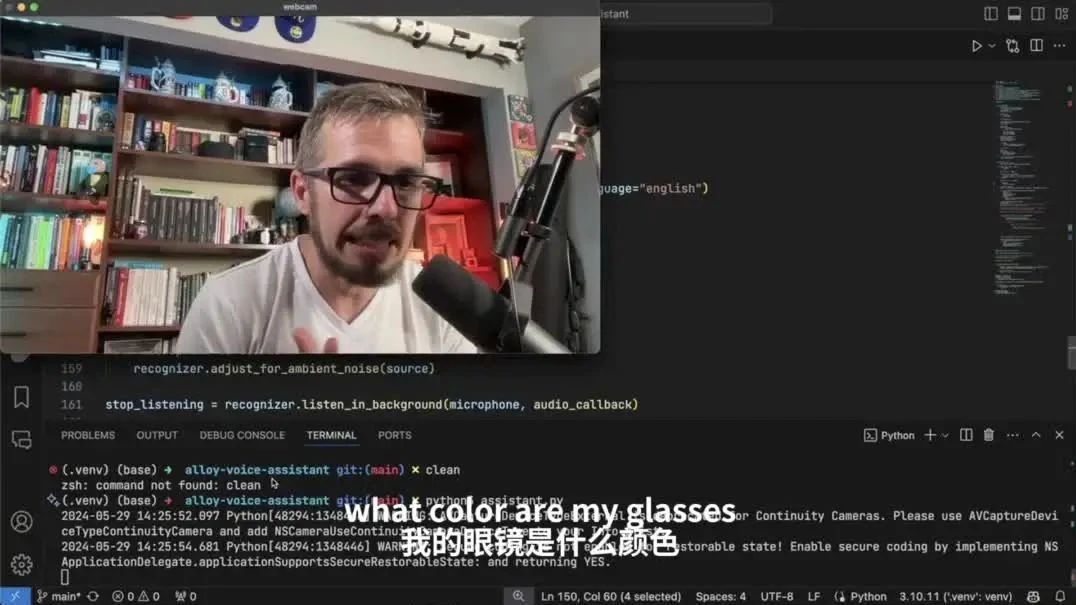
首先是一道基础问题,三哥让Alloy识别一下自己戴的眼镜是什么颜色。
这道题对Alloy来说确实是没什么难度,很轻松就能回答上来是黑色。
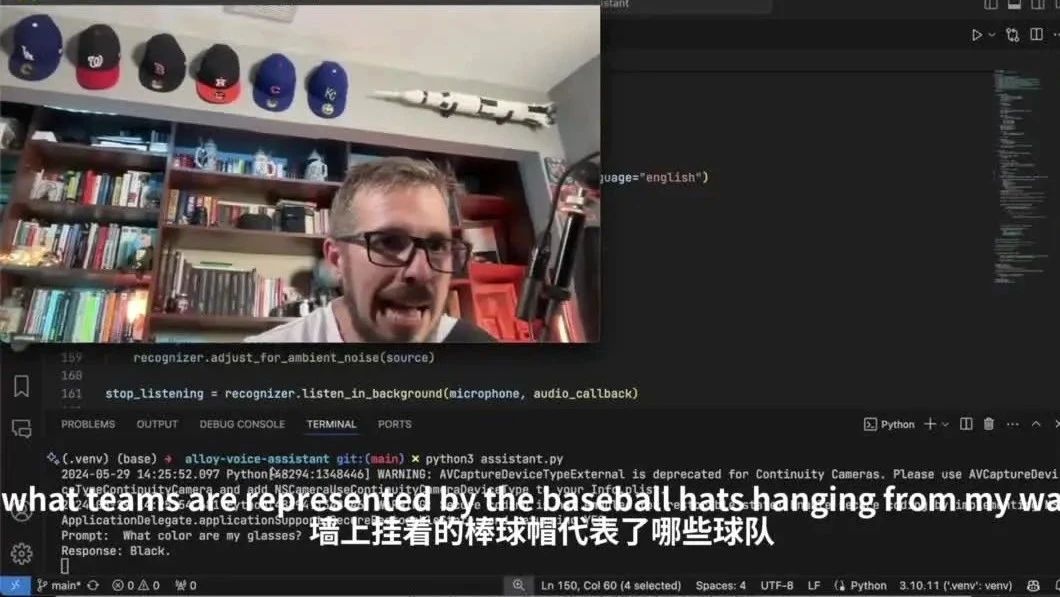
接下来,三哥就要给Alloy上难度了,这次要识别的是棒球帽上的徽章,并分析出所代表的球队。
这次不仅要识别的内容和镜头的距离变远了,而且Alloy需要一次性识别六个。
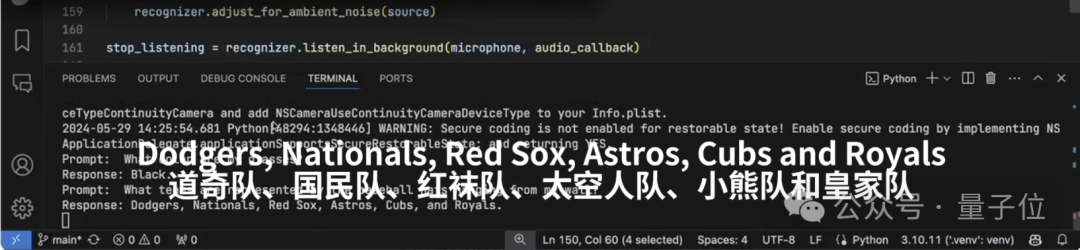
关于视频中涉及的棒球帽,我们来看下特写:
从左到右依次是(洛杉矶)道奇队、(华盛顿)国民队、(波士顿)红袜队、(休斯顿)太空人队、(芝加哥)小熊队和(堪萨斯城)皇家队。

我们再来看下Alloy给出的回答……完全正确。
最后一题,Alloy需要识别的内容变成了文字——不仅要知道写了什么,还要知道文字代表的含义。
