CVPR最佳论文被生成式AI占领,清华武大华南农大上科校友获奖
规模空前,受关注度空前
梦晨 西风 发自 凹非寺
量子位 | 公众号 QbitAI
CVPR 2024最佳论文奖新鲜出炉,生成式AI成最大赢家!
一篇是Rich Human Feedback for Text-to-Image Generation,受大模型中的RLHF技术启发,团队用人类反馈来改进Stable Diffusion等文生图模型。
这项研究来自UCSD、谷歌等,共同一作华南农业大学校友Youwei Liang、清华校友Junfeng He、武大、港中文校友Gang Li。

另一篇Generative Image Dynamics更偏理论一些,提出了一种基于图像空间先验的场景运动建模方法,可用于通过静态图像生成无缝循环视频,还能实现与图像中对象的交互。
这项研究来自谷歌,一作谷歌DeepMind研究员Zhengqi Li(李正奇)。

最佳学生论文奖也一同公布。
一篇BioCLIP: A Vision Foundation Model for the Tree of Life,构建了大规模生物学图像数据集,并提出BioCLIP基础模型来学习生物分类的层次表示。
来自俄亥俄州立大学等,共同一作Samuel Stevens,Jiaman Wu。

另一篇是3D高斯泼溅领域的Mip-Splatting: Alias-free 3D Gaussian Splatting,通过引入3D平滑滤波器、用2D Mip滤波器替换2D膨胀滤波器来消除伪影和混叠等问题。
来自图宾根大学、上海科技大学等,三位一作Zehao Yu、Anpei Chen(陈安沛)、Binbin Huang皆为上海科技大学在读或毕业生。

今年CVPR的参与规模和受关注度都达到了新高度,在颁奖活动结束后不久,官网就被挤爆了……
今年CVPR共收到投稿11532份,比上年增加25%,其中2719篇论文被接收,接收率为23.6%,竞争非常激烈。
接下来一起看看获奖论文是如何脱颖而出的。
最佳论文
Rich Human Feedback for Text-to-Image Generation
论文作者来自加利福尼亚大学圣地亚哥分校、谷歌研究院、南加州大学、剑桥大学、布兰代斯大学。
当前文本生图模型生成的图像仍存在失真、与文本不匹配、美学质量差等问题,而现有评估指标如IS、FID等无法反映单个图像的质量细节问题。
先前一些工作尝试采集人类偏好或评分作为反馈,但仍然是单一的整体得分,缺乏可解释性和可操作性。因此,作者提出了收集丰富的细粒度人类反馈信息,用于更好地评估和改进生成模型。
作者用Stable Diffusion生成的Pick-a-Pic数据集筛选了18K张图像,之后收集了“标注文本描述中与图像不匹配的关键词”、“标记图像中的失真/不合理区域”等人类反馈信息。每张图像由3人独立标注,通过平均/投票等方式合并得到最终反馈标签。
之后,设计了一种基于ViT和T5X的多模态Transformer模型RAHF,使用三种预测器预测上述丰富的人类反馈信息:
- 使用卷积层和上采样层预测失真和不匹配的热力图
- 使用卷积层和全连接层预测4个方面的评分
- 使用Transformer解码器生成带有特殊token的文本序列,标识不匹配的关键词
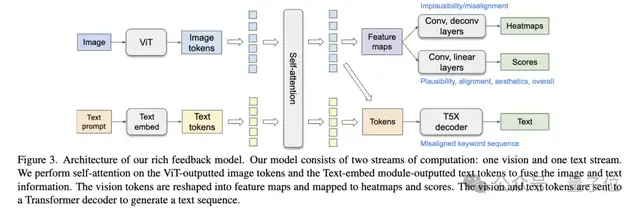
实验中,RAHF模型在多个任务上显著优于基线模型,如ResNet-50和CLIP。
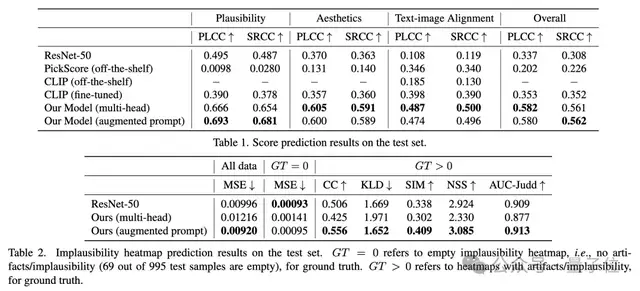
此外,作者还探索了三种利用RAHF预测的丰富反馈来改进文本到图像生成模型Muse方法。
使用预测的质量评分筛选优质数据微调Muse模型,生成图像的质量前后对比如下:

使用预测的失真热力图生成掩码区域,在该区域内对Muse生成图像进行局部修补,减少了生成图像的失真问题:

