豆包大模型披露评测成绩,较上一代“云雀”提升19%
豆包模型在5月15日刚刚推出
豆包大模型在火山引擎原动力大会上正式发布。以超低价格掀起大模型降价潮的同时,豆包的模型能力也引发行业关注。
在火山引擎的一份产品资料中,豆包模型团队公布了一期内部测试结果:在 MMLU、BBH、GSM8K、HumanEval等11个业界主流的公开评测集上,Doubao-pro-4k 的总分为76.8分,相比上一代模型云雀Skylark2 的64.5分提升了19%,也优于同期测试的其他国产模型。
此次评测在今年5月完成,主要包括豆包通用模型-pro、云雀Skylark2 在内的九款国产大语言模型。除了云雀Skylark2 以外,其他模型均为各家厂商最新发布的高级版本,通过API调用进行测试。
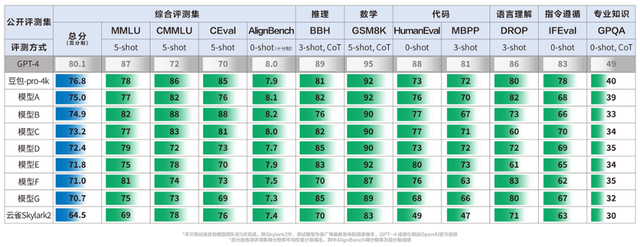
图:豆包模型团队内部测试结果
评测结果显示,在评估代码能力的两个评测集 HumanEval 和 MBPP 上,豆包相比上一代模型提升了50%左右;在专业知识和指令遵循的评测集上,豆包分别获得33%和24%的性能提升,同时也是得分最高的国产模型。
此外,豆包模型在数学能力、语言理解能力,以及综合评测集 CMMLU 和 CEval 的评测上也有不错的表现,得分排在前三。综合11个公开评测集上的测试成绩,豆包通用模型-pro的总分为76.8分。根据OpenAI公布的测试成绩,GPT-4在这些评测集上的总分为80.1分,相比国产模型仍有一定领先优势。
据悉,豆包模型在5月15日刚刚推出,尚未加入到第三方机构测试中。预计未来一到两个月内,很多第三方评测机构将会陆续披露该模型的评测结果。与模型同名的AI对话助手“豆包”,官方公布的月活用户数已经达到2600万,用户可以自由体验测试。
此前,智源研究院公布了覆盖全球91个语言模型的评测报告。在偏重考察中文能力的主观评测中,云雀Skylark2 排名第一,中文能力超过 GPT-4。
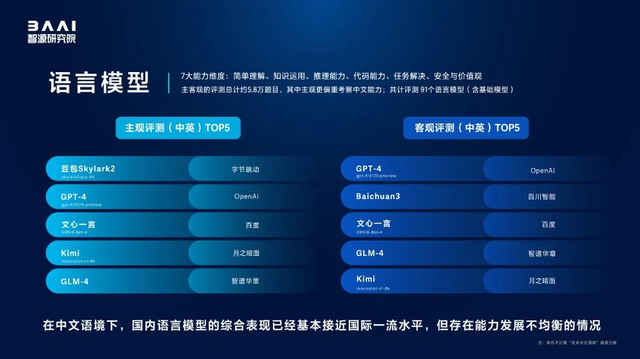
图:智源研究院语言模型评测结果(模型为4月20日之前的版本)
- 阶跃星辰推出开源 SOTA 图像编辑模型,一个月连发三款多模态模型2025-04-27
- 清华系智谱×生数达成战略合作,专注大模型联合创新2025-04-27
- 夸克AI超级框上新“拍照问夸克” 加码多模态能力2025-04-27
- 一季度超百万辆!比亚迪凭实力书写行业 “霸榜” 传奇2025-04-27