面向终端侧生成式AI规模化扩展,高通重新定义SoC系统性能
内附演讲全文
允中 发自 凹非寺
量子位 | 公众号 QbitAI
6月27日,高通公司AI产品技术中国区负责人万卫星出席2024世界移动通信大会(MWC上海),并在“人工智能领域的投资、创新与生态系统发展”主题会议发表了主题为“终端侧生成式AI的未来” 的演讲。

他指出,生成式AI的能力和用例正不断丰富和扩展,高通通过其创新的SoC系统设计,凭借面向生成式AI全新设计的NPU和异构计算系统,为终端侧AI规模化扩展提供了有力支持。他还详细介绍了NPU的演进路线,以及如何利用第三代骁龙8移动平台率先实现多模态大模型的端侧运行。此外,高通的AI软件栈支持跨终端、跨OS、跨平台的灵活部署,并通过构建AI生态系统,支持国内外广泛的终端侧生成式AI模型,持续推动AI技术的发展和创新。
以下为演讲全文:
尊敬的各位嘉宾,大家好!我是高通公司万卫星,很高兴来到MWC上海,并借今天的活动,与各位嘉宾共同讨论生成式AI在终端侧的发展。同时,我也会和大家分享高通公司的产品和解决方案是如何助力推动生成式AI在终端侧的规模化扩展的。
我们注意到,随着相关应用的普及,生成式AI的能力正在持续增强,主要体现在两个方面。第一,它的能力和KPI日益提升。比如大语言模型可以支持更长的上下文,大视觉模型可以处理更高分辨率的图片和视频,可以通过LoRa等先进技术,针对不同消费者、企业或行业,定制微调模型。第二,模式和用例更加丰富。现在有越来越多的用例支持语音UI,越来越多的大型多模态模型,可以更好地理解世界,有越来越丰富、逼真的视频和3D内容生成等。
之前大家聊生成式AI更多是云端,但现在无论手机等OEM厂商,还是芯片厂商,都能够看到生成式AI正在从云端迁移到边缘云和终端侧,未来端云协同的混合AI将推动生成式AI的规模化扩展,在云和边缘及终端侧之间分配工作负载,提供更强大、更高效和高度优化的体验。
具体来讲,在中央云会有一个大规模通用模型,提供绝对性能算力;在终端侧会有一个参数量相对较小、但能胜任具体任务的模型,提供具备即时性、可靠性、个性化,以及更能保障隐私和安全性的服务。针对新的AI用例和工作负载,我们重新定义和设计了SoC,定义了一个专为AI而打造的SoC的系统,推出了高通AI引擎这个异构计算系统。
高通AI引擎中包含CPU、GPU、NPU,以及超低功耗的高通传感器中枢。
下面我来解释一下,我们SoC的异构计算系统如何满足这些丰富的生成式AI用例的多样化要求,包括对算力等各种KPI的要求。我们知道,很难有单独一个处理器能满足这样多样化的要求。
我们将生成式AI用例分为按需型、持续型和泛在型,比如对时序要求比较高、对时延很敏感的按需型用例,我们会用CPU来进行加速;对于对管道处理、图像处理、并行计算要求比较高的用例,我们通过性能强大的Adreno GPU来进行加速;对于一些对算力要求较高、对功耗要求较高的用例,包括图像处理、视频处理、大模型等,我们会通过NPU进行加速。
接下来,我会深入介绍一下高算力、低功耗NPU的演进路线,这是一个通过上层用例驱动底层硬件设计的非常典型的案例。
在2015年之前,AI用例主要集中在音频和语音处理方面,模型尺寸相对较小,所以我们给NPU配置了一个标量和一个矢量硬件加速单元。2016年到2022年,AI用例从语音处理转向了图像处理、视频处理,背后的模型变得越来越丰富,有RNN、CNN、LSTM、Transformer等等,对张量计算的要求非常高,所以我们给NPU又配置了一个张量加速器。到了2023年,随着生成式AI大热,对于大语言模型来讲,目前70%以上的大语言模型都是基于Transformer,所以我们专门针对Transformer进行了特定的优化和设计,同时我们在软硬件层面也提供了诸多先进技术,包括微切片推理。去年我们发布的第三代骁龙8移动平台,可以支持完整运行100亿参数以上的模型。
