
理想暴雨测智驾,端到端+VLM上车,车主:求更新!
“领先无图一个时代”?
一凡 发自 副驾寺
智能车参考 | 公众号 AI4Auto
「自动驾驶」的上限有多高?
李想用一段视频回答了这个问题。
在宣布三年高考…啊不是,在宣布“三年L4,明年L3”后,李想再度发声谈自动驾驶,分享了团队的最新进展,还特别强调了背后的技术范式:
端到端+VLM (视觉语言模型)。
暴雨测智驾,效果挺意外
刚刚,李想发布了一段理想测试智驾系统的视频。
可以看到,即使在暴雨中,显示的车道线仍然非常清晰,系统还对场景情况进行了简述。
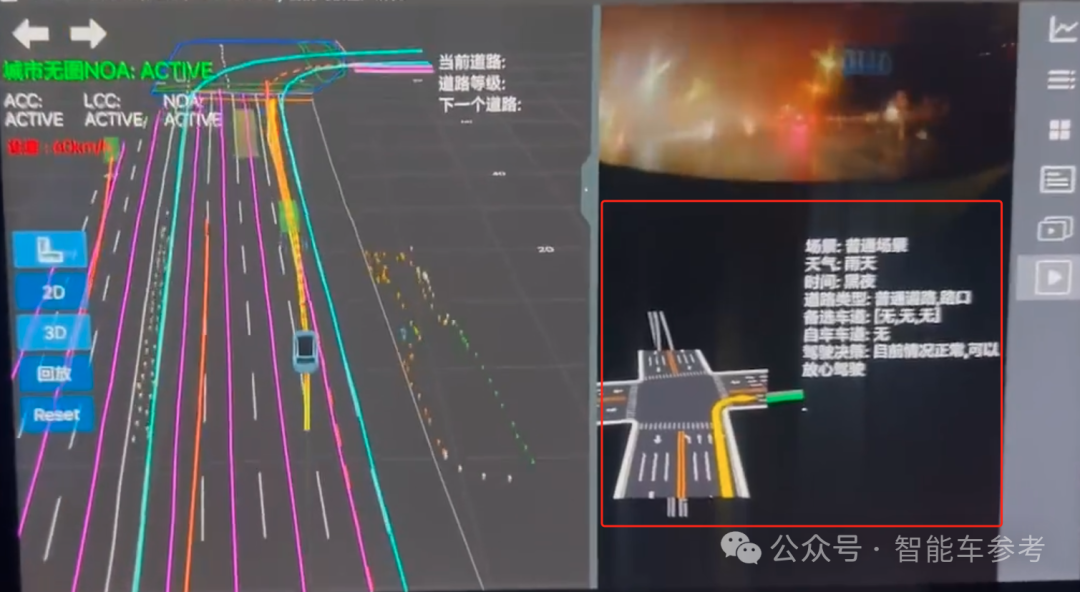
驾驶决策也很果断,嫌前车太慢,直接就是一个变道:

右转过路口比较顺畅,过弯就避让:

车主一整个期待住了,求快更新:
在视频中,测试者还特别强调,“真的没有用到图”。
因此视频所展示的,很可能就是还在内测阶段的理想无图NOA,目前测试范围扩大至一万人,预计将于今年三季度正式推送。
对此,有理想智驾团队成员转发微博称,理想端到端+VLM技术“超越无图一个时代”。
很多网友也是对此表示震撼,点赞理想的智驾进展:

实际落地,是否有网友们说的这么夸张,目前还不得而知。
但从公开成果来看,理想近期确实在智能驾驶方面,取得了一些不错的进展。
来,咱们一起扒一扒。
理想汽车近期的重要工作
理想汽车近期在智能驾驶方面有三项重要进展,先来看感知层:
理想联合中山大学,提出了一个名为UA-Track的3D多对象跟踪框架。
该框架主要是针对自动驾驶感知中的不确定性问题进行了优化,比如目标对象尺寸过小,或是被遮挡,造成跟踪不准确。

框架主要包括三个关键组件:
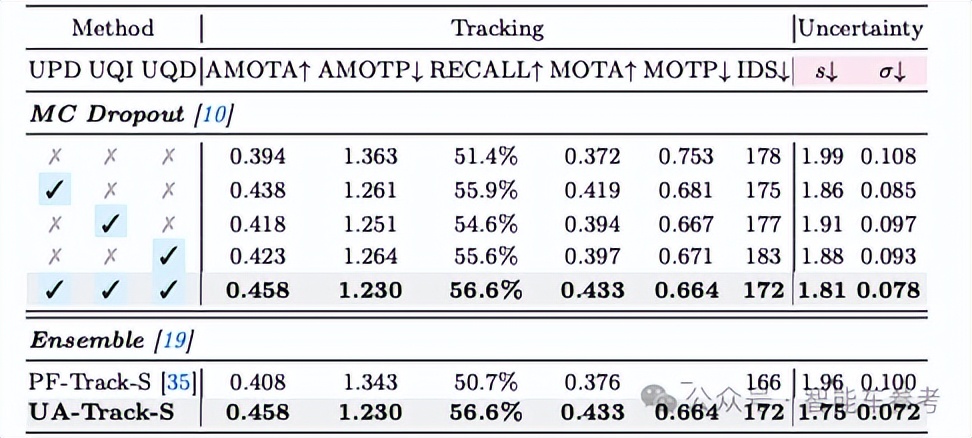
- 不确定性感知概率解码器(Uncertainty-aware Probabilistic Decoder), 简称UPD。引入了概率注意力机制,来捕获目标预测中的不确定性。