Generative Image Dynamics
论文作者来自谷歌研究院。
自然界中的场景总是在运动,即使是看似静态的场景也会因为风、水流、呼吸等而产生微妙的振荡。
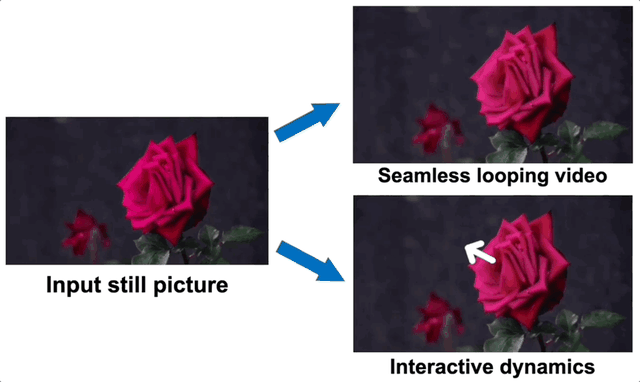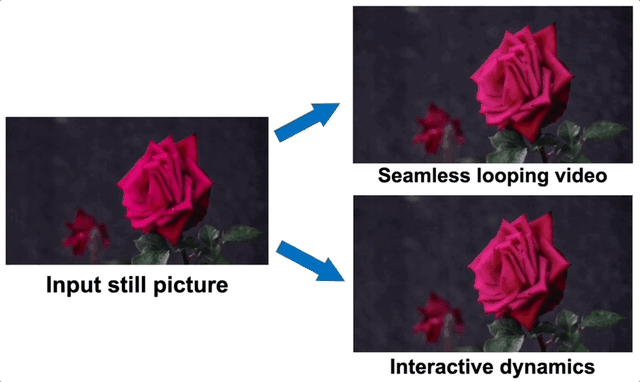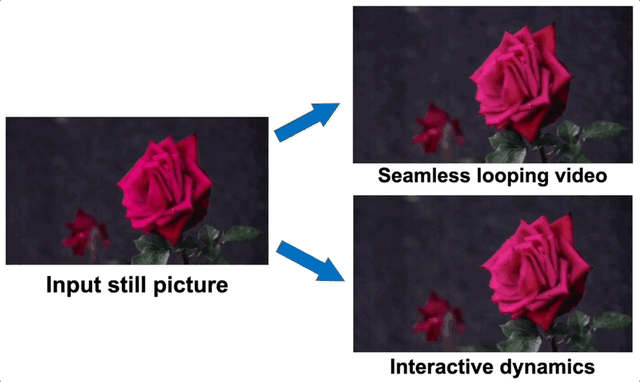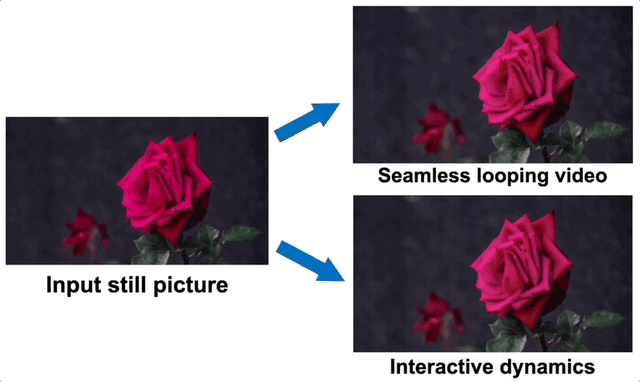
论文提出了一种从单张静态图像生成自然振荡动画的新方法,而且支持用户与图中物体进行交互:
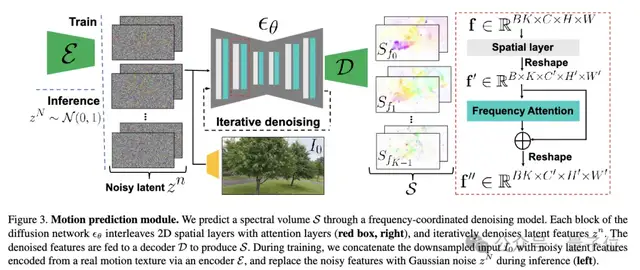
团队发现自然场景中的振荡运动,如树叶摆动等,主要由低频分量组成,因此引入了谱体积作为运动表示,即对视频序列中提取的像素运动轨迹进行傅里叶变换得到的频域表示,只需少量的低频傅里叶系数即可保留大部分运动信息。
然后,作者采用潜变量扩散模型从输入图像预测谱体积,并提出了频率自适应归一化和频率协调去噪两种策略来提高预测质量。
最后,将预测的谱体积通过逆傅里叶变换转化为运动纹理,并设计了一种基于图像的渲染模块,将输入图像按预测的运动轨迹进行前向渲染,最终生成展现自然振荡运动的动画视频序列。
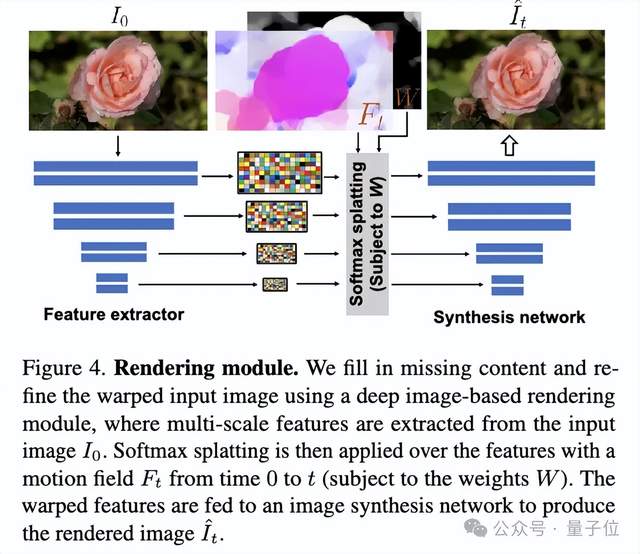
结合基于图像的渲染模块,这些轨迹可以用于多个应用场景,例如将静态图像转换为无缝循环的视频,或者通过将光谱体积解释为图像空间模态基底,近似物体动态,让用户能够与真实图片中的物体进行逼真的交互。
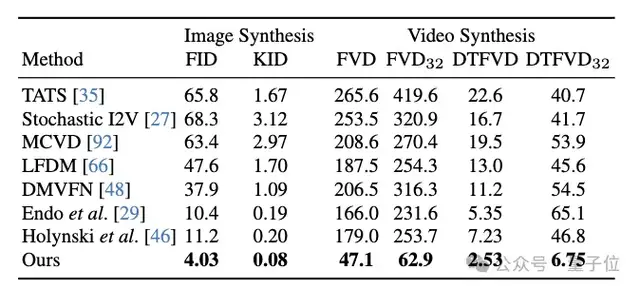
作者从定量和定性两方面评估生成视频的质量,结果显示该方法明显优于基准:

最后再来看一下效果:

最佳学生论文
BioCLIP: A Vision Foundation Model for the Tree of Life
论文作者来自俄亥俄州立大学、微软研究院、加利福尼亚大学欧文分校、伦斯勒理工学院。
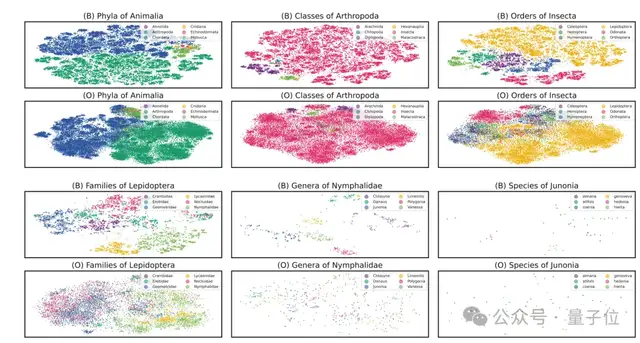
他们构建了一个大规模生物学图像数据集TreeOfLife-10M,包含1040万张图像,覆盖454103个生物物种,并提出了BioCLIP模型,利用CLIP式的多模态对比学习目标,结合生物学分类层次结构用TreeOfLife-10M数据集预训练模型。
使用该方法可很好地捕获生物分类体系的层级结构,从而实现对看不见类别样本的泛化能力。
Mip-Splatting: Alias-free 3D Gaussian Splatting
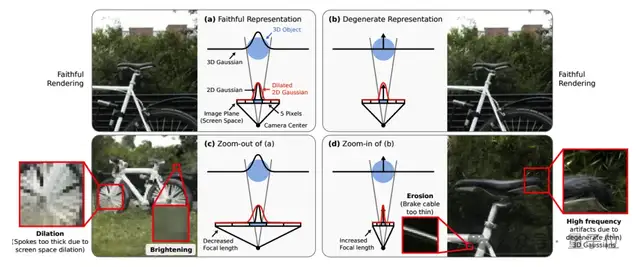
3D高斯溅射展示了令人印象深刻的新颖视图合成结果,达到了高效率和高保真度。然而,当改变采样率时,例如通过改变焦距或相机距离,可以观察到强烈的伪影。
团队发现这种现象的根源可归因于缺乏3D频率约束和2D膨胀滤波器的使用。
为了解决这个问题,团队引入了一个3D平滑滤波器,根据输入视图引起的最大采样频率来限制3D Gaussian primitive的大小,从而消除放大时的高频伪影。
此外,用模拟2D盒式滤波器的2D Mip滤波器替换2D膨胀滤波器,可以有效缓解混叠和膨胀问题。
团队还提供了在线演示,感兴趣的可以玩起来了。
https://niujinshuchong.github.io/mip-splatting-demo/
最佳论文:
https://arxiv.org/abs/2312.10240
https://generative-dynamics.github.io
最佳学生论文:
https://arxiv.org/abs/2311.16493
https://arxiv.org/pdf/2311.18803
参考链接:
[1]https://x.com/CVPR
[2]https://x.com/PauloFagundesIA/status/1803446527752278425