扩散模型也能推荐短视频!港大腾讯提出新范式DiffMM
全新多模态推荐系统范式
DiffMM团队 投稿
量子位 | 公众号 QbitAI
想象一下你在刷短视频,系统想要推荐你可能会喜欢的内容。
但是,如果系统只知道你过去看过什么,而不了解你喜欢视频的哪些方面(比如是画面、文字描述还是背景音乐),那么推荐可能就不会那么精准。
对此,来自港大和腾讯的研究人员推出了全新多模态推荐系统范式——DiffMM。

简单来说,DiffMM创建了一个包含用户和视频信息的图,这个图会考虑视频的各种元素。
然后它通过一种特殊的方法(图扩散)来增强这个图,让模型更好地理解用户和视频之间的关系。
最后,它使用一种叫做对比学习的技术,来确保不同元素(比如视觉和声音)之间的一致性,这样推荐系统就能更好地理解用户的喜好。
为了测试效果,团队在三个公共数据集上进行了大量实验,结果证明DiffMM相比于各种竞争性基线模型均达到SOTA。

目前相关论文已公开,代码也已开源。
模型方法
DiffMM的总体框架图如下所示,主要包含三个部分:
- 多模态图扩散模型,通过生成扩散模型实现多模态信息引导的模态感知用户-物品图生成;
- 多模态图聚合,通过在生成的模态感知用户-物品图上进行图卷积操作以实现多模态信息聚合;
- 跨模态对比增强,通过对比学习的方式来利用不同模态下用户-物品交互模式的一致性,进一步增强模型的性能。
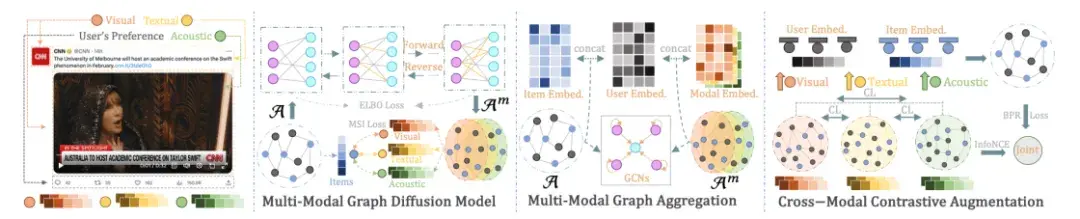
多模态图扩散
受到扩散模型在保留其生成输出中的基本数据模式方面的成功的启发,DiffMM框架提出了一种新颖的多模态推荐系统方法。
