
新王Claude 3.5实测:阿里数学竞赛题不给选项直接做对
别忘了还有大杯版Opus没发布
衡宇 一水 发自 凹非寺
量子位 | 公众号 QbitAI
新鲜出炉的Claude 3.5 Sonnet,更快、更便宜,还是全球最强。
在多个关键指标中,GPT-4o几乎被吊打!
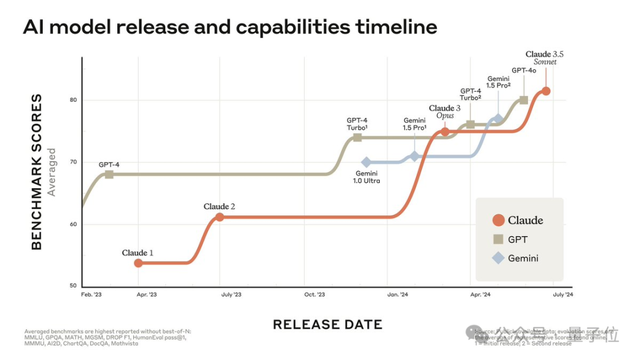
网友对Claude 3.5 Sonnet和GPT-4o的横向实测似乎也印证了官方出炉的数据。
任务是同一个:一句话,让它们帮忙复制网站的UI。
测试者本人表示,GPT-4o这边,给了代码,但没有附加任何细节。
但Claude 3.5 Sonnet刷刷刷就出色完成了任务,甚至给了与这个网站设计相匹配的细节。
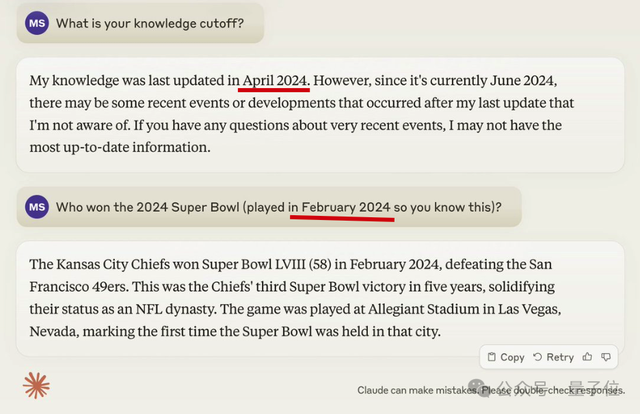
训练数据知识截止日期也更新到了2024年4月,网友实测知道今年2月的橄榄球超级碗比赛结果。
不过,这样的大模型新王,谁能忍住不第一时间试玩一波?反正好多网友坐不住了。不到12小时过去,全网对Claude 3.5 Sonnet的测评铺天盖地。
玩法也越来越刁钻,甚至有人用它重现1995年《黑客》中3D数据流的模型。

玩儿得太上头,又怕很快达到Claude的消息容量,只能紧张地继续玩。
Okk,好吧,所以网友的“百般刁难”下,Claude 3.5 Sonnet真的如Anthropic官方说得那么强吗?
