
大模型理解复杂表格,字节&中科大出手了
实现多个任务、多种源信息的整合协作
允中 发自 凹非寺
量子位 | 公众号 QbitAI
只要一个大模型,就能解决打工人遇到的表格难题!
字节联手中科大推出了一款统一表格理解大模型,可以以用户友好的方式解决多种表格理解任务。
同时提出的还有一套开源测试基准,可以更好地评估模型在表格理解任务上的表现。
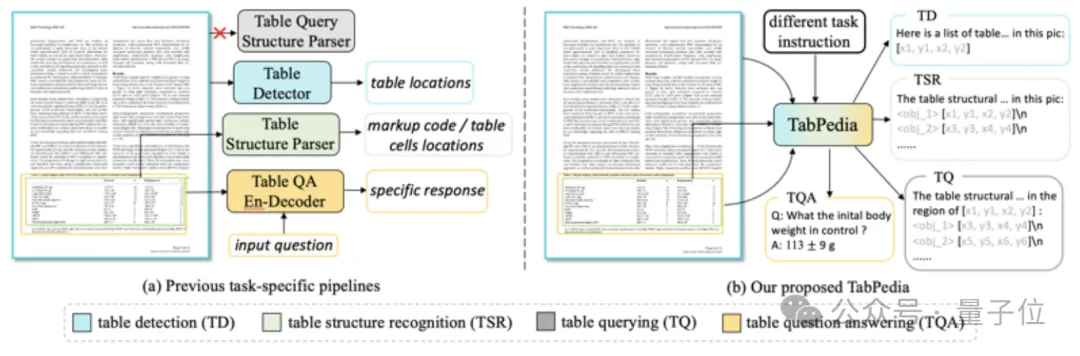
该模型名为TabPedia,利用多模态大模型,将不同处理表格任务的专有模型进行了整合。
在这之前,不同的任务都有独立的模型和解决方案,单是找到适合的模型就是已经很让人头疼。
而TabPedia通过概念协同 (Concept Synergy)机制来实现多个任务、多种源信息的整合协作,打工人再也不用为找模型而烦恼了。