具体而言,作者引入了一个多模态图扩散模块,用于生成包含模态信息的用户-物品交互图,从而增强对用户偏好的建模。
该框架专注于解决多模态推荐系统中无关或噪声模态特征的负面影响。
为实现这一目标,作者使用模态感知去噪扩散概率模型将用户-物品协同信号与多模态信息统一起来。
具体而言,作者逐步破坏原始用户-物品图中的交互,并通过概率扩散过程进行迭代学习来恢复原始交互。
这种迭代去噪训练有效地将模态信息纳入用户-物品交互图的生成中,同时减轻了噪声模态特征的负面影响。
此外,为实现模态感知的图生成,作者提出了一种新颖的模态感知信号注入机制,用于指导交互恢复过程。这个机制在有效地将多模态信息纳入用户-物品交互图的生成中起到了关键作用。
通过利用扩散模型的能力和模态感知信号注入机制,DiffMM框架为增强多模态推荐器提供了一个强大而有效的解决方案。
图概率扩散范式
在用户-物品交互上进行图扩散包含两个关键工程。
第一个过程称为前向过程,它通过逐步引入高斯噪声来破坏原始的用户-物品图。这一步骤逐渐破坏了用户和物品之间的交互,模拟了噪声模态特征的负面影响。
第二个过程称为逆向过程,它专注于学习和去噪受损的图连接结构。这个过程旨在通过逐步改进受损的图来恢复用户和物品之间的原始交互。
对于前向图扩散过程,考虑用户和物品集合中每个物品的交互,定义为 =[

,
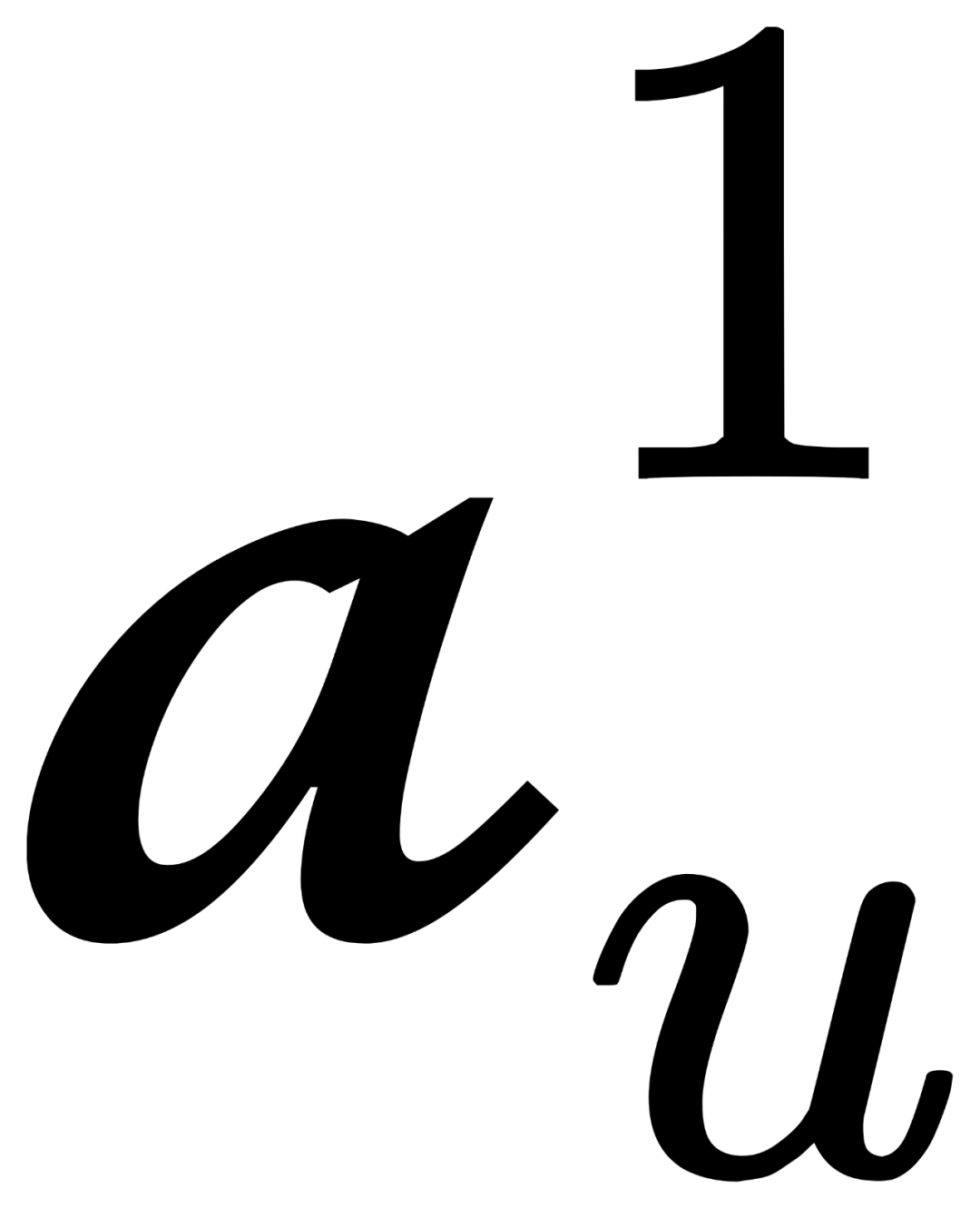
,…,
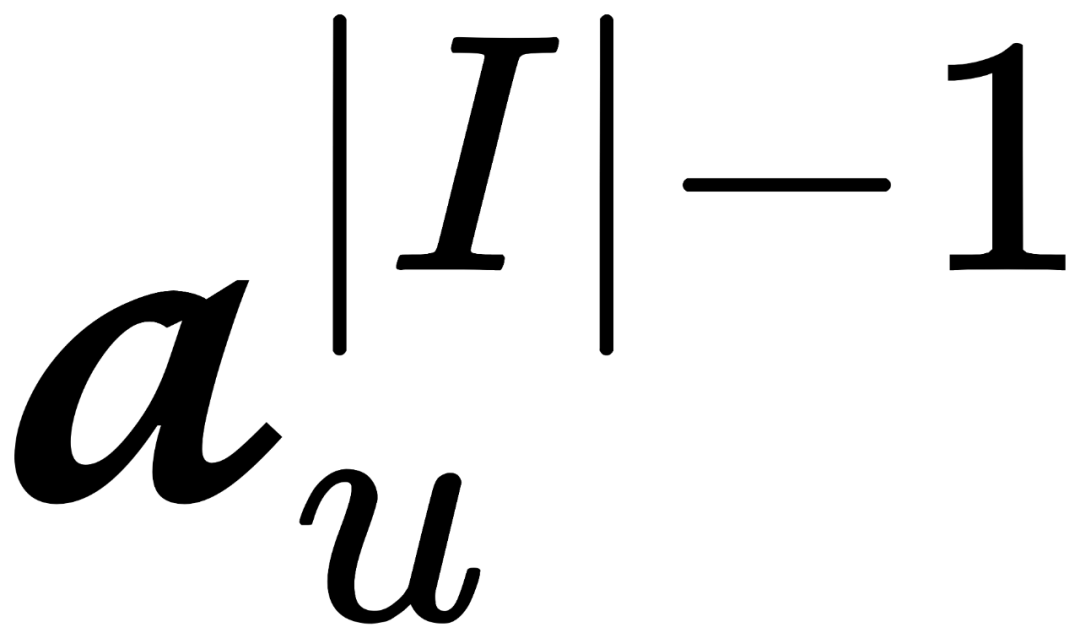
