华为最新研究挑战Scaling Law
大模型表现主要看记忆力
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
“Scaling Law不是万金油”——关于大模型表现,华为又提出了新理论。
他们发现,一些现象无法用Scaling Law来解释,进而开展了更加深入的研究。
根据实验结果,他们认为Transformer模型的成绩,与记忆力高度相关。

具体来说,他们发现Scaling Law的缺陷主要有这两种表现:
一是一些小模型的表现和大一些的模型相当甚至更好,如参数量只有2B的MiniCPM,表现与13B的Llama接近。
二是在训练大模型时,如果过度训练,模型表现不会继续增加,反而呈现出了U型曲线。
经过深入研究和建模,团队结合了Hopfield联想记忆模型,提出了大模型表现的新解释。
有人评价说,联想记忆是人类所使用的一种记忆方法,现在发现大模型也会用,可以说是AI理解力的跃迁。

不过需要指出的是,这项研究虽有挑战之意,但并非对Scaling Law的否定,而是对其局限性的客观思考和重要补充,同时作者对前者的贡献也做出了肯定。
构建全新能量函数
作者首先进行了假设,提出了新的能量函数,并根据Transformer模型的分层结构,设计了全局能量函数。
能量函数是一种描述系统状态的数学工具,它将系统的每个可能状态映射到一个实数值,函数值越低系统越“稳定”。
可以简单地说,大模型的训练过程就是在寻找能量函数的最小值。
具体到本文,作者提出了这样的能量函数,其中x表示查询向量,ρi表示记忆:
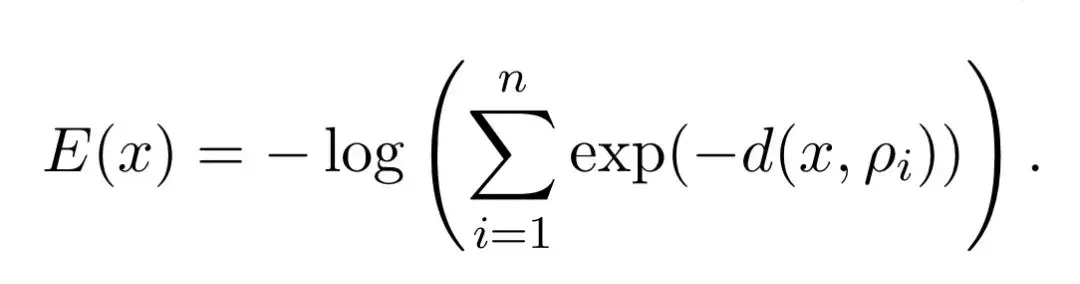
根据数学规律不难看出,当x与所有ρi的距离d(x, ρi)都很大时,每一项exp(-d(x, ρi))都会趋近于0,进而导致E(x)趋近于正无穷。
所以,E(x)在记忆向量ρi附近取得较小值,在远离所有记忆的地方取得较大值,因此最小化E(x)就相当于找到与x最相似的记忆。
作者进一步证明,E(x)与现代连续Hopfield网络(MCHN)的能量函数在数学形式上是等价的。
(Hopfield网络是一种经典的联想记忆神经网络模型,由物理学家John Hopfield在1982年提出。)
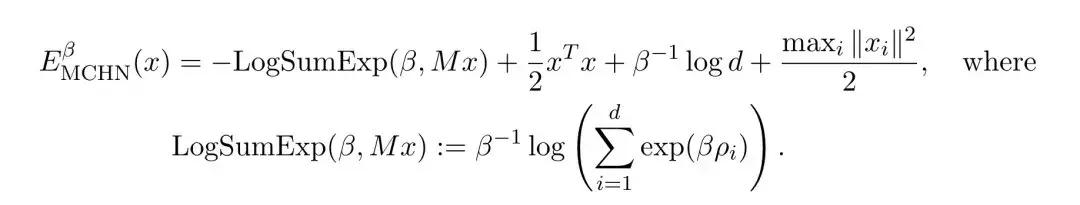
这两个函数的相似性,可以通过下图更加直观地展现:
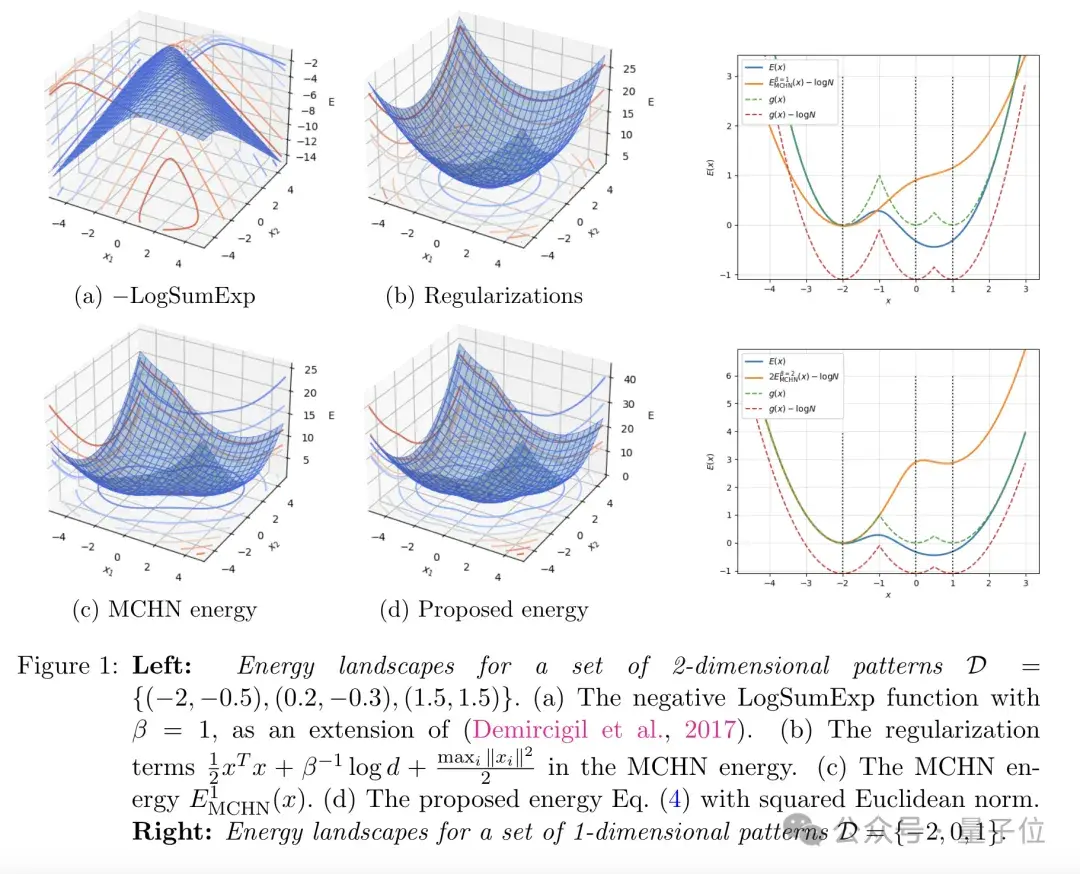
不过需要注意的是,Transformer通常由多个相同的注意力层堆叠而成,为了刻画整个网络的行为,有必要设计一个全局的能量函数。
作者借鉴了majorization-minimization(优化-最小化)的思想,将每一层的能量函数E_t(x)视为全局能量E_global(x)的一个紧上界。
于是,前向传播的过程可以被视为依次最小化每一个E_t(x),进而最小化E_global(x)。
通过巧妙地设计各层的能量函数使其互为紧上界(一个函数在另一个函数之上,但两者非常接近),让每层的局部能量函数都紧紧“束缚”住全局能量函数,作者构建出一个连贯的、可优化的全局能量函数,成功刻画了Transformer的分层结构。
