
GPT-4 Turbo首次被击败!国产大模型拿下总分第一
实测商汤SenseChat V5
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI长期霸榜的SuperCLUE(中文大模型测评基准),终于被国产大模型反将一军。
事情是这样的。
自打SuperCLUE问世以来,成绩第一的选手基本上要么是GPT-4,要么是GPT-4 Turbo,来感受一下这个feel:
(PS:共有6次成绩,分别为2023年的9月-12月和2024年的2月、4月。)
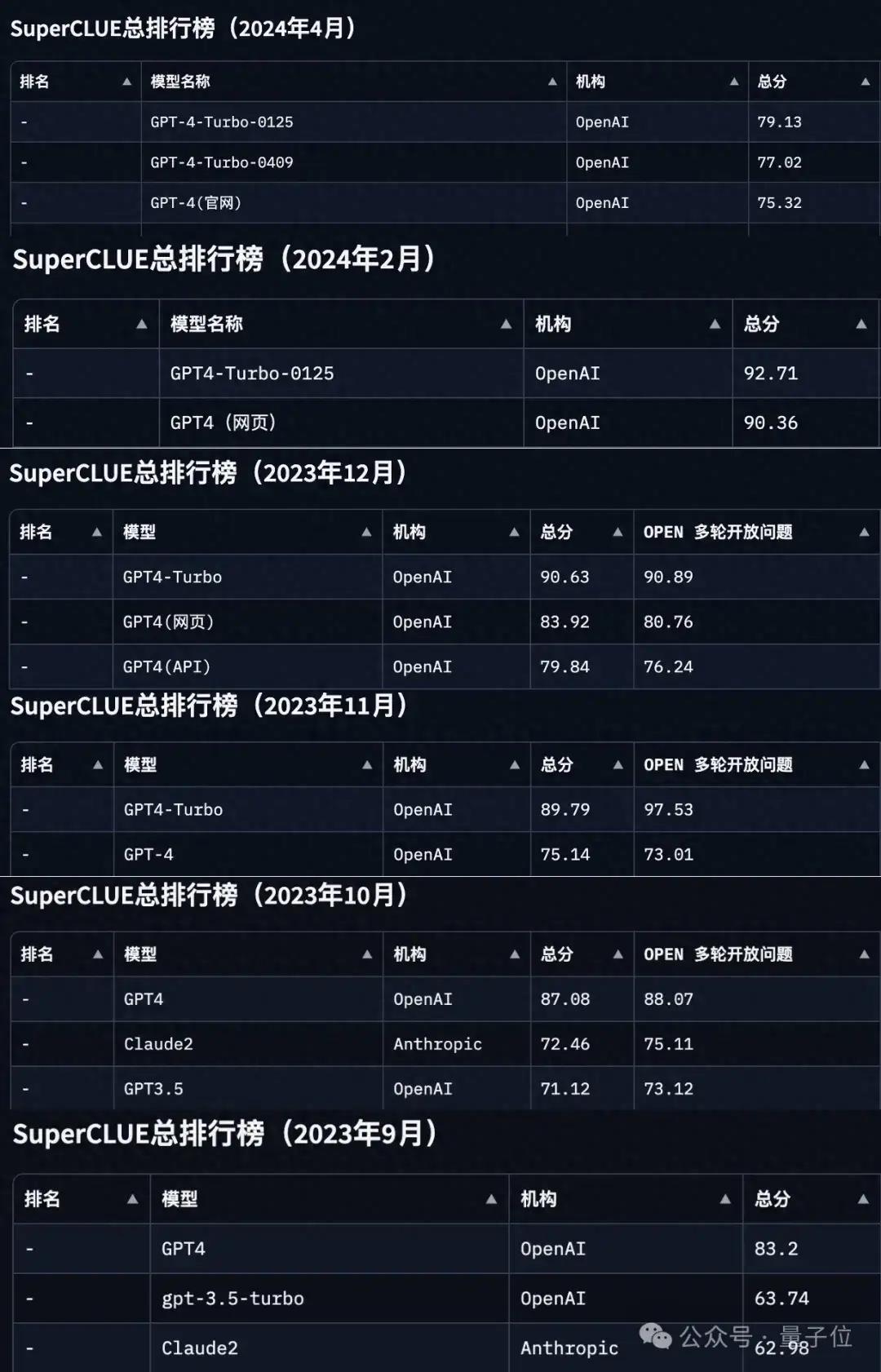
△图源:SuperCLUE官方
但就在最近,随着一位国产选手申请的出战,这一局面终是迎来了变数。
SuperCLUE团队对其进行了一番全方位的综合性测评,最终官宣的成绩是:
总分80.03分,超过GPT-4 Turbo的79.13分,成绩第一!