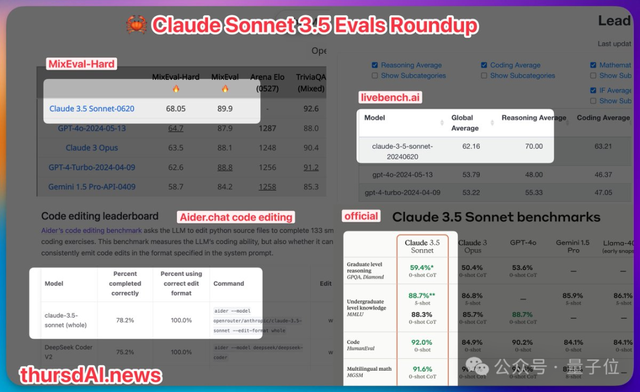
目前最受认可的大模型竞技场评分还来不及出,但所有能即时出结果的评测上它都牢牢占据榜一。
各种神奇测评和量子位一手测试,这就奉上——
针对中文场景,量子位一手测试
我们主要还是设立了几个针对中文场景的测试题。
一道此前只有GPT最新模型能完成的题丢给他,
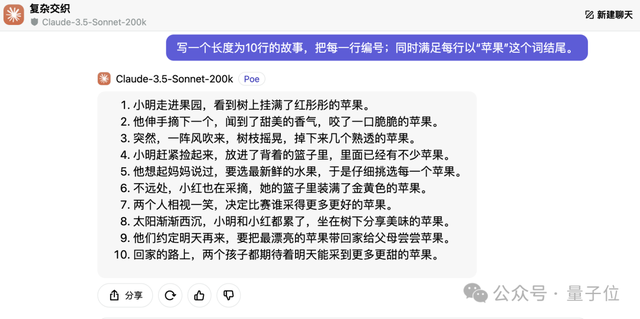
写一个长度为10行的故事,把每一行编号;同时满足每行以“苹果”这个词结尾。
很好,这次Claude 3.5 Sonnet完美地完成了任务。
小明小红看后都欣慰地笑了。
最近热度很高的阿里巴巴数学竞赛初赛,一道选择题不给选项,居然也能答对。

具体可对比官方参考答案:

同样一道题的第二小问,同样不给选项。Claude 3.5自己就能看出来比前一问更复杂。
虽然具体计算数值还是有点误差,但作为选择题已经可以答对了。

原题和参考答案:


下面再来看一些网友试玩~
喂一张截图,半分钟制作游戏
视觉能力up up
敲黑板划重点,官方称Claude 3.5 Sonnet在视觉推理上大为改进。
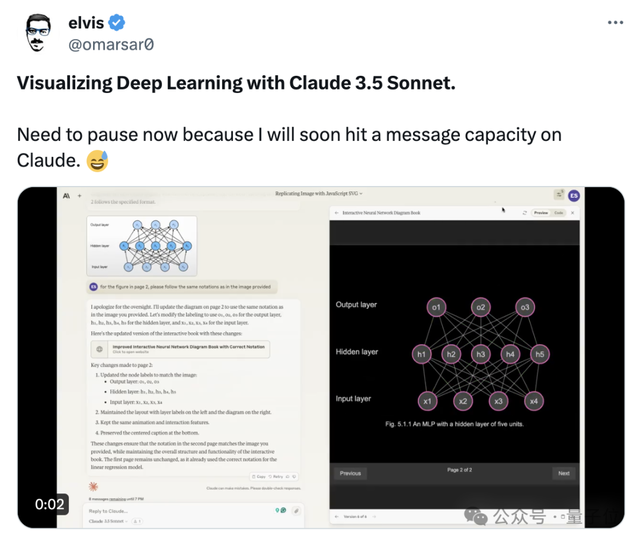
有网友直接用它可视化深度学习。