只见三个拿出了一本书朝向了镜头,先后询问Alloy书的名称和作者。
这本书是苹果机器学习高级工程师Robert Munro Monarch写的Human-in-the-Loop Machine Learning(《人在回路·机器学习》),Alloy回答对了。
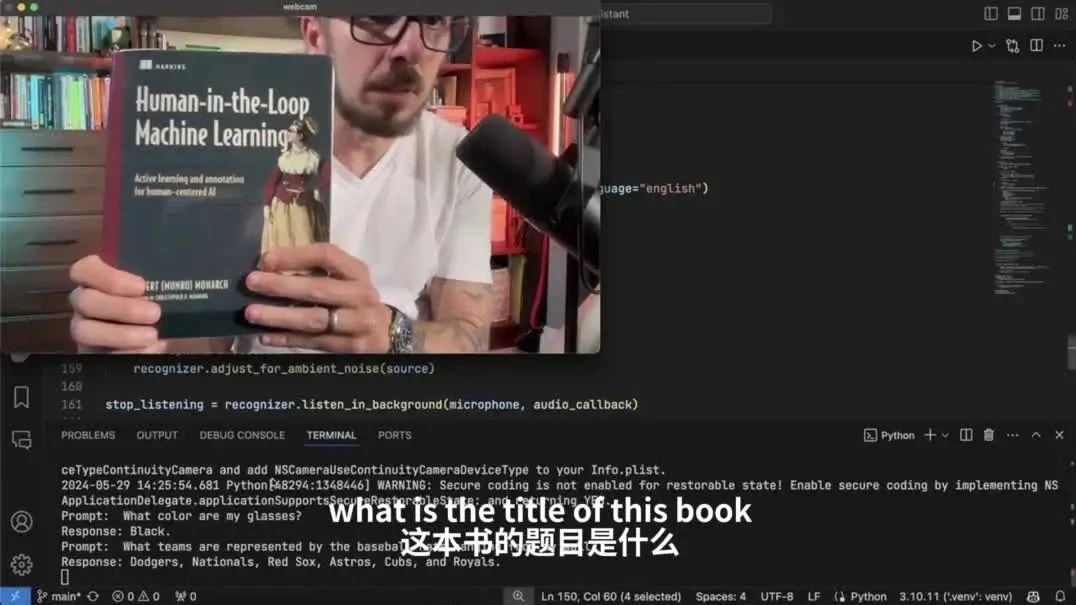
从三哥的演示中我们可以看出,Alloy在识别和回答的准确率上还是很能打的,不过响应的速度也确实慢了一些。
但毕竟不是原生功能,需要在多个API之间进行跳转,所以也算是可用。
那么Alloy到底是怎么实现的呢?三哥进行了在线教学。
37分钟细致讲解,还有开源懒人版
跟随着三哥的讲解,我们先来看一下都需要用到哪些工具。
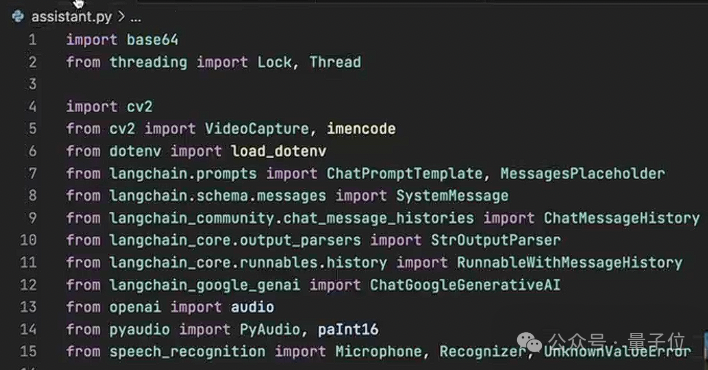
既然要“视频通话”,当然就得有视觉处理模块,三哥用OpenCV来对画面进行捕获,然后交给多模态大模型进行处理。
具体的大模型可以有多种选择,包括GPT-4o、Claude和Gemini 1.5 Pro等,同时大模型还要承担文本处理的任务。