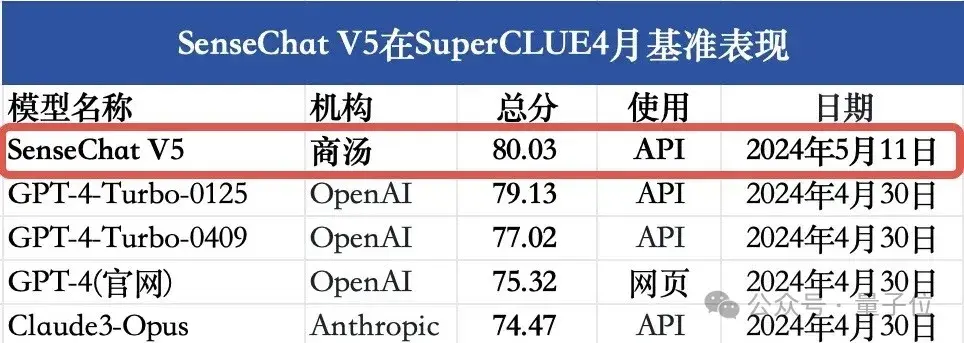
△图源:SuperCLUE官方公众号
而这位国产大模型选手,正是来自商汤科技的日日新5.0(SenseChat V5)。
并且SuperCLUE还给出了这样的评价:
刷新了国内大模型最好成绩。
那么商汤在SuperCLUE的这个“首次”,又是如何解锁的呢?
综合、文科国内外第一,理科国内第一
首先我们来看下这次官方所搭建“擂台”的竞技环境。
出战选手:SenseChat V5(于5月11日提供的内测API版本)
评测集:SuperCLUE综合性测评基准4月评测集,2194道多轮简答题,包括计算、逻辑推理、代码、长文本在内的基础十大任务。

△图源:SuperCLUE官方报告
模型GenerationConfig配置:
- temperature=0.01
- repetition_penalty=1.0
- top_p=0.8