那么,这款新模型都能实现怎样的效果呢?
无需裁剪识别多表格结构
首先来看,在测试数据集上,TabPedia可以在不借助后处理算法的条件下,精准识别表格位置并直接生成无重叠的检测框。
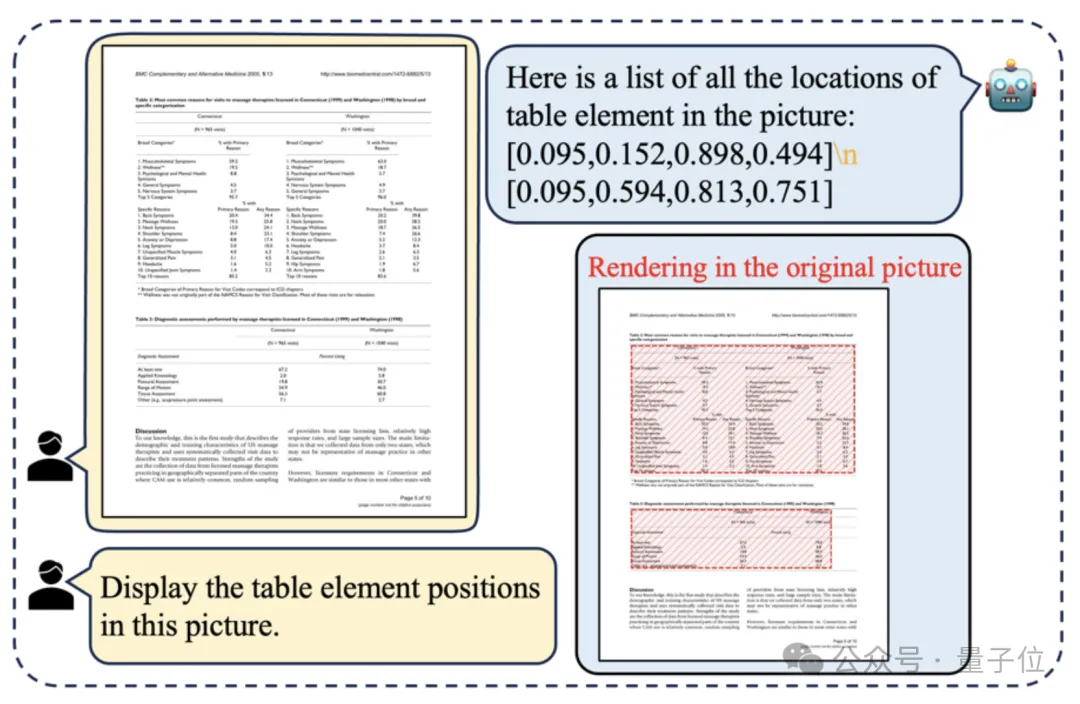
在判断出表格位置的基础之上,对于表格结构识别任务,TabPedia可以继续生成一系列连续的表格结构元素以及相应的检测框。
不仅判断准确,还有效地解决了标记语言(HTML或者Markdown)处理空间坐标的不足和非法语法潜在造成解析错误的弊端。
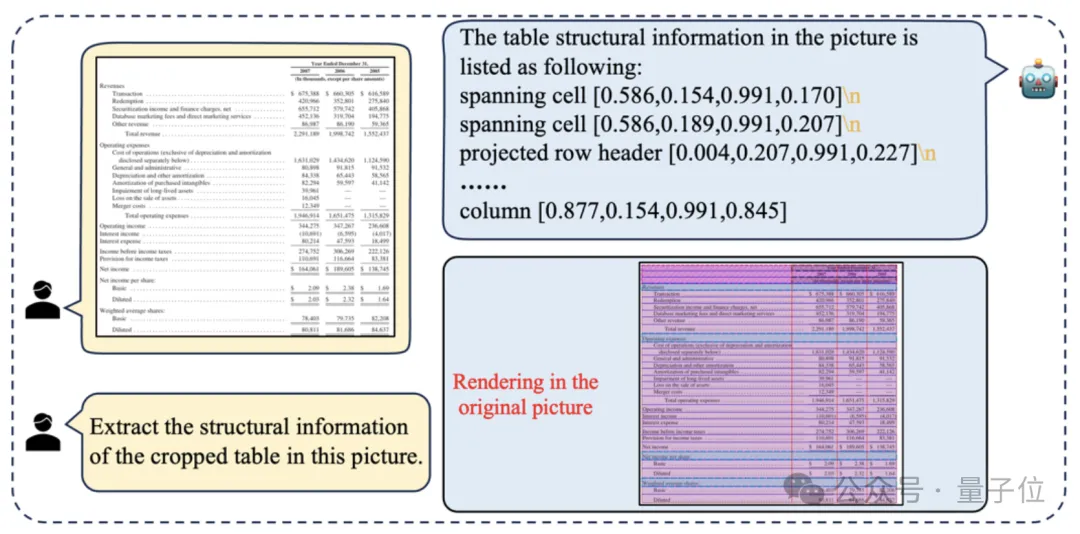