这是由于Alloy并非原生支持音频模态,所以处理音频的方式是通过文本作为中介实现,这就需要用到语音识别和合成模块,这里三哥用的分别是OpenAI的Whisper和TTS引擎。
另外,为了让大模型的集成变得更加容易,三哥这里还使用到了大模型编程框架LangChain。
最重要的,想要把这些模块都组合在一起,就需要用Python来编写代码,也要有相应工具的API。
看到这些工具,Alloy的大致工作流程也就清晰明了了——
麦克风和摄像头负责收集视觉和声音信息,然后声音被转换成文本并于视觉信息一起通过API送入大模型,大模型完成分析后以文本形式回传,最后用TTS模块合成语音并通过扬声器播放。
具体操作中,需要先安装好所需要的依赖库,并申请相应大模型的API,并创建一个Python程序加载这些依赖。
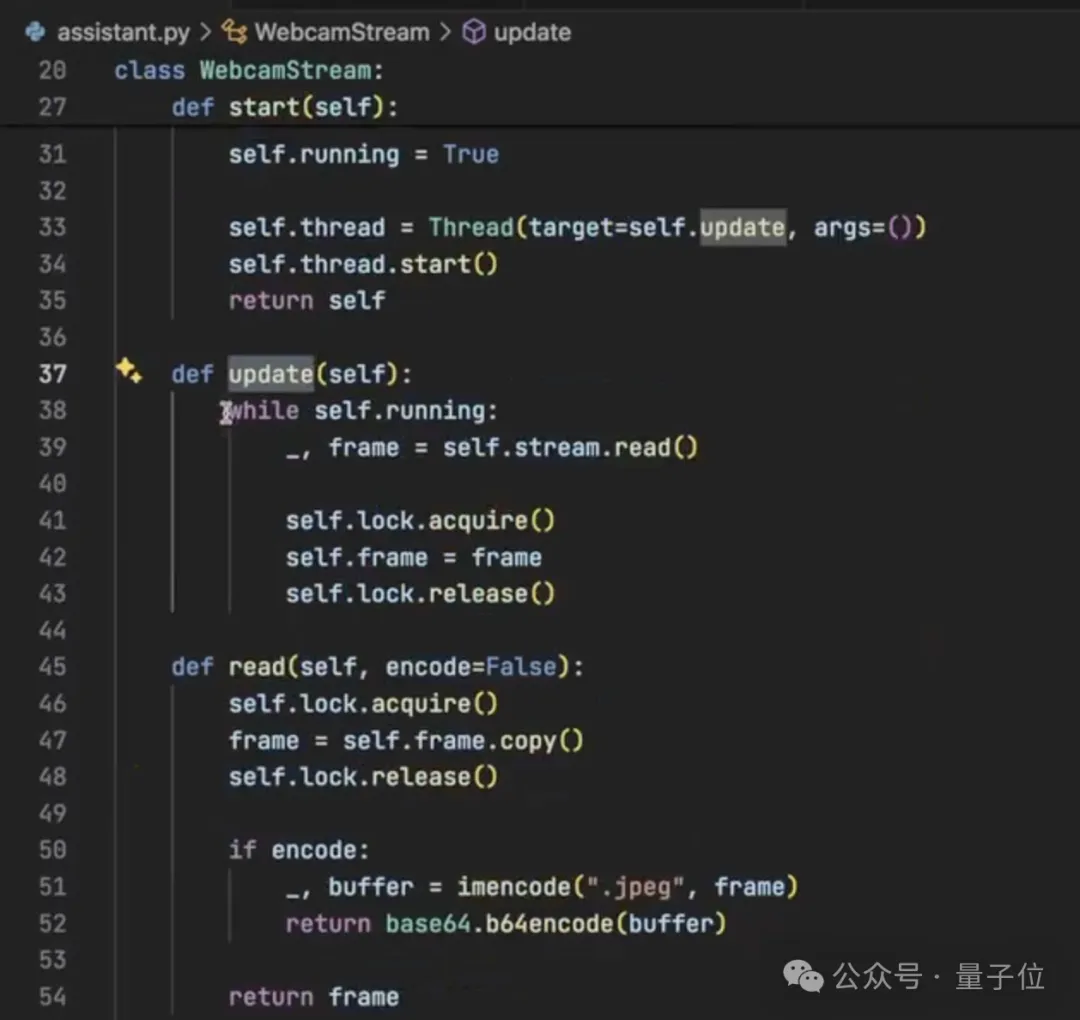
之后是编写WebcamStream类,用来捕获摄像头当中的图像,这里就用到了OpenCV当中的VideoCapture。
