谢赛宁&Lecun团队新成果:首发以视觉为中心的多模态大模型
模型视觉能力up up
刚刚,谢赛宁&Lecun团队官宣新成果——
正式推出以视觉为中心的多模态大模型Cambrian-1!

模型名为“寒武纪”,谢赛宁本人激动表示:
就像在寒武纪大爆发中生物发展出更好的视力一样,我们相信视力的提高不仅意味看得更远,还意味更深入地理解。
一直以来,谢赛宁都在思考一个问题:
人工智能是否需要感官基础来提升理解能力?
从之前的项目(MMVP、V*、VIRL)中,他和团队注意到当前的多模态大模型(MLLM)存在意想不到的视觉缺陷。

虽然可以通过增加数据短暂解决问题,但根本问题是,当前的视觉表示还不足以理解语言。
基于CLIP和视觉SSL的模型已被证明是有效的,但它们也有自己的一系列问题。
CLIP/SigLIP模型很棒,但我们需要使我们的方法多样化,并不断探索新的可能性,而不是安定下来并声称胜利。

现在,“不求安定”的谢赛宁团队交出了最新答卷。
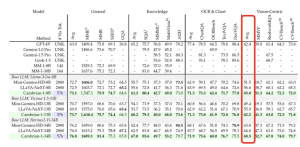
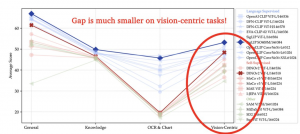
仅用四分之一的视觉标记,Cambrian-1性能显著优于miniGemini和LLaVA-Next等其他方法,且在以视觉为中心的基准测试中差距尤为明显。
有网友惊呼:
视觉模型的新时代即将开始
那么,团队具体如何构建这个新模型?接下来一起瞅瞅。
五大关键打造Cambrian-1
Cambrian-1是一系列以视觉为中心的MLLMs,围绕五个关键支柱构建。
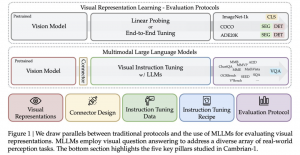
新测试基准CV-Bench
首先,团队引入了新的以视觉为中心的基准测试“CV-Bench”。
团队比较了使用23个不同视觉主干训练的MLLMs的视觉禁用和视觉启用设置之间的性能。
结果表明,当前大多数基准测试无法恰当评估以视觉为中心的能力,而那些能够做到这一点的基准测试往往样本数量有限。

为了解决以视觉为中心的基准稀缺问题,团队引入了CV-Bench,这是一个重新利用标准视觉任务进行多模态评估的基准,包含约2600个以视觉为中心的VQA问题。

MLLM作为视觉模型评估器
此外,Cambrian-1还被用作评估视觉模型的工具。
团队评估了多种视觉编码器及其组合,以确定哪些编码器能够提供最有效的视觉特征表示,从而优化MLLMs性能。
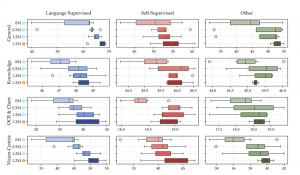
结果显示,CLIP模型不出意外名列前茅,而自监督学习(SSL)出现了几个值得关注的点。
- 解除视觉编码器的固定状态能够带来显著的性能提升,特别是在以视觉为中心的基准测试中,这一策略为SSL模型带来了更为明显的改进。
- 虽然语言监督在视觉表示学习中提供了显著的优势,但SSL方法在拥有充足数据和经过适当指令调整的情况下,同样能够实现追赶。
- 总体来看,SSL模型在视觉中心的基准测试中显示出良好的性能,并且能够与CLIP模型有效协同工作,这表明应持续推进视觉表示学习研究。