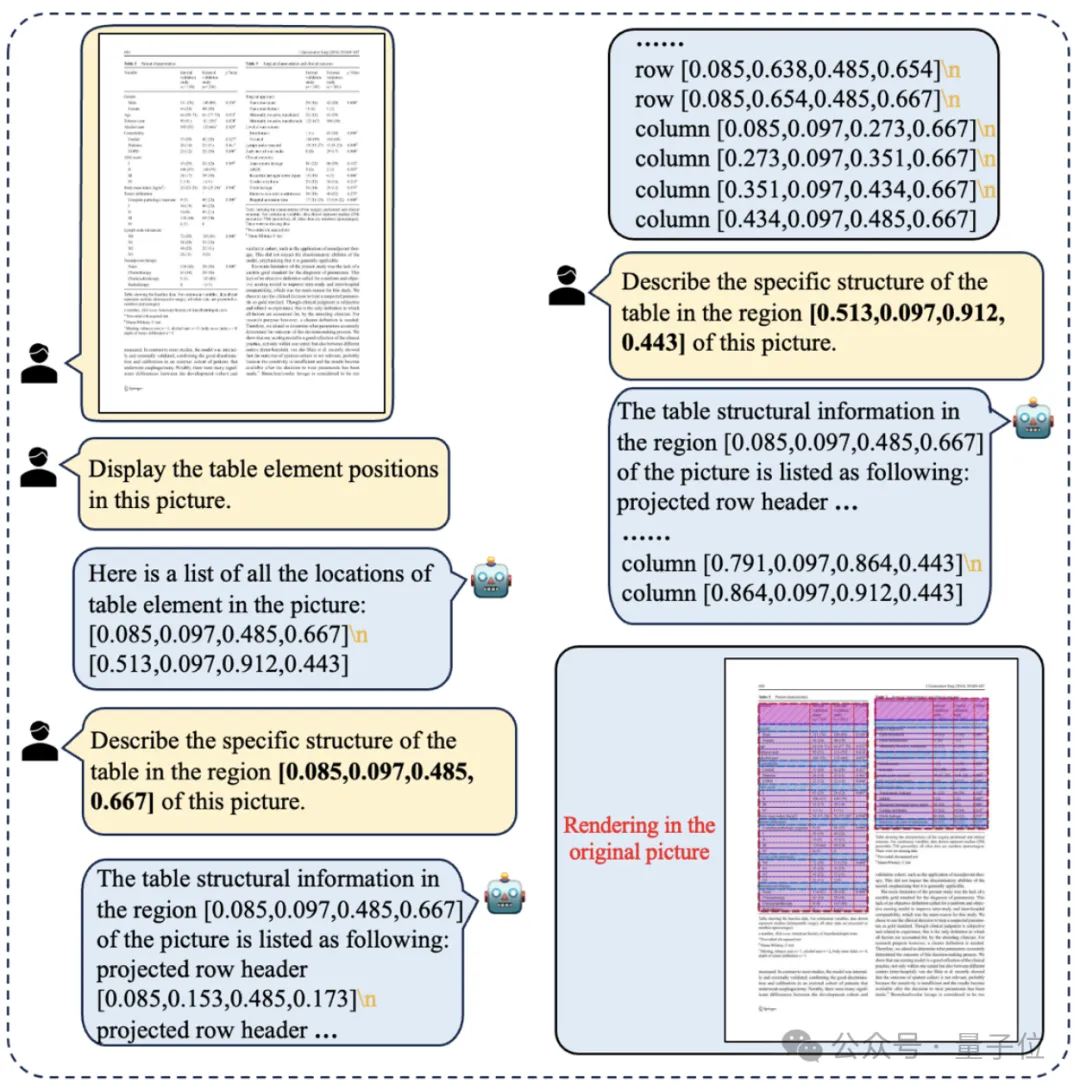
而且不再需要将表格从图片中手动裁剪,研究者们借助大模型的理解能力,让模型可以直接在原始文档图像中实现多表格实例的表格结构识别。
值得一提的是,此类任务是由TabPedia团队的作者首次提出的。
当然,只识别表格的位置和结构是远远不够的,而对于表格问答任务,TabPedia不仅可以给出正确的答案,同时还能基于表格的内容给出相应的理由。
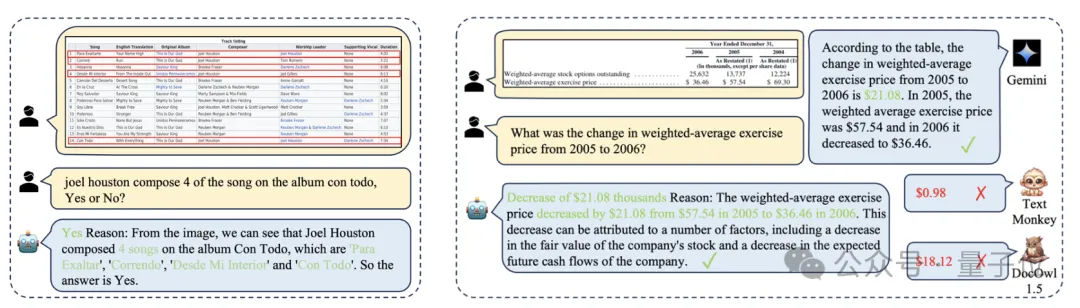
实战方面,面对多种不同的开放场景,TabPedia同样表现优异。
比如在论文中的表格检测任务当中,TabPedia可以准确地检测出图像中的所有表格实例。

