
多模态大模型+自动驾驶=?ECCV’24这场Workshop开启招募啦
论文、挑战赛等你来投
CK 投稿
量子位 | 公众号 QbitAI
多模态,已经成为大模型最重要的发展方向之一。
从GPT-4V到GPT-4o,多模态大模型在多模态感知与理解方面的进展,正在不断惊艳世界。
然而,利用多模态大模型来应对自动驾驶中复杂场景,特别是罕见但关键的难例场景,仍然是一个未解的难题。

围绕这一挑战,现在,一场由香港科技大学、香港中文大学等研究机构发起的ECCV 2024 Workshop来了。
这场Workshop旨在研讨当前最先进的自动驾驶技术,与完全可靠的智能自动驾驶代理之间的差距,促进多模态大模型感知与理解、先进的AIGC技术在自动驾驶系统中的应用,以及端到端自动驾驶等方面的创新研究。
活动主要包括论文投稿和挑战赛两部分,如果你对此感兴趣,详情请看——
Workshop征稿
本次论文征稿关注自动驾驶场景多模态感知与理解、自动驾驶场景图像与视频生成、端到端自动驾驶、下一代工业级自动驾驶解决方案等主题,包括但不限于:
- Corner case mining and generation for autonomous driving.
- 3D object detection and scene understanding.
- Semantic occupancy prediction.
- Weakly supervised learning for 3D Lidar and 2D images.
- One/few/zero-shot learning for autonomous perception.
- End-to-end autonomous driving systems with Large Multimodal Models.
- Large Language Models techniques adaptable for self-driving systems.
- Safety/explainability/robustness for end-to-end autonomous driving.
- Domain adaptation and generalization for end-to-end autonomous driving.
投稿规则:
本次投稿将通过OpenReview平台实行双盲审稿,接收两种形式的投稿:
- 完整论文:论文篇幅在14页内,采用ECCV格式,参考文献和补充材料篇幅不限。被接收的论文将成为ECCV官方论文集的一部分,不允许重新提交到其他会议。
- 扩展摘要:论文篇幅为4页内,采用CVPR格式,参考文献和补充材料篇幅不限。被接收的论文不会被包含在ECCV官方论文集中,允许重新提交到其他的会议。
投稿入口:
- 完整论文:https://openreview.net/group?id=thecvf.com/ECCV/2024/Workshop/W-CODA
- 扩展摘要:https://openreview.net/group?id=thecvf.com/ECCV/2024/Workshop/W-CODA_Abstract_Paper_Track
自动驾驶难例场景多模态理解与视频生成挑战赛
本次竞赛旨在提升多模态模型在自动驾驶中极端情况的感知与理解,并生成描绘这些极端情况的能力。
赛道一:自动驾驶难例场景感知与理解
本赛道关注多模态大模型(MLLMs)在自动驾驶难例场景的感知和理解能力,包括整体场景理解、区域理解和行驶建议等方面的能力,旨在推动更加可靠且可解释的自动驾驶代理的发展。
赛道二:自动驾驶难例场景视频生成
本赛道关注扩散模型生成多视角自动驾驶场景视频的能力。基于给定的自动驾驶场景3D几何结构,模型需要生成与之对应的自动驾驶场景视频,并保证时序一致性、多视角一致性、指定的分辨率和视频时长。
竞赛时间:2024年6月15日至2024年8月15日
奖项设置:冠军1000美元,亚军800美元,季军600美元(每赛道)
时间节点
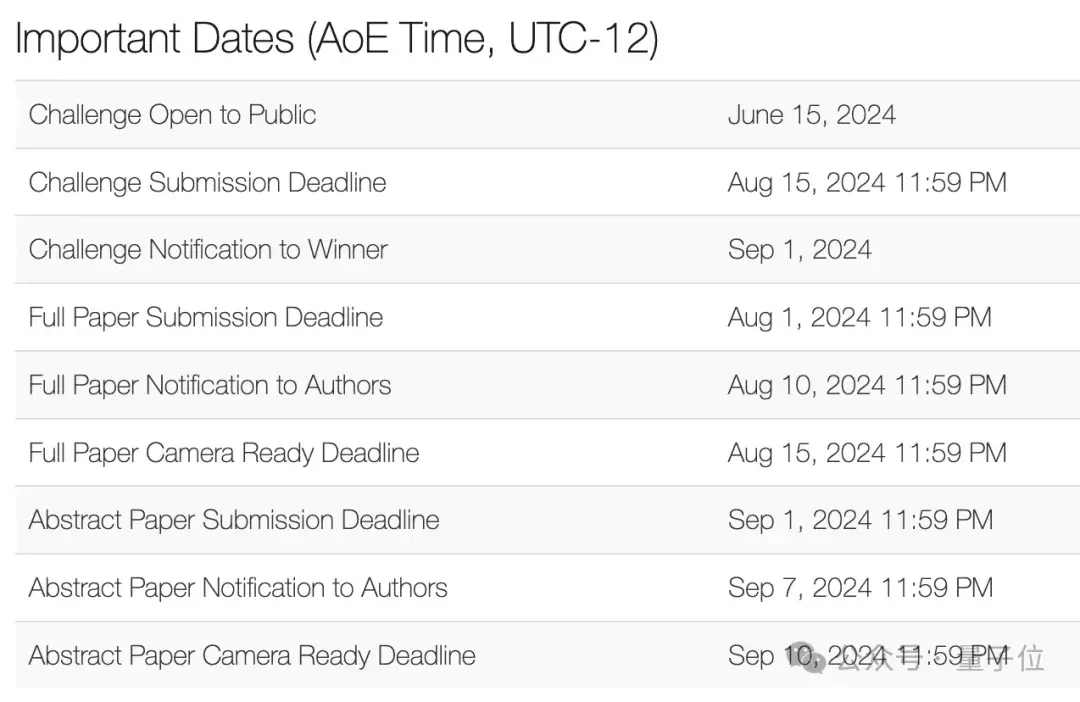
Workshop主页:
https://coda-dataset.github.io/w-coda2024/
- 图像编辑开源新SOTA,来自多模态卷王阶跃!大模型行业正步入「多模态时间」2025-04-28
- 不要思考过程,推理模型能力能够更强丨UC伯克利等最新研究2025-04-29
- 首份空间智能研究报告来了!一文全面获得空间智能要素、玩家图谱2025-04-26
- 拜拜邀请码!首个现货超级智能体实测2025-04-26

相关阅读



60篇论文入选,两度夺魁,“史上最难ECCV”商汤再攀高峰
商汤及联合实验室一共有60篇论文入选,涵盖对抗式生成模型、三维点云理解与分析、视频理解与分析、目标检测等热门及前沿领域,再次展示了商汤在计算机视觉领域的科研及创新实力。