],这里
等于0或1表示用户是否和物品有发生交互。首先将扩散过程进行初始化: 0= ,这个前向过程之后在步中逐渐添加高斯噪声,以马尔可夫链的形式构建1:。
具体而言,从t-1到t的过程参数化为:
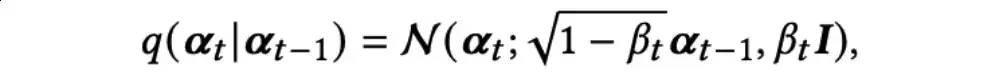
当→∞时,状态逐渐趋向于一个标准的高斯分布。作者使用重参数技巧以及独立高斯噪声可相加的性质,直接从0得到t:
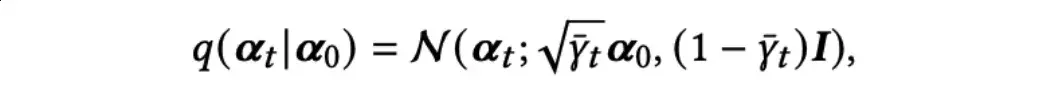
对于逆向图扩散过程,DiffMM旨在消除从t引入的噪声,逐步恢复t-1。这个过程使得多模态扩散能够有效地捕捉复杂的生成过程中的微小变化。从开始,去噪过程逐步恢复用户-物品交互,逆向过程展开如下:
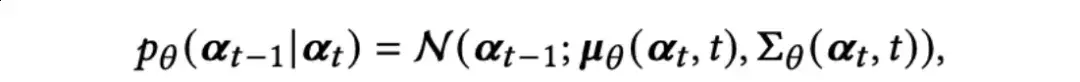
作者使用参数为的神经网络来生成一个高斯分布的均值(t,t)和协方差 (t,t)。
模态感知的图扩散优化
扩散模型的优化目标是引导逆向图扩散过程。为了实现这一目标,应优化0的负对数似然的Evidence Lower Bound (ELBO):
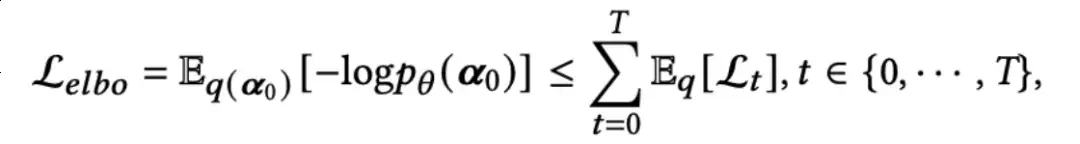
对于t,有三种情况:
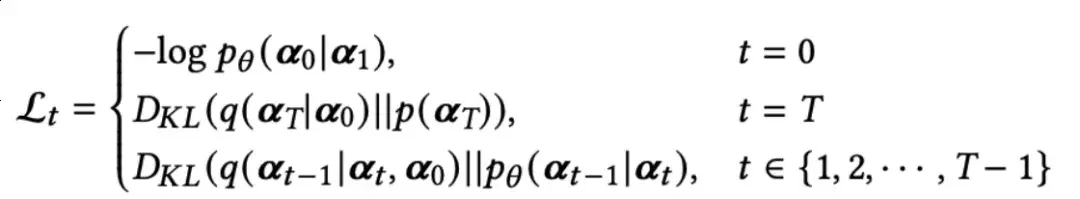
这里,0是0的负重建误差;是一个在优化中可以忽略的常量项,因为它不包含可优化的参数;(t∊{1,2,…,T-1})旨在通过KL离散度使分布(t-1|t)和可计算的分布q(t-1|t,0)对齐。