- max_new_tokens=2048
- stream=false
至于具体的评测方法,SuperCLUE在已发布的相关报告中也有所披露:

△图源:SuperCLUE官方报告
以上就是SuperCLUE公开的竞技环境配置。
至于结果,除了刚才我们提到的综合成绩之外,官方还从文科和理科两个维度,再做了细分的评测。
SenseChat V5在文科上的成绩依然是打破了国内大模型的纪录——
以82.20分的成绩位居第一,同样超越了GPT-4 Turbo。
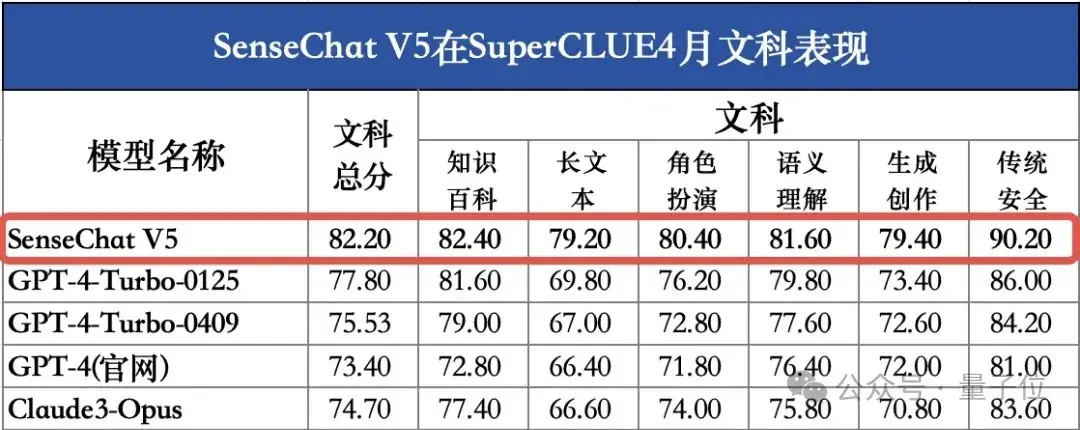
△图源:SuperCLUE官方公众号
在理科成绩上,虽然SenseChat V5此次并没有超越GPT-4-Turbo(低了4.35分),但整体来看,依旧在国内大模型选手中首屈一指,位列国内第一。

△图源:SuperCLUE官方公众号
除了文理科之外,SuperCLUE也还从国内和国外的整体平均水平上做了对比。