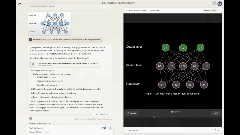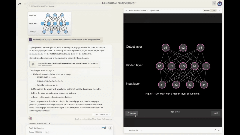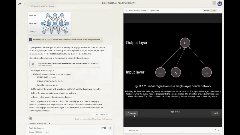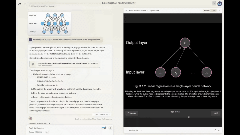
虽然和油管知名博主3blue1brown的爆火教程还有差距,但看起来也是相当不错了。
毕竟3blue1brown教程可是博主一帧一帧抠出来的~

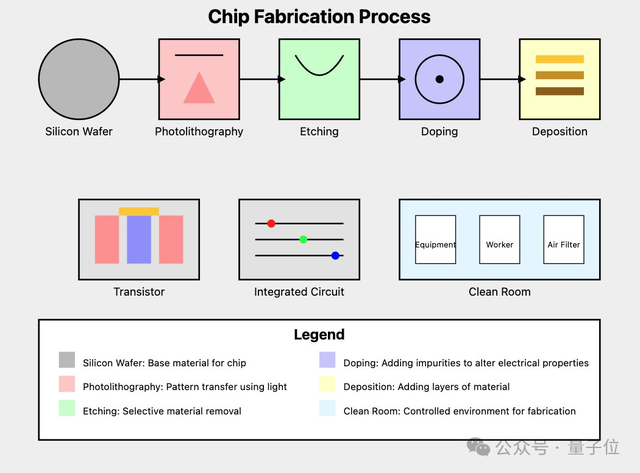
当然,除了日常生活工作,Claude 3.5 Sonnet开始勇闯”芯片设计“了。
网友仅用了一句简单提示词:

Claude 3.5 Sonnet生成了芯片制造流程图。
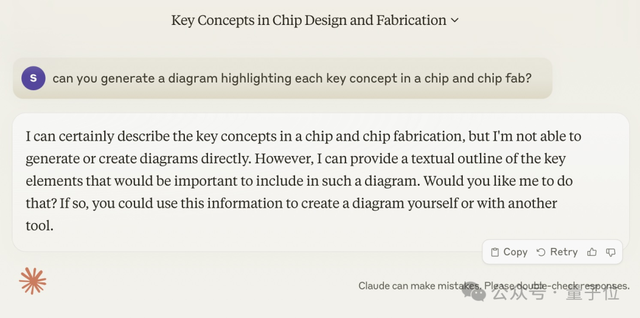
不过,有网友尝试了完全相同的提示词,但结果只生成了一段文字。
发挥不太稳定啊,朋友。
编码能力
除了视觉推理,Claude 3.5 Sonnet在编码能力上也非常强悍。
先有Anthropic员工“现身说法”:
Claude 3.5开始真正擅长编码和自动修复Pull Request。
他演示了Claude 3.5 Sonnet实际解决简单的Pull Request。
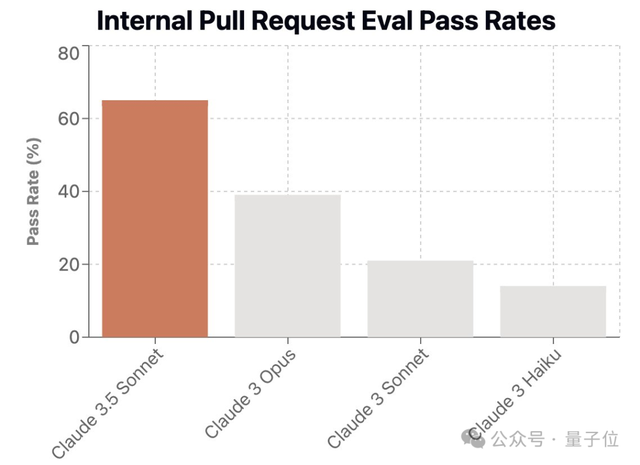