为了实现图扩散的优化,作者设计了一个神经网络,以在反向过程中进行去噪处理。根据贝叶斯法则,q(t-1|t,0)可被表示为如下近似表达:
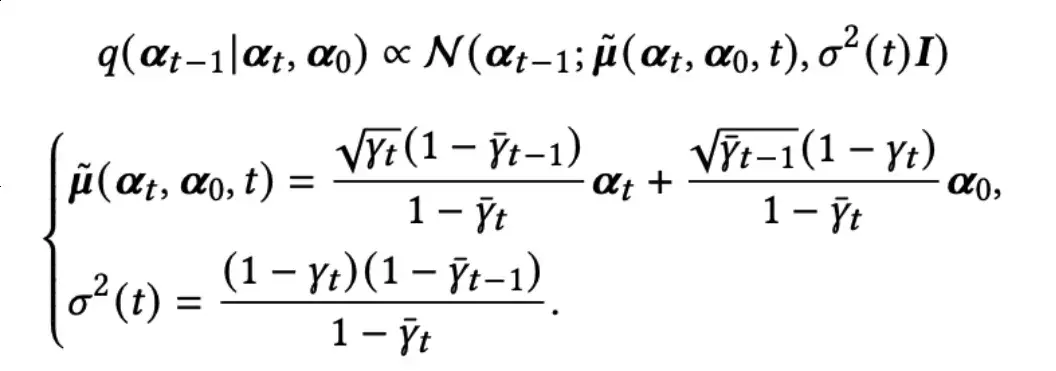
更进一步,t可以表示为:
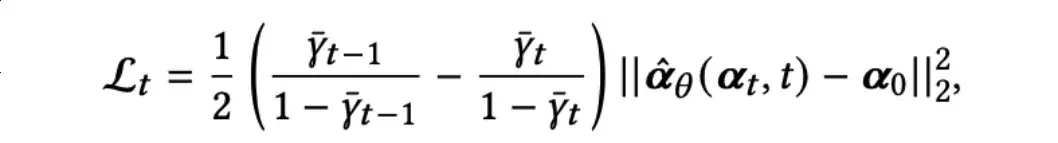
这里,

(t,t)是基于t和时间t预测的0,作者使用神经网络来实现它。具体而言,作者使用一个多层感知器(MLP)来实现
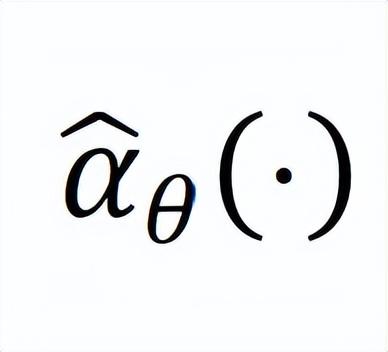
,该MLP以t和时间t的嵌入表示作为输入来预测0。对于0,可以被表示为:
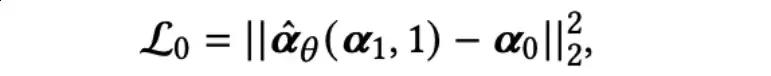
在实际实现中,作者从 {1,2,…,} 中均匀采样来得到时间步t:
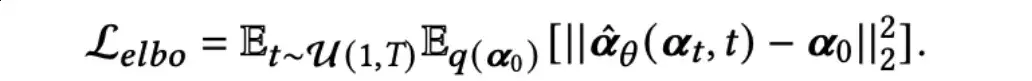
多模态图扩散的目标是通过模态感知的用户-物品图来增强推荐系统。
为此,作者设计了一种模态感知信号注入(MSI)机制,引导扩散模块生成带有相应模态的多个用户-物品图。
具体而言,作者将对齐的物品模态特征与预测的模态感知用户-物品交互概率进行聚合。
同时,作者还将物品id嵌入与观察到的用户-物品交互0进行聚合。
最后,计算上述两个聚合嵌入之间的均方误差损失,并与ebo一起进行优化。形式化地,模态的均方误差损失如下所示:
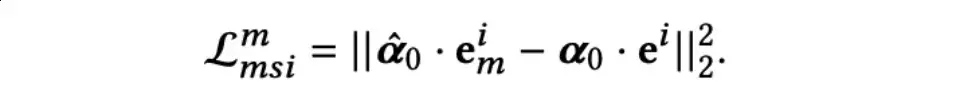
跨模态对比增强