例如和国内大模型平均水平相比,其各项成绩的“打开方式”是这样的:
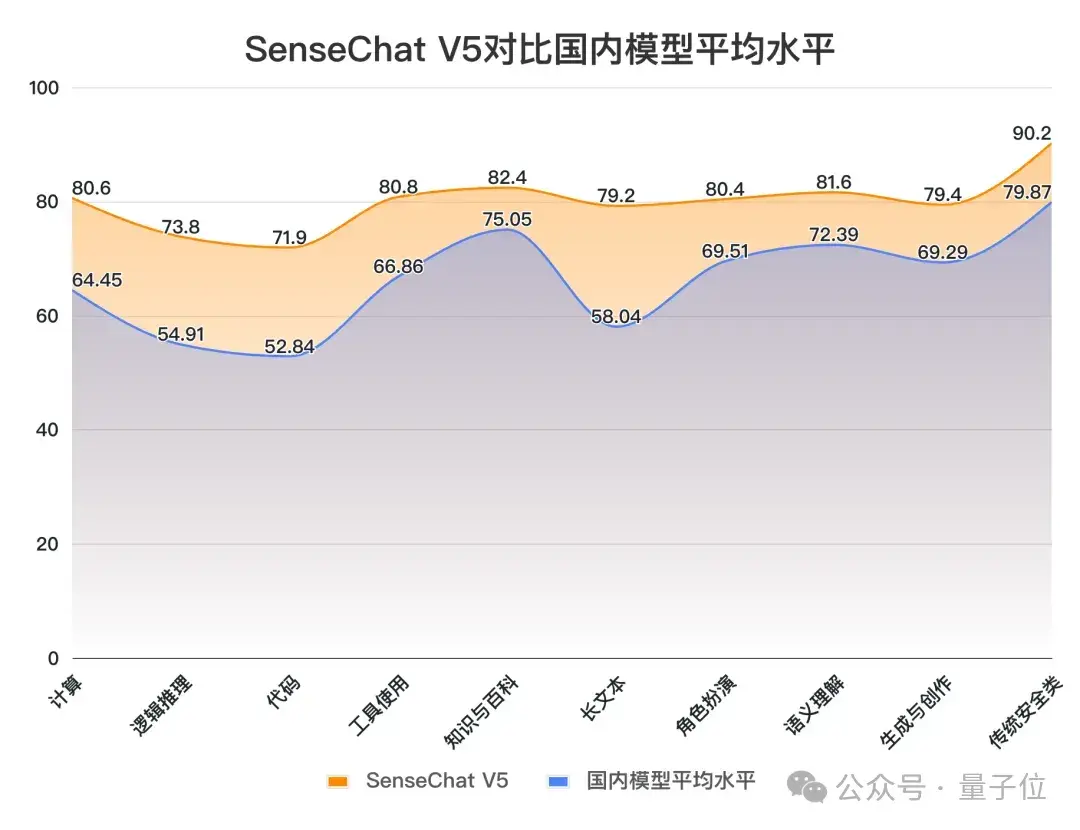
△图源:SuperCLUE官方公众号
而在与国外选手做性能对比时,我们可以明显看到SenseChat V5文科能力优于国外选手,数理能力也非常优秀,代码能力依然有提升空间。
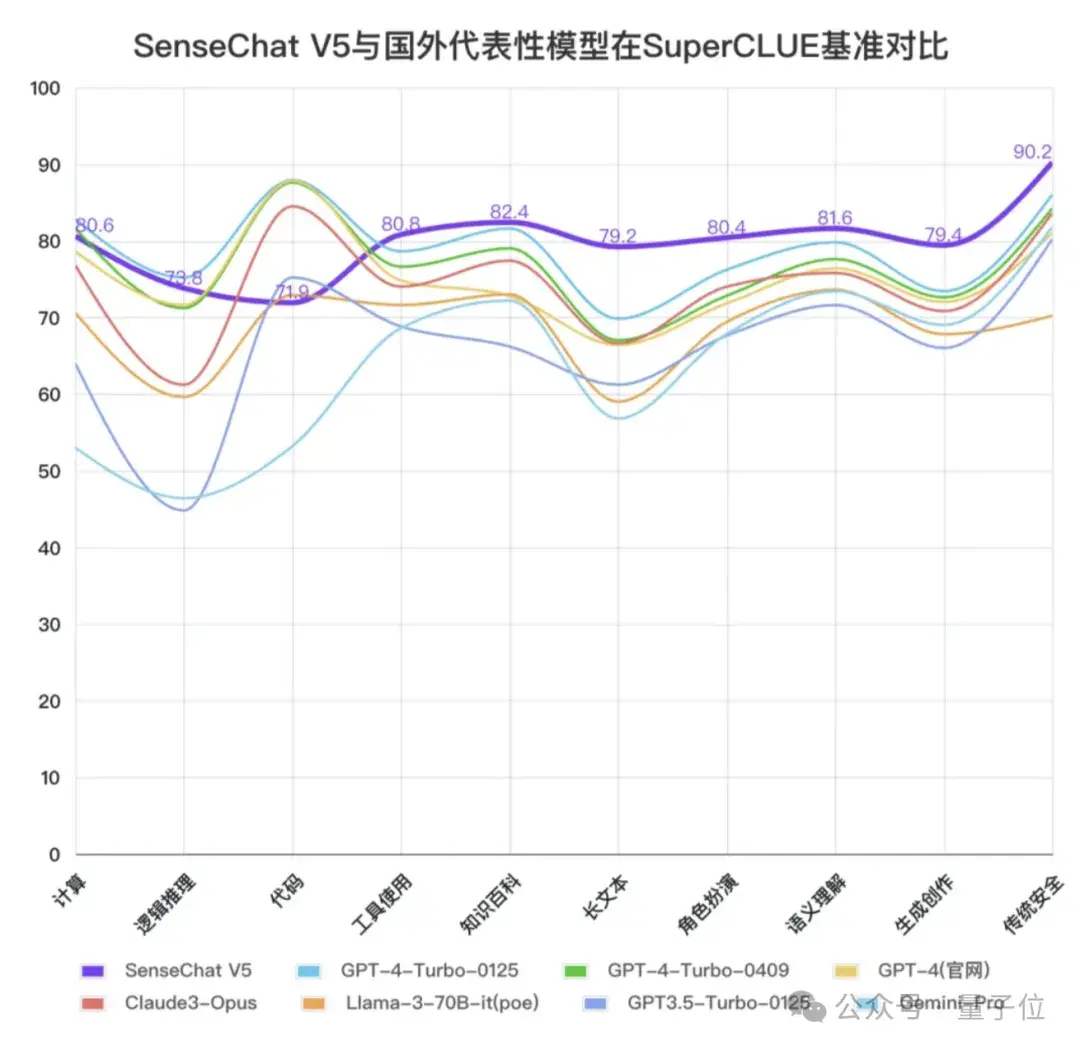

△图源:SuperCLUE官方公众号
不过有一说一,评测分数定然是代表大模型性能的一方面,但在应用为王的当下,更重要的一点或许就得看用的效果了。
实测SenseChat V5
SenseChat V5早在4月底便已经集成到了“商量”在线的对话应用中,因此我们现在就可以出题对它做一番考验。
在逻辑测试方面,带有文字陷阱的脑筋急转弯,可以说是测试一个AI能力很好的例子,比如:
《红楼梦》全书有百万字,“红楼梦”有几个字?