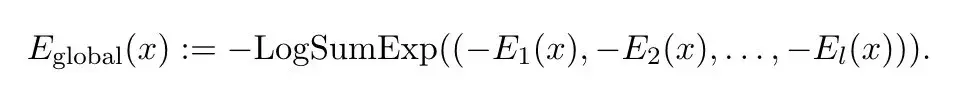
大模型表现,记忆是关键
为了验证这些假设,研究人员开展了一系列实验。
首先,作者在预训练的GPT-2模型上对记忆力进行了分析。
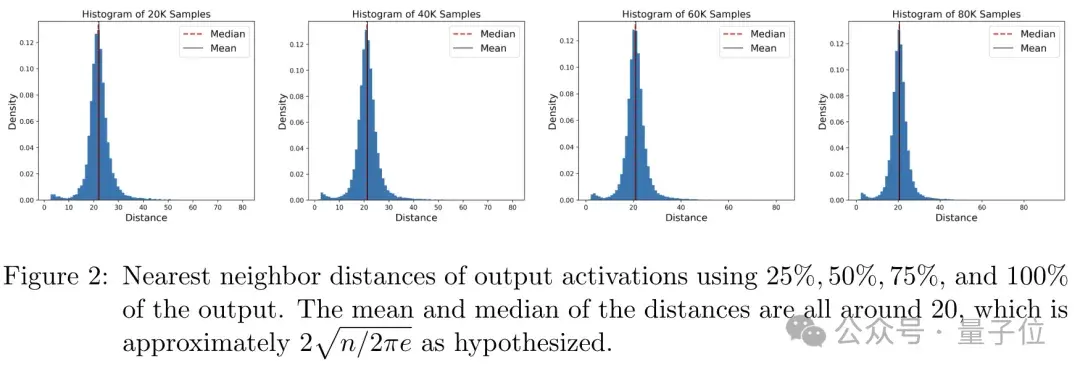
他们分析了模型最后一层的输出表示与训练样本之间的关系,并计算了每个输出向量与其最近训练样本的距离,绘制出了这些距离的分布直方图。
结果表明,大多数输出向量都集中在以训练样本为中心的局部区域内,距离中心大约10个单位。
这个结果与作者基于能量函数得出的理论预测(最优记忆半径约为√(n/2πe))非常接近。
这说明,Transformer的每一层都在进行一种基于相似性的记忆检索,其性能主要取决于记忆半径的大小。
进一步地,作者又在不同数据规模上训练了GPT-2,并分析损失函数变化。
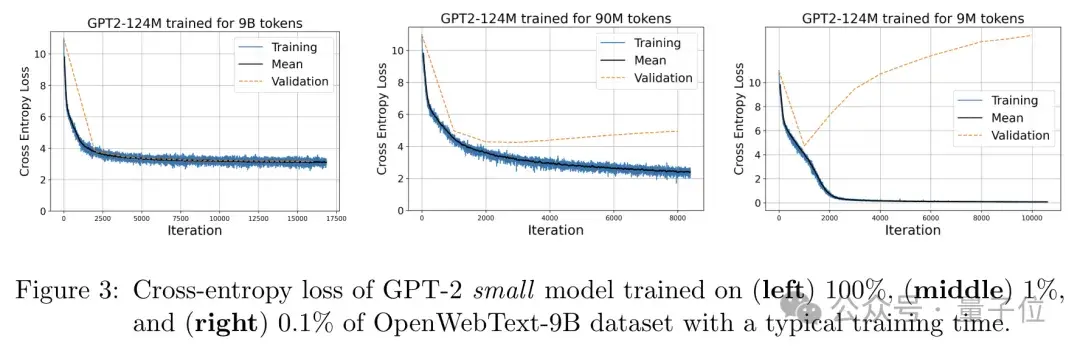
作者在三个不同规模(100%、1%、0.1%)的OpenWebText数据集上训练了GPT-2模型,并记录了其训练和验证损失的变化曲线。
实验结果表明,当数据规模很小时,模型很容易过拟合,表现为训练损失迅速下降到0,而验证损失却居高不下;
当数据规模较大时,训练和验证损失则接近且平稳,最终都显著高于0。
也就是说,当数据规模足够大、模型可以很好地“记忆”训练集时,其最终的损失会稳定在理论预测的下界附近,从另一个角度说明了模型的性能确实主要取决于其记忆容量。