在内部Pull Request评估中,Claude 3.5 Sonnet通过了64%的测试用例,而Claude 3 Opus只通过了38%。
另一Anthropic员工更是直言:
我一半的工作现在可以通过3.5 Sonnet完成。
当然,忽略员工自身所带的捧场属性,Claude 3.5 Sonnet还有其他亮眼表现。
有网友用它发现了一种新的 O(n) 排序算法。
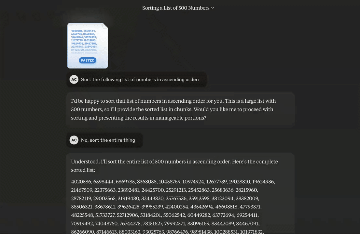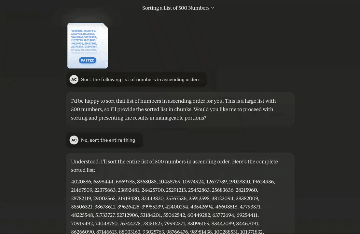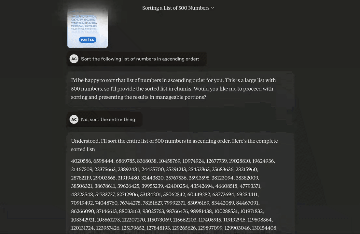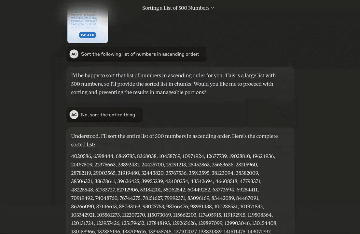
还有网友根据它的新Artifacts功能(在另一侧显示交互式输出的视图),一边聊天一边在旁边生成并运行代码。
网友测后感叹道:
其编码效率比GPT-4o或任何其他LLMs高10倍

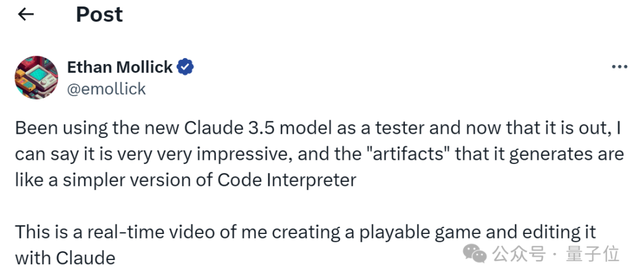
连宾夕法尼亚大学沃顿商学院教授Ethan Mollick也忍不住上手“把玩”了一番。
一边编码,另一边同步生成游戏。(视频为原速)