若是仔细观察这句话,不难发现其实句子前后并没有太大的关联,是一个比较典型的脑筋急转弯。
对此,SenseChat V5给出的答案是:
《红楼梦》作为中国古典文学的巅峰之作,其全文字数大约在70万到80万字之间,具体字数根据不同版本稍有差异。而标题“红楼梦”这三个字,自然是只有三个字。这个标题凝练而富有深意,象征着作品的梦幻色彩和对封建家族兴衰的深刻反思。
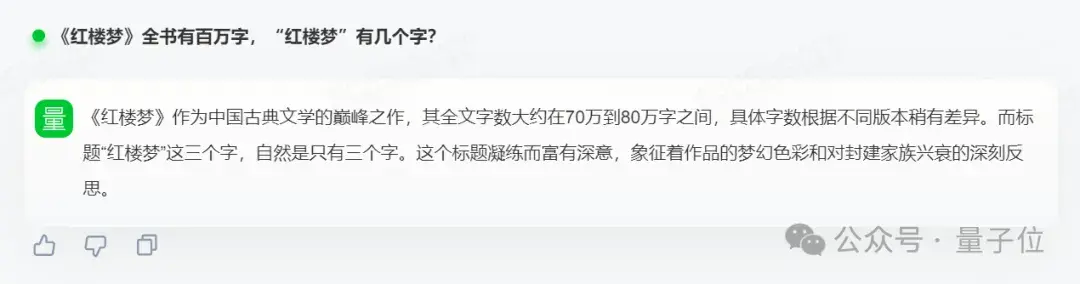
我们可以看到SenseChat V5不仅找出了问题的陷阱并做出了分析,给出的答案也是正确的。
对于数学的能力,我们设置了这样的一个问题:
假设有一个池塘,里面有无穷多的水。现有2个空水壶,容积分别为5升和6升。如何只用这2个水壶从池塘里取得3升的水。

同样的,SenseChat V5依旧是给出了每一个详细的步骤和分析,并得到了最终结果。
更直接的数学问题,例如找数字之间的规律,SenseChat V5也是信手拈来:

在中文理解方面,即使是给SenseChat V5一大段文言文,并且上难度连环发问,它是否可以hold得住?
请看结果:

最后,有请“弱智吧Benchmark”:
网吧能上网,为什么弱智吧不能上弱智?

嗯,确实是有点实力在身上的。
如何做到的?
其实对于这个问题,商汤在4月底将自家日日新大模型SenseNova版本迭代到5.0之际,就已经有所透露;当时商汤锁定的定位就是全面对标GPT-4 Turbo。
具体到技术,可以分为三大方面:
- 采用MoE架构
- 基于超过10TB tokens训练,拥有大量合成数据
- 推理上下文窗口达到200K
首先,为了突破数据层面的瓶颈,商汤科技使用了超过10T的tokens,确保了高质量数据的完整性,使得大模型对客观知识和世界有了基本的认知。
商汤还生成了数千亿tokens的思维链数据,这是此次数据层面创新的关键,能够激发大模型的强大推理能力。
其次,在算力层面,商汤科技通过联合优化算法设计和算力设施来提升性能:算力设施的拓扑极限用于定义下一阶段的算法,而算法的新进展又反过来指导算力设施的建设。
这也是商汤AI大装置在算法和算力联合迭代上的核心优势。

在其它细节方面,例如训练策略上的创新,商汤将训练过程分为三个大阶段(预训练、监督微调、RLHF)和六个子阶段,每个阶段专注于提升模型的特定能力。
例如,单是在预训练这个阶段,又可以细分为三个子阶段:初期聚焦于语言能力和基础常识的积累,中期扩展知识基础和长文表达能力,后期则通过超长文本和复杂思维数据进一步拔高模型能力。
因此在预训练结束之际,整个模型就已经拥有了较高水平的基础能力;但此时它的交互能力却还没有被激发出来,也就来到了第二阶段的监督微调(SFT)和第三阶段的人类反馈强化学习(RLHF)。