在今年2月份的MWC巴塞罗那上,我们也展示了高通在端测支持的多模态模型。另外,我们也会针对大语言模型的底座Transformer进行持续投入,从而更好地支持基于Transformer的大模型。从参数量级的角度来说,2024年以后我们将有望看到100亿参数以上的大模型在端侧运行,并带来较好的用户体验。
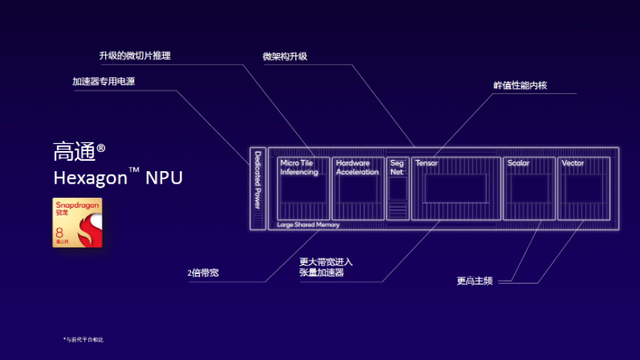
通过这张胶片,我将和大家具体讲解高通去年发布的第三代骁龙8移动平台在AI方面,特别是NPU与前代产品相比有哪些提升。第一,利用微架构升级提供极致性能;第二,手机作为一个集成度非常高的产品,其功耗一直都是需要重点解决的问题,因此我们给NPU设置了加速器专用电源,以提供更加出色的能效;同时,我们还升级了微切片技术,在算子深度融合层面充分释放硬件算力和片上内存。除此之外,其他的提升和改进还包括更大的带宽、更高的主频等,从而打造出拥有卓越AI性能和能效的SoC。接下来,我将给各位展示一个基于语音控制的虚拟化身AI助手,在这个典型案例中,异构计算的优势能够得到充分释放。
首先,ASR模块负责将用户的语音信号转成文本信息,这个模型是运行在高通传感器中枢上;输出的文本信息会输入到大语言模型中,这个大语言模型则运行在Hexagon NPU上;大语言模型输出的文本信息,再通过开源TTS模块处理成语音信息进行输出;因为它是一个虚拟化身形象,最后还需要渲染虚拟形象与用户互动,而渲染、互动的工作负载则是由Adreno GPU来完成。这就是虚拟化身AI助手在SoC上运行完成端到端处理的流程,异构计算的能力在这一过程中得到充分释放。
当然,高通除了提供领先的AI硬件之外,还能够提供一个灵活的跨终端、跨OS、跨平台的高通AI软件栈。从上往下看,我们支持包括TensorFlow和PyTorch在内的目前主流的AI训练框架。再往下看,我们也可以直接运行一些开源的AI runtime,同时,我们还提供一个高通自己的SDK——高通神经网络处理SDK,这也是我们可以提供给合作伙伴的一个runtime。
在更下层的接口,我们也会为开发者和合作伙伴提供丰富的加速库、编译器以及各种调试工具,让他们可以在高通骁龙平台上,更加高效、灵活地进行模型的优化和部署。
大家知道,高通有着非常丰富的产品线,我们不仅提供手机SoC,同时也涉足汽车、PC、物联网、XR等等领域,高通AI软件栈已经赋能我们所有产品线的绝大多数AI平台,也就意味着,我们的合作伙伴和开发者朋友们,只要在高通的一个平台上完成模型的部署,就可以非常方便地迁移到高通的其他产品线。
这里我提供了一些目前比较典型的用例和对应的参数量,可以看到,像文生图、对话和NLP、图像理解这些用例的模型参数量大概在10亿至100亿之间,正如前面我们介绍到的,高通已经实现了运行超过100亿参数的模型,并且,预计未来几年这一数字将大幅增长。
除了提供领先的硬件和灵活的软件之外,我们也在构建我们的AI生态系统,支持国内外的、广泛的终端侧生成式AI模型在骁龙平台上运行,其中既包括LVM、LLM,也包括多模态LLM,这里我就不一一列举了。如果大家感兴趣,可以访问我们的官网查看更多信息。以上就是我今天的全部分享,谢谢大家!
- 英伟达H20不让用?全国产算力推理模型升级,4张华为卡即可部署2025-04-22
- AI应用突围,中小企业的新周期已至2025-04-11
- GPT-4o能拼好乐高吗?首个多步空间推理评测基准:闭源模型领跑2025-04-23
- 飞猪AI意外出圈!邀请码被黄牛倒卖,分分钟搞定机酒预订,堪比专业定制团队2025-04-20