值得一提的是,由研究者wightmanr训练的ConvNeXt CLIP模型在当前的实验框架中表现出色。
其高分辨率编码器显著增强了图表和以视觉为中心的基准测试的性能,而基于ConvNet的架构天然适合处理视觉任务。
看到这一结果,谢赛宁满怀憧憬:
如果用我们的MLLM管道来评估timm库中的模型,这可能会带来一些非常令人兴奋的进展!
新连接器SVA
另外,为了优化视觉和语言信息的融合过程,团队引入了一种新的连接器设计——空间视觉聚合器(SVA)。
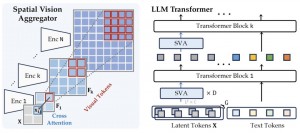
SVA基于两个原则设计:
- 空间归纳偏差的显式编码。这一策略允许模型在处理视觉信息时,能够更加精确地定位和整合局部特征,从而提高对空间结构的理解。
- 多阶段视觉特征聚合。在LLM的多个层次上,该方法执行了视觉特征的多次聚合,这使得模型能够在不同抽象级别上反复访问和利用视觉信息,增强了模型对视觉内容的深入分析和记忆能力。
这是一种动态的空间感知连接器,它将高分辨率视觉功能与LLMs集成在一起,同时减少了tokens数量。
谢赛宁特意强调:
SVA在寒武纪框架中至关重要,依靠简单的多层感知器(MLP)可能不足以完全挖掘优秀视觉数据的潜力
指令微调
在指令微调阶段,MLLM一般使用MLP作为连接器连接预先训练的LLM和视觉骨干网。
不过最近的研究建议跳过连接器预训练以降低计算成本(同时不影响性能)。
于是团队用不同大小的适配器数据进行了实验,遵循LLaVA的方法,最初仅微调连接器,然后解冻LLM和连接器。
结果表明,预训练连接器可以提高性能,而使用更多适配器数据可以进一步增强性能,所以团队采用1.2M适配器数据标准化2阶段训练方法。
指令调优数据集Cambrian-10M
最后,团队还推出了用于训练MLLM的指令调优数据集——Cambrian-10M,它整合了视觉问答、OCR数据及少量精选的纯语言指令数据。
在此基础上,团队顺带推出了更小但质量更高的7M精选版。

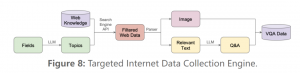
团队还针对性推出了一个互联网数据收集引擎。
有了数据,团队通过设置数据点数量的阈值来实现数据平衡,以优化模型性能。
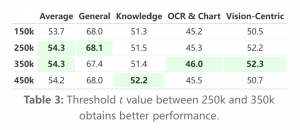
选定的阈值有150k、250k、350k和450k,研究表明在250k至350k之间的阈值对于Cambrian-10M数据集的性能最为有利。
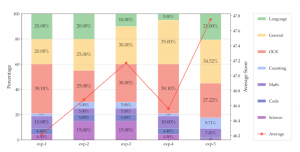
另外,鉴于不同类型的视觉指令调整数据具有不同的能力,团队在固定数据集大小为1350k的条件下,进行了试点实验。
结果显示:(1)平衡一般数据、OCR和语言数据至关重要。(2)知识密集型任务的表现受到多种因素的影响,通常需要结合OCR、图表、推理和一般感知。
在管理指令调整数据的过程中,团队观察到了一种“答录机现象”:
训练有素的MLLM可能在VQA基准测试中表现出色,但缺乏基本对话能力,并且默认输出简短响应。
这种差异的原因在于,基准测试问题通常只需要一个选项、选择或单词的回答,这与MLLM在更广泛和现实的应用场景中有所不同。
对此,团队通过在训练期间加入额外提示来减轻了这种现象。
比如下图左侧,带有系统提示的模型会在正确回答问题的同时,产生更长、更有吸引力的回答。
而且,系统提示还会通过鼓励一连串的思考,来增强模型在推理任务(如数学问题)上的表现。

完全开源
上述模型权重、代码、数据集,以及详细的指令微调和评估方法现已全面开源。

抱抱脸已有三种尺寸的模型(8B、13B和34B),团队将很快发布GPU训练脚本和评估代码。
谢赛宁还公开感谢谷歌对此研究提供了TPU支持。
据论文一作Shengbang Tong曾经的老师马毅教授透露:
这个模型是在过去几个月借谷歌的TPU训练的(等价于1000张A100的算力)。
最最后,对于Cambrian-1的出现,谢赛宁发出感慨:
这一情况让人想起2015-2016年,当时大家都认为ImageNet监督预训练天下无敌,其他视觉表征至少落后10-15%。
但是,研究人员们可没被吓倒,还是继续琢磨各种新方法和任务。
直到几年后,MoCo就展示了超越监督预训练模型的潜力。
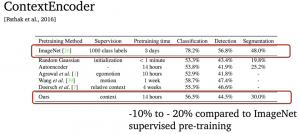
而这或许才是开发本项目的最大意义:

- 腾势N9以180km/h鱼钩测试成绩刷新世界纪录!中国SUV安全性能登顶2025-04-16
- 腾势登陆欧洲开启国际化新篇章,米兰设计周上演科技与美学盛宴2025-04-15
- 比亚迪划时代旗舰汉L唐L震撼上市,售价20.98万~28.98万元2025-04-15
- 支付宝推出“支付MCP Server”,魔搭、百宝箱等平台首发上线2025-04-15