整体可以理解为先培养模型遵循指令和解决问题的能力,再调节其表达风格以更贴近人类的表达方式。接着,通过多维度的人类反馈强化学习过程,进一步改进模型的表达方式和安全性。
除此之外,商汤对于大模型的能力还有独到的三层架构(KRE)的理解。
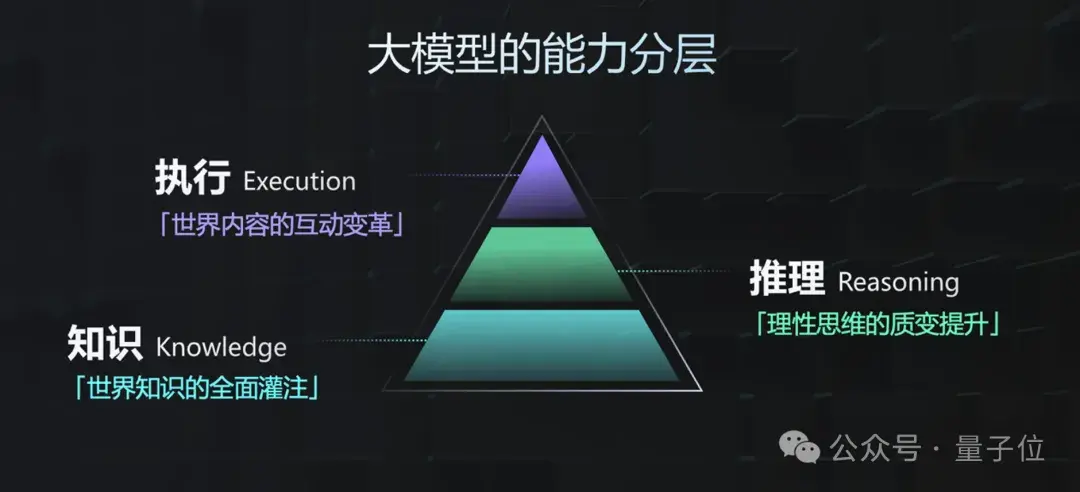
首先是在知识,是指世界知识的全面灌注。
目前大模型等新质生产力工具近乎都是基于此来解决问题,也就是根据前人已经解决过的问题的方案,来回答你的问题。
这可以认为是大模型能力的基本功,但更为高阶的知识,应当是基于这样能力下推理得到的新知识,这也就是这个架构的第二层——推理,即理性思维的质变提升。
这一层的能力是可以决定大模型是否够聪明、是否可以举一反三的关键和核心。
再在此之上,便是执行,是指世界内容的交互变革,也就是如何跟真实世界产生互动(就目前而言,具身智能在这一层是潜力股般的存在)。
三者虽相互独立,但层与层之间也是紧密关联,打一个较为形象的比喻就是“知识到推理是像大脑,推理到执行则像小脑”。
在商汤看来,这三层的架构是大模型应当具备的能力,而这也正是启发商汤构建高质量数据的关键。
One More Thing
其实对于大模型测评这事,业界质疑的声音也是层出不穷,认为是“刷分”、“刷榜”、“看效果才是最重要的”。
对于这样敏感的问题,商汤在与量子位的交流过程中也是直面并给出了他们的看法:
无论从用户选择合适模型的角度,还是从研究者进行操作研究的需要来看,对模型能力的评价是必不可少的。
这不仅帮助用户和研究者了解不同模型的性能,也是推动模型发展的关键因素。
如果只针对一个公开的评测集进行优化(即刷分),是有可能提高模型在该评测集上的分数的。
评测不应只依赖单一数据集,而应通过多个评测集和第三方闭卷考试等方式相互印证,以此来得到更全面、更有说服力的模型性能评估。
以及对于国内近期各个大模型厂商正打得热火朝天的价格战,商汤将眼光放在了提供更深的端到端产品价值上,特别是在具备无限潜力且与生活应用更接近的移动端上,通过端云协同实现更优的计算成本但不损害模型的综合能力。
这或许暗示了商汤将通过技术创新和优化成本结构,为未来可能入局的价格竞争做好了自己的规划。
参考链接:
[1]https://www.superclueai.com/
[2]https://mp.weixin.qq.com/s/3pfOKtG6ar2h2fR6Isv_Xw
- 3B模型逆袭7B巨头!Video-XL-Pro突破长视频理解极限,大海捞针准确率超98%2025-05-04
- 2年就过气!ChatGPT催生的百万年薪岗位,大厂不愿意招了2025-05-04
- 14.9万元,满血流畅运行DeepSeek一体机抱回家!清华90后初创出品2025-04-29
- 全球第一车企,集齐中美双版Waymo2025-04-30