- 不确定性引导的查询去噪策略(Uncertainty-guided Query Denoising),简称UQD。在训练阶段模仿实际跟踪过程中,目标可能会受到的遮挡和观测误差,增强模型对不确定性的鲁棒性和收敛性。
- 不确定性降低的查询初始化(Uncertainty-reduced Query Initialization),简称UQI。利用预测的2D对象位置和深度信息来减少查询不确定性,提高初始对象定位的准确性。
这三个模块组成了一个端到端的系统,从输入图像直接生成跟踪结果。最终整体还会平衡损失函数,实现整体性能的最优化。
UA-Track在nuScenes(多模态3D自动驾驶数据集)基准测试中取得了最先进的性能,测试集上的AMOTA(平均多目标跟踪精度)达到了66.3%,比之前最好的端到端解决方案提高了8.9%。
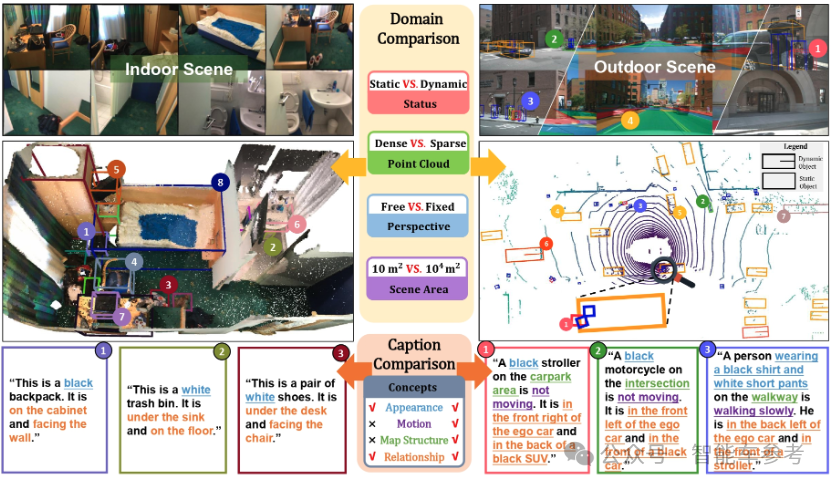
这是理想在感知层取得的最新成果,此外,理想还联合清华大学等单位,进行了TOD3Cap工作,提出了一种对象级的稠密图文对数据的生成方案。
可以对3D场景下的每个对象,生成详细的自然语言描述。同时还开源了一个室内外数据集。
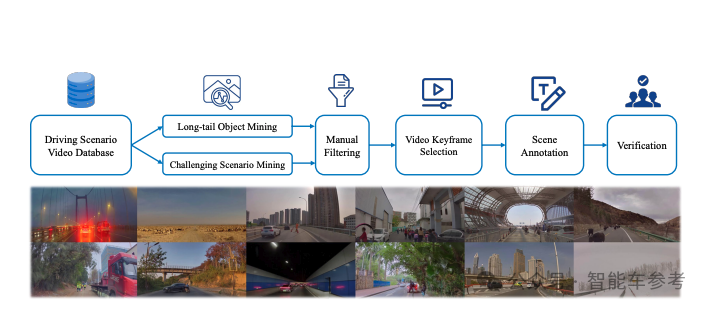
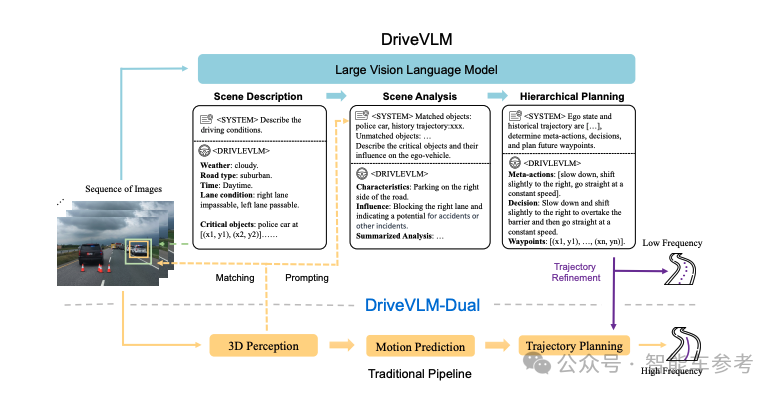
相比这两项工作,可能另一项工作DriveVLM大家更熟悉些,也是理想和清华的合作成果。
李想近日在出席重庆论坛时提到过,将人类快慢思考引入到AI算法中,整个自动驾驶系统一分为二:
传统的感知、预测、规划,这种模块化的范式对应第一类系统,是智能体基于人为手动写好的规则,就像人根据直觉和应急变化,做出快速反应。
不需要复杂的过程,应对常见场景没问题,响应迅速,需求算力也不高。
但是,很显然解决不了无穷无尽的Corner Case,怎么办?