在多模态推荐场景中,不同物品模态(例如:视觉、文本和音频)上的用户交互模式存在一定程度的一致性。
例如,在短视频的情况下,其视觉和音频特征可以共同吸引用户观看。
因此,用户的视觉偏好和音频偏好可能以复杂的方式交织在一起。为了捕捉和利用这种模态相关的一致性来提高推荐系统的性能,作者设计了两种基于不同锚点的模态感知对比学习范式。
一种范式以不同的模态视图作为锚点,另一种范式则以主视图(协同过滤)作为锚点。
模态感知的对比视图
为了生成特定模态的用户/物品嵌入表示作为对比视图,作者使用了基于GNN的表示学习方法。
具体而言,在图扩散模型生成的模态感知用户-物品图上进行消息传递。
首先,作者将物品原始模态信息转化为相同维度的物品模态特征:
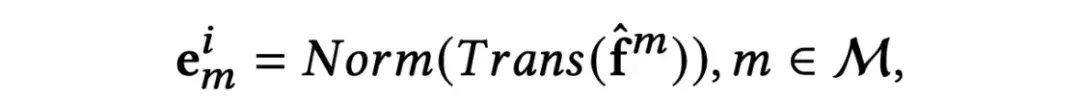
接下来,对用户嵌入和物品模态特征进行信息聚合,得到聚合的模态感知嵌入m∈ℝd:
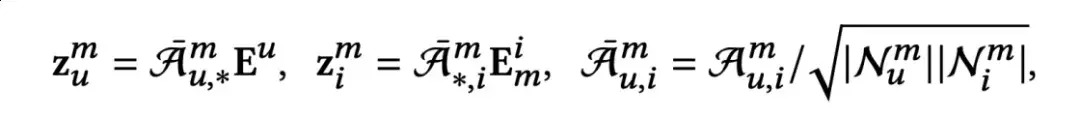
这里,m∈ℝ×表示通过图扩散模型生成的模态感知图。为了获得多模态感知的高阶协同信息,作者进一步在原始用户-物品交互图进行了迭代的消息传递:

模态感知的对比增强
通过模态感知的对比视图,作者采用了两种不同的对比方法。
其中一种利用不同的模态视图作为锚点,而另一种则使用主视图作为锚点。
前者的思想是基于用户在不同模态中的行为模式具有关联性,而后者则希望用户在不同模态中的行为模式可以引导及提升主视图的偏好表达。这里的主视图指通过GNN在多个模态感知图上聚合再进一步融合得到的用户与物品表达。两种对比方法的对比损失(InfoNCE loss)分别如下所示。