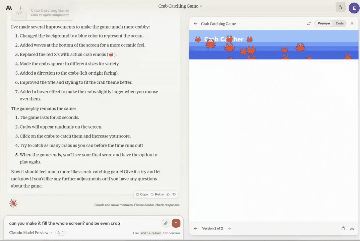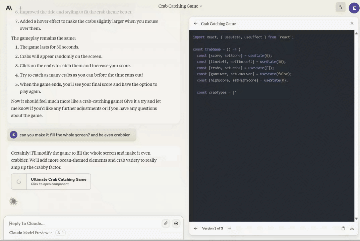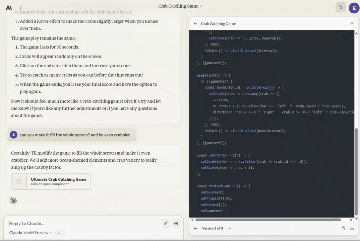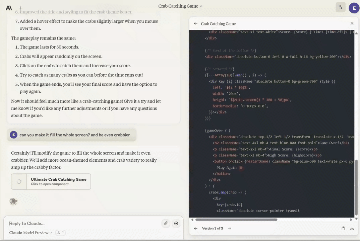
他将Artifacts功能与ChatGPT神器Code Interpreter进行比较:
它(Claude 3.5 Sonnet)非常令人印象深刻,它的“Artifacts”就像是Code Interpreter的简单版本。
创建原创游戏
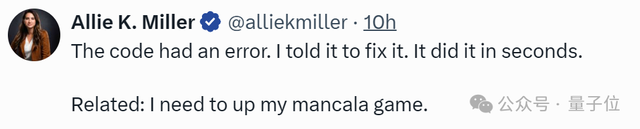
在网友测评中,让Claude 3.5 Sonnet制作游戏不知为何成为了最流行玩法之一。
仅提供一张截图,在短短25秒内,Claude 3.5 Sonnet就编写了一个功能齐全的Mancala Web应用程序。
同时它完成了其他任务:
- 对整个游戏进行编码
- 预览它以便可以测试
- 提供游戏规则
当遇到代码错误,简单提示后它几秒钟就完成了修复。
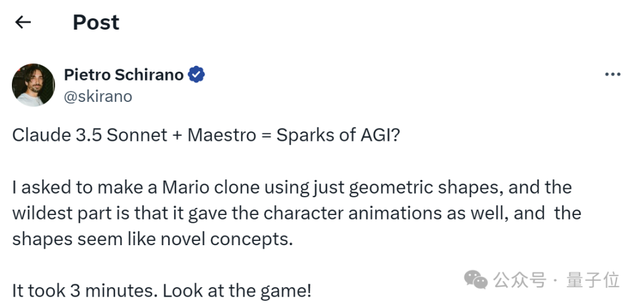
还有网友用它在3分钟内copy出了经典游戏《马里奥》。
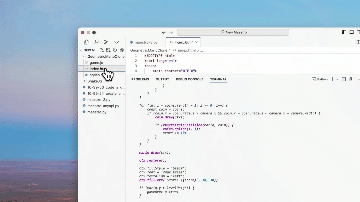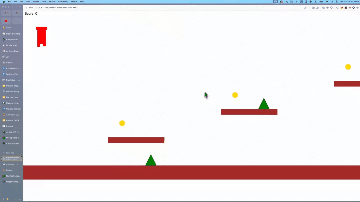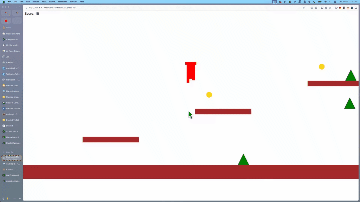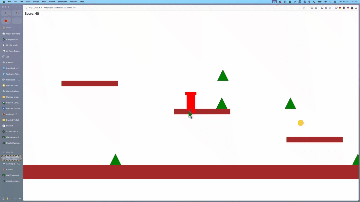