对于表格结构识别能力,研究者们随机选取了不同论文中的表格图像,对于包含密集文本信息的表格结构,依然预测出准确的结构信息。
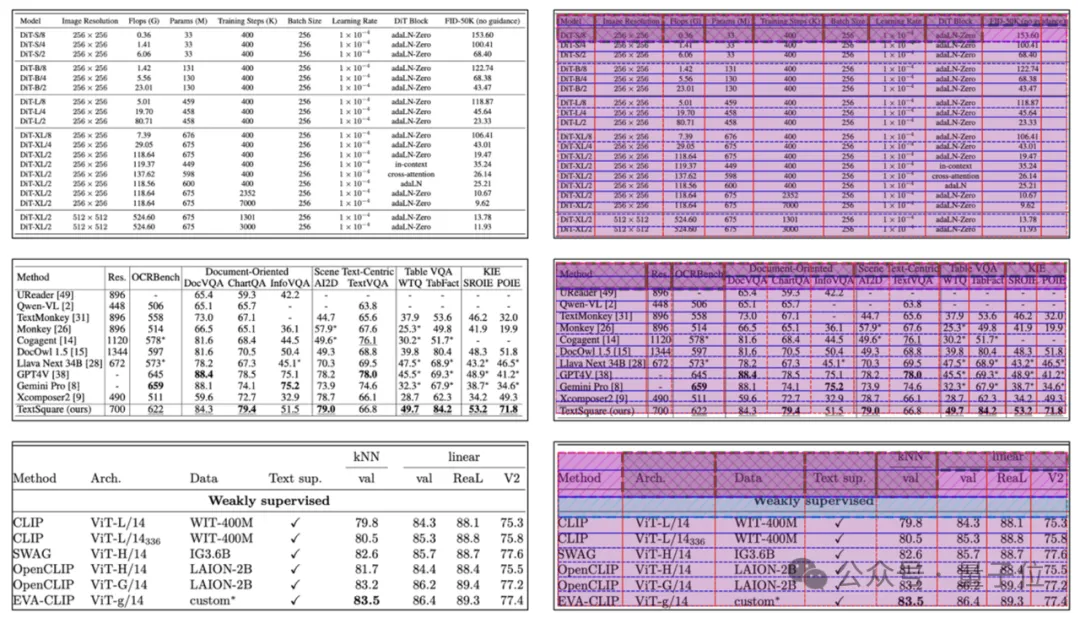
而在问答任务上,TabPedia仍然可以像在数据集测试中一样,根据表格内容和表格结构信息,做出合理且正确的回答。
此外,为了更好地评估各种模型在现实世界表格图像上的TQA性能,作者还构建了一个复杂的TQA数据集(ComTQA)。
与现有的基准WTQ和TabFact相比,ComTQA具有更具挑战性的问题,例如多个答案、数学计算和逻辑推理。
通过专家标注,作者们从大约1.5k张图像中注释了约9k个高质量的表格问答对。该数据集的标注目前已经在Huggingface开源。

那么,TabPedia具体是如何实现的呢?