视频中,三哥针对每一行代码的含义和作用都进行了解释,感兴趣的话可以看原视频,这里就不一一展开了。
之后是Assistant类,也是整个Alloy系统中最核心的环节,从初始化和配置AI模型,到处理用户输入、声文互转、生成回答,再到对话记录的管理,Assistant都发挥着重要作用。
可以说,Assistant类是串起用户、输入设备和AI模型的桥梁,也是三哥在整个教程中讲解时间最长的一部分。
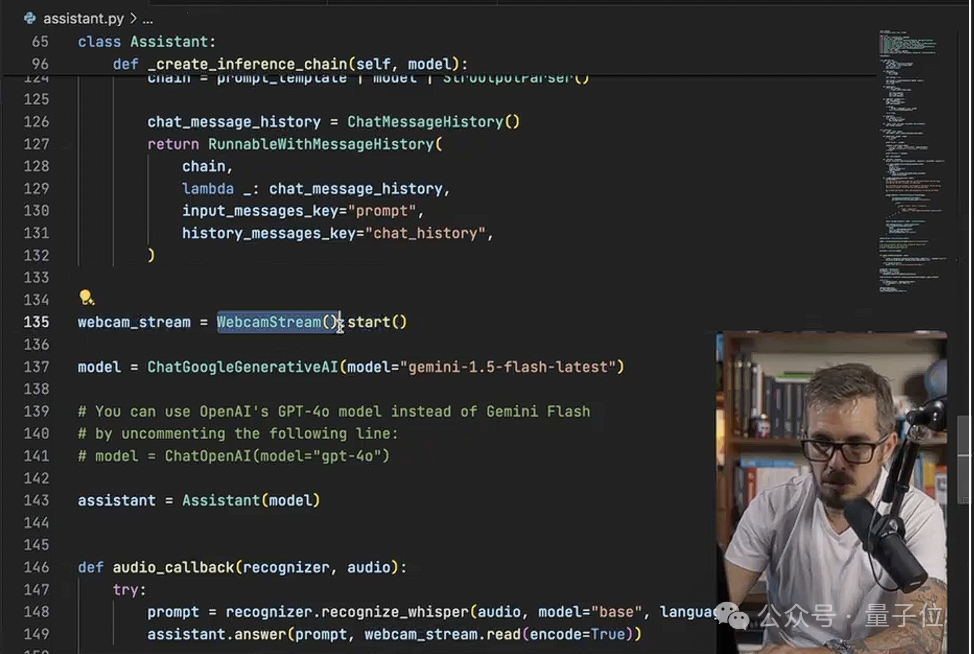
把这两个类定义好之后,最后就是主程序的设计,首先为这两个类各创建一个实例,之后配置摄像头和麦克风,就可以进入主循环体了。
主循环体会不断从WebcamStream实例中读取最新的视频帧,并使用OpenCV的imshow()函数在窗口中实时显示。
同时,当语音识别器检测到用户开始说话并结束时,会自动将语音转换为文本,并调用相关函数进行处理。