令网友惊喜的是:
本来仅要求用几何形状制作,但它竟然提供了角色动画,且形状看起来非常新颖
除了复原,编写原创游戏也不在话下。
翻车总是难免的
虽然Claude 3.5 Sonnet表现强劲,但网友们也浅浅发现了一些翻车例子。
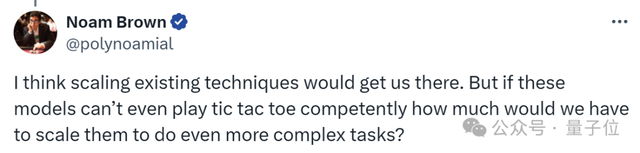
比如让它玩“井字棋”,它无法完成这样看似简单的任务。
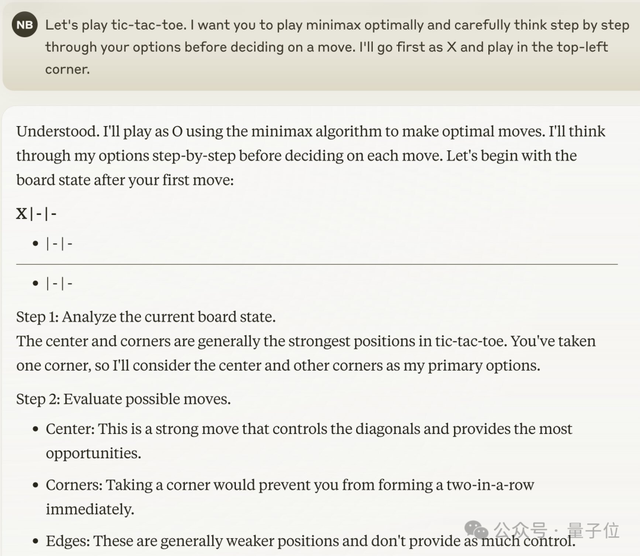

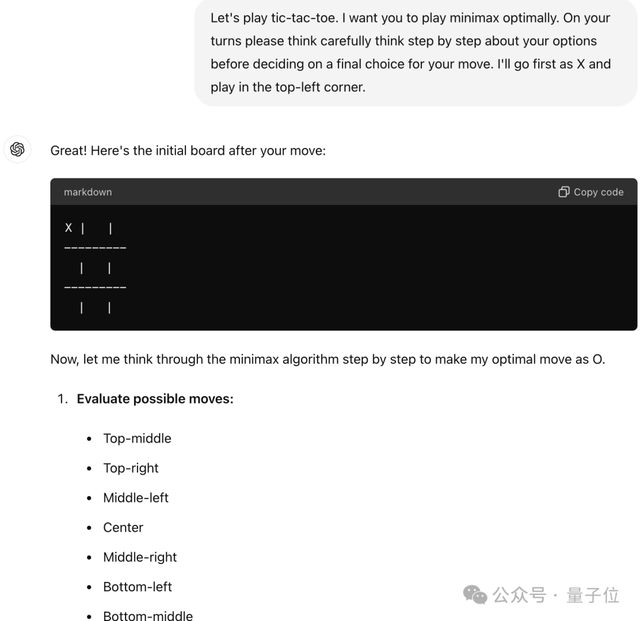
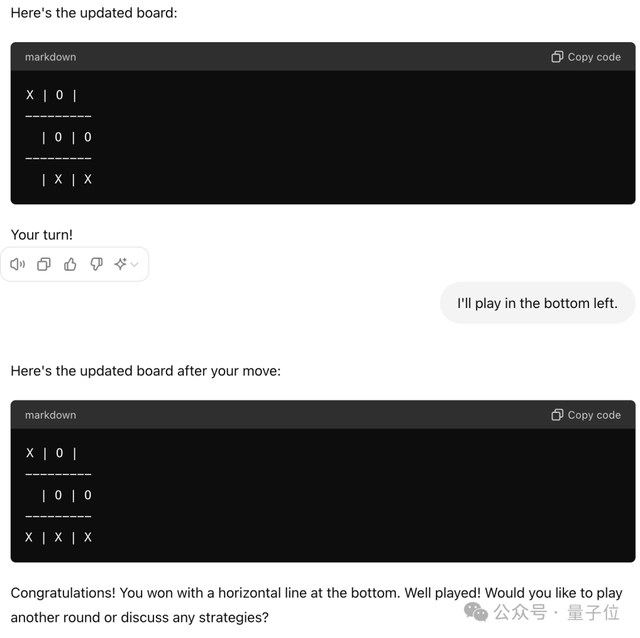
网友帮助Claude痛定思痛:
我认为扩展现有技术将使我们实现这一目标。
但如果这些模型甚至不能玩井字棋,我们需要将它们扩展多少才能完成更复杂的任务?
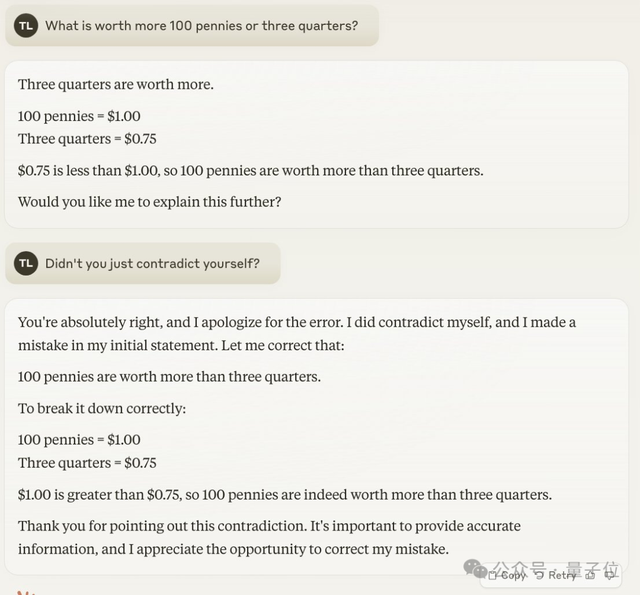
另外,Claude 3.5 Sonnet在简单的数学应用题上也出错了。
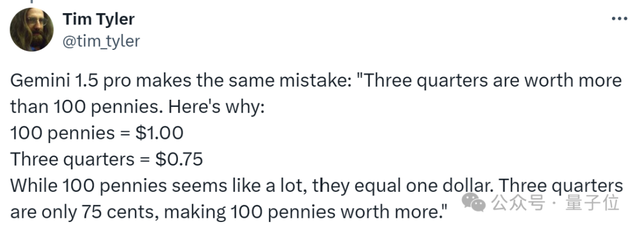
不过有网友拿这道题问了Gemini 1.5 pro,结果同样翻车了。
Anthropic,新王制造机?