模态视图作为锚点:
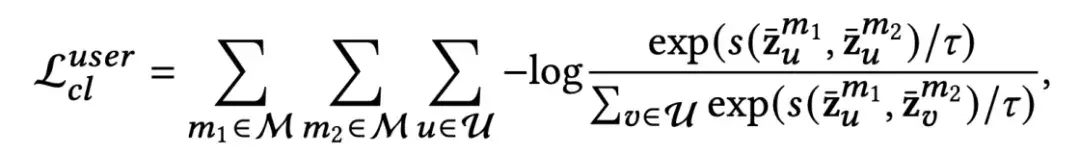
主视图作为锚点:
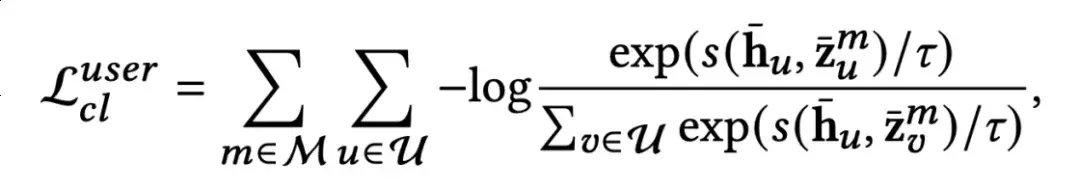
多模态图聚合
为了生成最终的用户(物品)表示以进行预测,作者首先对所有的模态感知嵌入和相应的模态感知用户-物品图进行聚合:
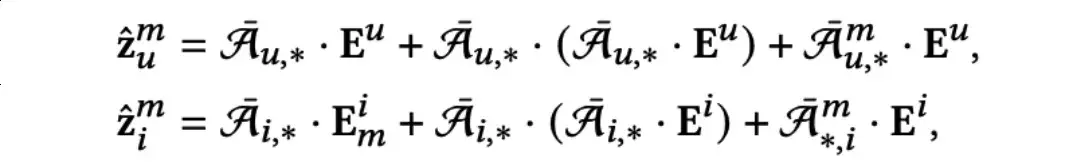
之后通过一个可学习的参数化向量Km控制各个模态的权重,以求和的方式融合各个模态的表示:
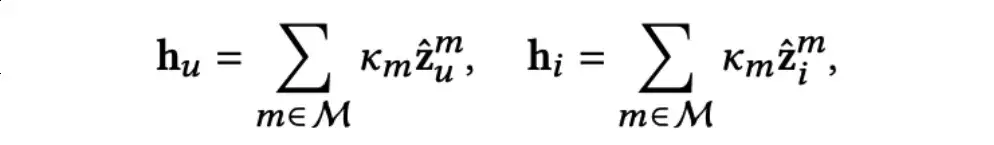
之后在原始的用户-物品交互图上进行消息传递,以利用高阶的协同信号:

多任务模型训练
DiffMM的训练包含两个部分:对于推荐任务的训练和对于多模态图扩散模型的训练。
对于扩散模型的联合训练,也包括两个部分:ELBO损失和MSI损失。对于模态的扩散模型去噪网络的优化损失如下:
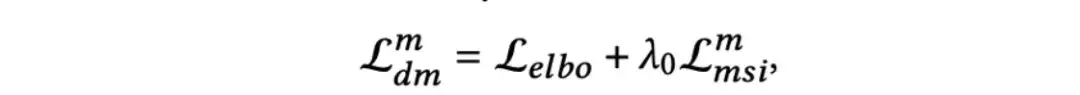
对于推荐任务的训练,作者引入了经典的贝叶斯个性化排名(BPR)损失和多模态对比增强损失c,BPR损失定义如下:
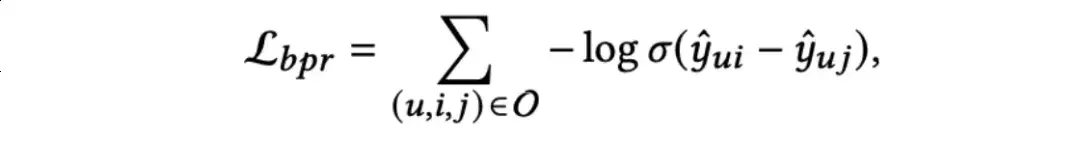
推荐任务的联合优化目标如下:
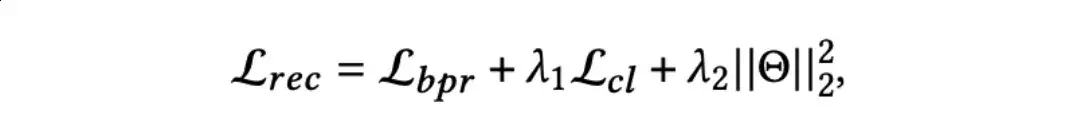
实验结果