高低分辨率分别训练
如下图所示,TabPedia包含两个视觉编码器以及各自的映射层,一个分词器以及大语言模型。
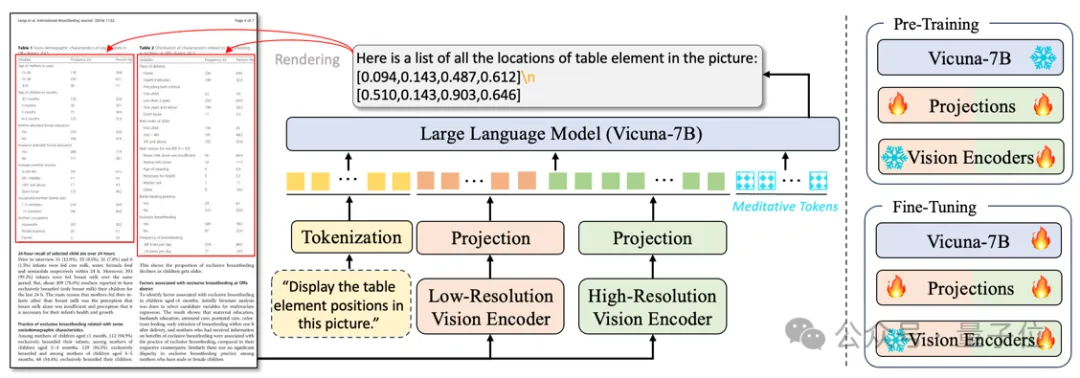
在预训练阶段,TabPedia主要学习如何对齐视觉表征和语言模型的输入空间;在微调阶段,TabPedia进一步专注于视觉表格理解。
其中,高分辨率视觉编码器用于2560×1920的高分辨文档图像,可以提供丰富的细粒度视觉信息;
低分辨率视觉编码器为了保持整图的结构信息,编码224×224的低分辨图像。
为了更好地让语言模型理解视觉信息,该工作沿袭了主流多模态大模型的对齐策略,设计了两个简单的映射层。
对于高分辨率支路的映射层,TabPedia采用2D的卷积层来聚合近邻的视觉特征,同时有效地缓解视觉token数量冗余的现状。
给定大量的视觉tokens以及文本指令的嵌入特征,TabPedia采用Vicuna-7B作为语言模型生成回答。
考虑到表格感知和理解任务之间的差异,TabPedia引入了Meditative Tokens M 来实现概念协同机制,它可以自适应地激活不同区域的视觉tokens,并理解特定任务问题的意图。

由于TabPedia和其它LLMs一样执行next token预测,因此仅需要简单的交叉熵损失函数作为目标函数来优化整个框架。
通过预训练,TabPedia能够很好地理解各种文档图像的文本和结构,但无法根据指示执行不同的表格理解任务。
为了增强模型的指令跟随能力,该工作首先构建了一个用于视觉表格理解的大规模数据集。
基于该数据集,研究者引入了四个与表格相关的任务,即表格检测,表格结构识别,表格查询以及表格问答,来同步执行感知和理解任务。
在该阶段,LLM也参与训练微调,进一步增强大模型的指令跟随和视觉信息抓取的能力。
开源数据集与合成数据共同训练
数据方面,TabPedia的全部数据来源于五个公开的表格数据集,包括PubTab1M、FinTabNet、 PubTabNet、WikiTableQuestions(WTQ)和TabFact,具体的数据使用情况如下图所示:
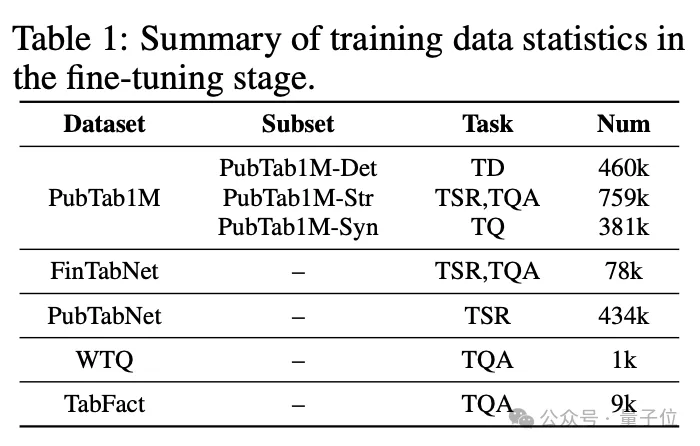
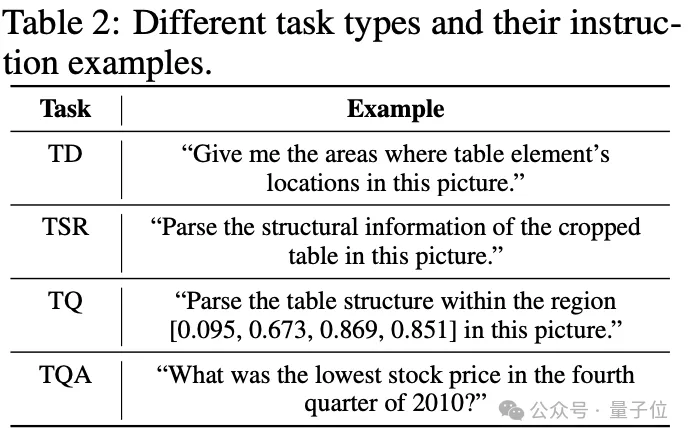