这就需要借助第二类系统VLM,具备一定的通识能力,通过端到端的场景理解,识别物体和预测,进行决策和轨迹规划。
算力消耗大,需要更长的推理时间,好处是能够处理复杂场景,以及从未见过的长尾场景。
这些重要工作,为理想实现智能驾驶突破,提供了技术底层支撑。
通过测试视频,看起来理想下一阶段的智驾能力很不错。
当全面推送后,考虑到理想汽车的保有量,想必能力也会较快速的迭代,更上一层楼。
当然,具体能力会达到什么水平,还是要「上路见真章」。
什么时候,全国推送?
参考链接:
理想暴雨测智驾:https://weibo.com/1243861097/OiI9G30X8
清华MARS Lab解析DriveVLM:https://zhuanlan.zhihu.com/p/692173066?utm_psn=1784386450537615360
论文传送门:
UA-Track: Uncertainty-Aware End-to-End 3D Multi-Object Tracking
https://arxiv.org/pdf/2406.02147
TOD 3Cap: Towards 3D Dense Captioning in Outdoor Scenes
https://arxiv.org/pdf/2403.19589
DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
https://arxiv.org/pdf/2402.12289
- 上海车展见证历史:从「西为中用」到「中为西用」,行业风向标携手Momenta2025-05-01
- 上海车展探馆:国产百万级越野限量发售,武汉造,太尊了!2025-04-29
- 上海车展探馆:本田涨智慧靠中国,Momenta辅驾护航,DeepSeek赋能座舱2025-04-29
- 上海车展对话:高阶辅驾普及改变座舱需求,7B成模型上云分水岭2025-04-29