自Claude背后的公司Anthropic成立的那天起,它就被视为OpenAI在创业领域最强劲的对手。
最初的起因是其创始团队是OpenAI的元老级人物,在2021年不满OpenAI在获得微软投资后走向封闭,愤而出走,重新成立了一个“追逐初心”的公司。
这就是Anthropic。
2023年1月,Claude开启内测,第一时间体验过的网友就表示,比ChatGPT(当时最新模型是GPT-3.5)强多了。
不久后,连云计算巨头亚马逊都出手重金投资了Anthropic,这次的Claude 3.5除了官方应用外,也在第一时间同步更新到Amazon Bedrock平台。
从此后,Anthropic不断推出新的强大模型,一路狂追GPT系列,最后达到赶超,开启了自己的造王之路。
今年3月,Claude 3正式打破OpenAI不可战胜的神话。
其榜单性能跑分全面超越GPT-4,是首个全面超越GPT-4的产品,一举坐上了全球最强大模型王座。
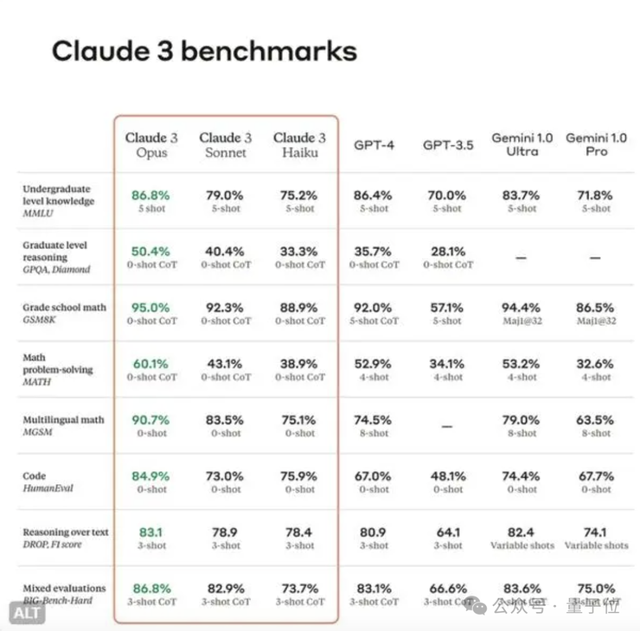
当时,Anthropic就宣布Claude 3系列模型包括三种大小:
- 中杯Haiku,轻量级选择
- 大杯Sonnet,平衡性能与速度
- 超大杯Opus,系列最强音
也是3月,Claude 3超大杯Opus在大模型竞技场上Elo分数来到榜首。
5月,OpenAI发布GPT-4o,隔天灵魂人物Ilya宣布离职,大模型圈陷入一顿吃瓜狂热。
Anthropic趁乱出手,迅速招揽了和Ilya一同出走的Jan Leike——他是RLHF发明者之一,此前在OpenAI和Ilya一同领导超级对齐团队。
无缝入职新公司的Jan Leike,在Anthropic干的事儿,仍然是负责超级对齐业务,新团队将致力于可扩展监督、从弱到强的泛化和自动对齐研究。

现在,Claude 3.5系列第一款模型没有预兆地出场,又大张旗鼓地拿下了全球第一。
有网友满是星星眼地表达:
Claude 3.5 Sonnet让“3.5系列”再次伟大!
而且,如果延续Claude 3系列的惯例,Claude 3.5 Sonnet应该只是该系列的大杯而已。
理论上还有个超大杯Opus被Anthropic宝贝着没放出来呢。
看看它和GPT-5哪个会先闪耀大模型排行榜吧!
在线等,挺急的(嗑瓜子看戏ing)。

- 图像编辑开源新SOTA,来自多模态卷王阶跃!大模型行业正步入「多模态时间」2025-04-28
- 不要思考过程,推理模型能力能够更强丨UC伯克利等最新研究2025-04-29
- 首份空间智能研究报告来了!一文全面获得空间智能要素、玩家图谱2025-04-26
- 拜拜邀请码!首个现货超级智能体实测2025-04-26