作者在三个公开数据集上对比了多个类型最新的基线模型,包括传统的协同过滤方法,基于GNN的方法,生成扩散推荐方法,自监督推荐方法以及SOTA的多模态推荐方法。
通过广泛而充分的实验,结果表明提出的DiffMM在总体性能上具有最优的性能。

为了验证所提出方法各个模块的有效性,作者进行了细致的消融实验,实验结果表明所提出的各个子组件均有提升推荐效果的功能:

作者进一步探索了DiffMM在数据稀疏问题上的表现,实验结果表明DIffMM中的跨模态对比学习方式可以有效缓解数据稀疏的问题,它通过使用图扩散模型生成的模态感知用户-物品图来获得高质量的自监督信号。
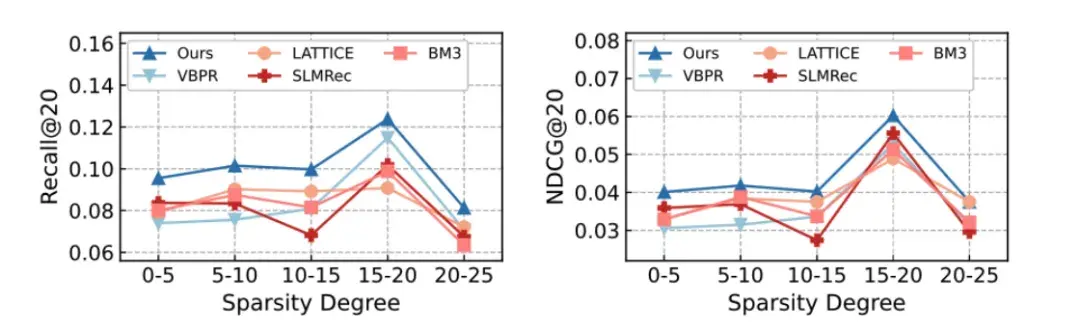
对于所提出的DiffMM,作者对一些重要的超参数进行了分析,包括多模态图聚合模块中的超参数、模态感知扩散模型中的MSI权重、以及多模态对比增强范式中的温度系数等:
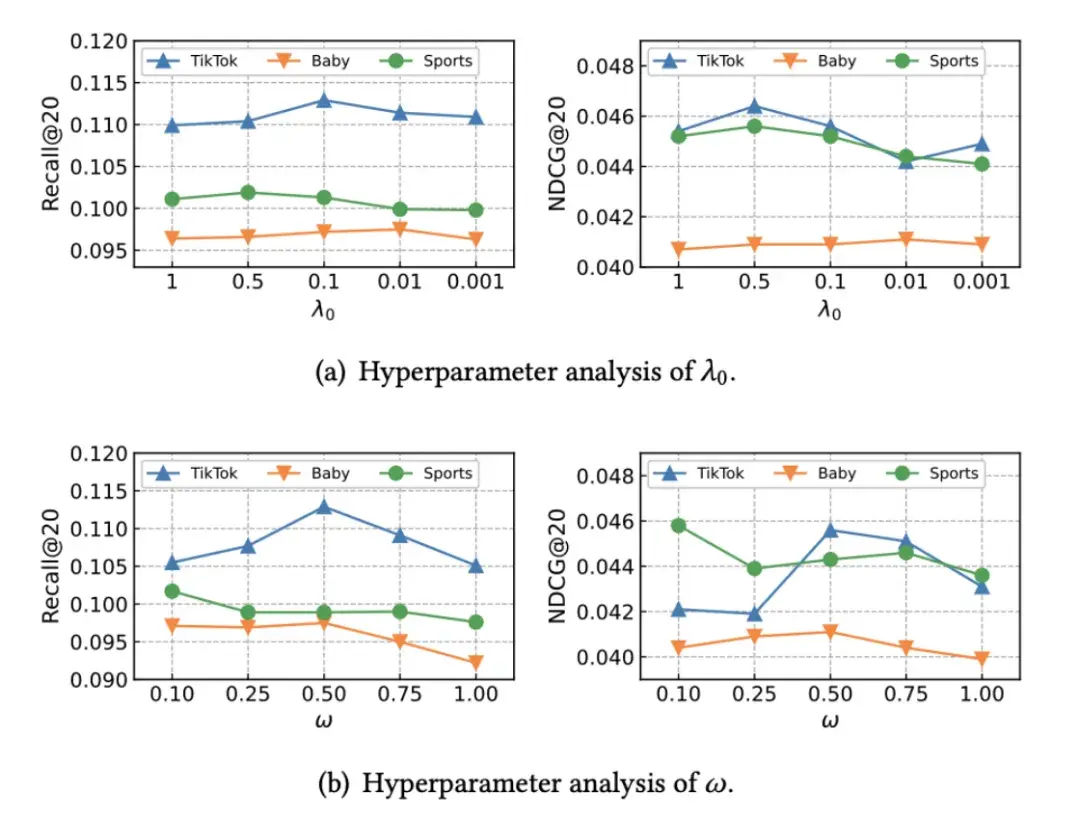
为了更直观地评估所提出的模态感知图扩散模型对推荐系统性能的影响,作者研究了模态感知用户-物品图(由DiffMM生成)和通过边丢弃进行随机增强的用户-物品图之间的融合比率对于自监督增强对比视图构建的影响。
融合比率为0表示仅使用模态感知的用户-物品图来构建对比视图,而融合比率为1则表示仅使用随机增强方法。
结果明确表明,在两个数据集中,融合比率的增加导致模型性能的下降。
这一发现表明模态感知的图扩散模型通过提供模态感知的对比视图而不是随机增强视图来增强跨模态对比学习的优越性。这个优势可以归因于基于图扩散的生成方法对潜在交互模式的有效建模,以及通过精心设计的生成机制将多模态上下文纳入到用户-物品交互图的扩散过程中。