同时,对于不同任务的指令设计,作者也给出了对应的示例以便模型更好地理解。
其中最值得注意的是,表格检测和表格结构识别的任务摆脱了之前繁琐的后处理的弊端,TabPedia直接可以预测无重叠的检测框,高效率地输出用户需要的答案。
除此之外,研究者们进一步借助大模型的理解能力,克服之前工作需要将表格从原文档中裁剪出来做结构识别的流程,直接在原文档图像中实现多表格实例的表格结构识别。
该任务为利用大语言模型实现更复杂的表格理解奠定了强有力的基础。
对于表格问答任务,现有的数据绝大多数是基于文本的表格中生成的,仅在背景颜色和字体大小存在变化,导致在现实世界的表格中泛化能力较差。此外,TQA数据的量级远远落后于其他任务。
为了克服这些障碍,研究者们利用开源多模态大模型,基于FinTabNet和PubTab1M中部分图像数据生成了大量的TQA数据。
另外作者表示,尽管TabPedia已经在视觉表格理解展现出强大的能力,仍然有很多未解决的挑战激发研究者更深入的探索:
- 对于扭曲表格无法准确的理解和识别。该能力不足一方面源于训练数据的不足,另一方面是对于表格结构的表示采用了规则的矩形框。
- 目前的表格问答仍需要table-centic图像,如何将其迁移到在原始文档图像直接问答也是一项挑战性的工作。
- 增加表格单元格内容识别可以提升模型对于表格内容的理解以及细粒度信息的抓取能力。
总体来说,视觉表格理解任务依然有很多技术难点等待攻克。TabPedia初步探究了多模态大模型的表格理解能力,作者希望能对大家的研究有所帮助。
论文地址:
https://arxiv.org/abs/2406.01326
ComTQA数据集:
https://huggingface.co/datasets/ByteDance/ComTQA
- 数势科技发布SwiftAgent 3.0:大模型驱动的“分析-决策-行动”全链路闭环2025-04-18
- 移动通信领域有了新SOTA:华为出品,精准预测用户行为2025-04-04
- GPT-4.5创造力比GPT-4o弱!浙大上海AI Lab发布新基准,寻找多模态创造力天花板2025-04-04
- 3小时输出27个知识点!张朝阳跨年演讲硬核解析生活中的量子力学2025-01-13