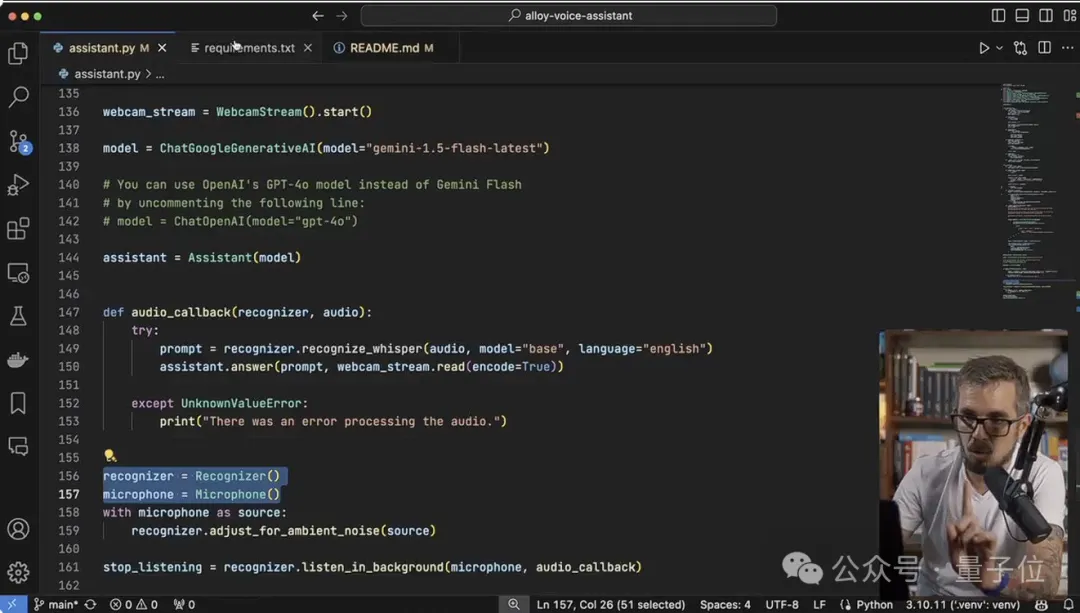
以上就是Alloy搭建的大致流程了,如果看了觉得实在太麻烦不想自己动手的话,三哥还在GitHub上准备了懒人版。
只需要根据选择的模型调整几行代码并填好API,就能直接用了。
如果你也想体验一下AI视频通话的话,不妨动手试一下吧。
原视频地址:
https://www.youtube.com/watch?v=zVttVCQvACQ
GitHub:
https://github.com/svpino/alloy-voice-assistant
- 电视装了智能体,只凭台词就能找到剧集了2025-04-24
- 无需数据标注!测试时强化学习,模型数学能力暴增 | 清华&上海AI Lab2025-04-24
- “史上最快闪存技术”登Nature!复旦新成果突破闪存速度理论极限,每秒执行操作2500000000次2025-04-23
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23