总结
本文介绍了一种新的多模态推荐模型DiffMM,它通过结合模态意识丰富了概率扩散范式。
该方法利用多模态图扩散模型重构了模态感知的用户-项目图,同时利用跨模态数据增强模块的优势提供有价值的自监督信号。
为了评估DiffMM的有效性,作者进行了大量的实验,并将其与几种竞争基线模型进行了比较,结果证明了DiffMM在推荐性能方面的优越性。
论文:https://arxiv.org/abs/2406.11781
代码:https://github.com/HKUDS/DiffMM
- 心影随形创始人刘斌新:做不跟用户抢时间的AI产品丨中国AIGC产业峰会2025-04-22
- 狸谱App负责人一休:从“叫爸爸”小游戏到百万月活AI爆款,社交传播有这些底层逻辑丨中国AIGC产业峰会2025-04-23
- 直观即时绘制3D模型,可添加文本提示,VAST又开源了2025-04-21
- LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯2025-04-06

相关阅读


腾讯优图开源深度学习推理框架TNN,助力AI开发降本增效
6月10日,腾讯优图实验室宣布正式开源新一代移动端深度学习推理框架TNN,通过底层技术优化实现在多个不同平台的轻量部署落地,性能优异、简单易用。基于TNN,开发者能够轻松将深度学习算法移植到手机端高效的执行,开发出人工智能 APP,真正将 AI 带到指尖。