最后,作者又在问答数据集上训练了原始Transformer,同时也分析了损失函数变化。
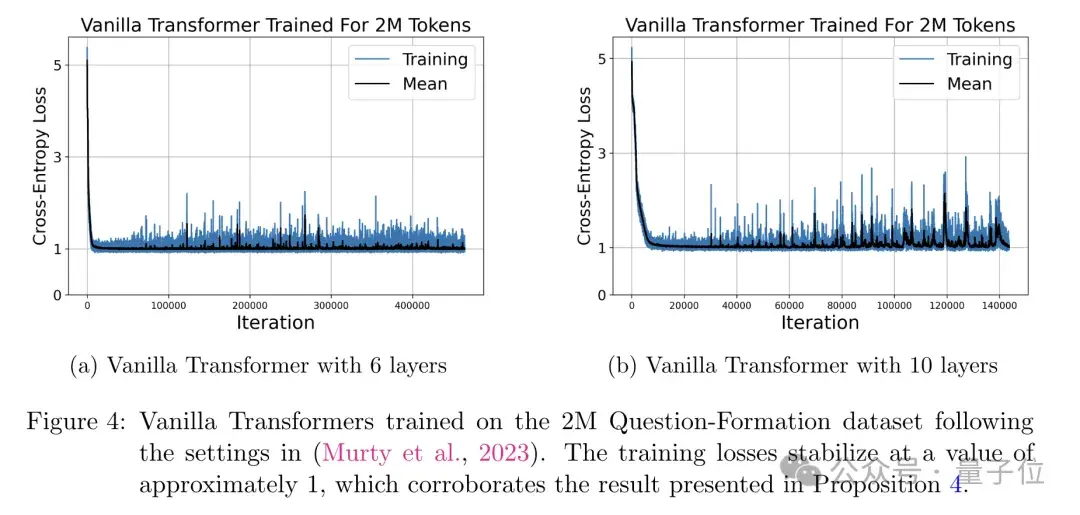
具体来说,他们在一个受控的任务(将声明句改写为疑问句)上训练了一个纯Transformer模型。
他们发现,随着训练的进行,模型的损失函数呈现出明显的分段下降趋势,每个阶段对应于一定数量的训练样本被记忆,最终稳定在了理论预测的下界附近。
这个实验不仅验证了作者关于损失下界的理论预测,也直观地展示了Transformer通过逐层能量最小化来实现记忆的过程。
总之,通过理论建模和多项实验验证,作者最终得出结论,Transformer的性能主要取决于其记忆训练样本的能力。
同时根据构建并被验证的全局能量函数,作者还指出,为达到最优性能,模型参数量应随训练数据量的平方而线性增长。
如果你认为对你有所启发,不妨阅读原论文了解更多细节。
论文地址:
https://arxiv.org/abs/2405.08707
- 细节直逼亚毫米级!港科广分层建模突破3D人体生成|CVPR 20252025-05-05
- o3一张图锁定地球表面坐标,AI看图猜地点战胜人类大师,奥特曼:这是我的「直升机」时刻2025-05-05
- 图像编辑开源新SOTA,来自多模态卷王阶跃!大模型行业正步入「多模态时间」2025-04-28
- 不要思考过程,推理模型能力能够更强丨UC伯克利等最新研究2025-04-29