谷歌开源大模型Gemma带来了什么,原来“中国制造”的机会早已到来
国产大模型包揽前二
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
谷歌罕见open的AI,给开源大模型到底带来了什么?
Gemma从发布到现在已经时过数日,谷歌久违的这次开源,可谓是给全球科技圈投下了一枚重磅炸弹。
在最初发布之际,不论是从谷歌官方还是Jeff Dean的发文来看,都强调的是Gemma 7B已经全面超越了同量级的Llama 2和Mistral。

在与此前最火热的开源大模型Llama 2在细节上做比较,不论是在综合能力,以及推理、数学和编程等能力上,完全属于all win的状态。

科技巨头出品、全面对外开放、免费可商用、笔记本就能跑……各种福利标签的加持之下,近乎让全球的“观众老爷们”为之雀跃。
而就在最近,不少网友们也开始了对Gemma的各种测评。
例如有人就用ollama在Macbook上跑了一下Gemma 7B,所做的任务是根据文章开头的文字来判定文章的类型。
并在体验过后给出了评价:
还比较稳定和准确!

还有网友在对Gemma和Mistral做了对比测试之后发现:
Gemma-7B确实能正确回答Mistral-7B回答不了的问题。

由此种种表现,网友不禁发出感慨:
谷歌打破了开源大模型的格局:形成Gemma、Llama和Mistral三足鼎立之势。
虽然成果足以令人振奋,但似乎在开源大模型这件事上,全球的目光都还是聚焦在了国外“顶流”们的身上。
随即而来的一个问题便是:
中国开源大模型,怎么样了?
在开源大模型领域,除了欧美主流科技巨头之外,中国“选手”也是长期占有一席之地。
那么随着Gemma的问世,在榜单排名这件事上,是否又掀起了些许波澜?
结果是有点意外的——
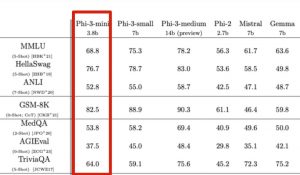
在HuggingFace的开源大模型排行榜里,Gemma排在了7B预训练模型的第三名:

第一名和第二名均被国产大模型选手包揽——InternLM2(书⽣·浦语2.0),由商汤科技和上海AI实验室等单位联合打造。
那么新晋开源顶流Gemma,是在哪些细节上失分的呢?
在看完平均得分情况之后,我们继续来看下细分赛道的情况。
首先是在综合能力(General)上,InternLM2-7B的得分为65.8分,略高于Gemma-7B。
其次是在推理能力(Reasoning)的2个基准中上,InternLM2-7B拿到一胜一平的成绩。
接下来是数学能力(Math),同样是2个基准,InternLM2-7B在 GSM8K 评测基准中大幅超过 16 分。
最后是编程能力(Code),InternLM2-7B则是高出了整整10分。
若是将Llama-2 7B也放进来,那么InternLM2-7B则是在各项做到了完胜。
不仅如此,即便是拿7B的InternLM2和更大体量的13B Llama-2做比较,在各项细分成绩中依旧是完胜。

更直观一些,InternLM2和Gemma之间的性能比较如下:

意外吗?其实也并不意外。
因为国产开源大模型在Gemma发布之前,就已经在各种榜单中站稳了一席之地,而且还不是昙花一现的那种。

例如InternLM2就是于今年1月17日“出道”,2种参数规格、3种模型版本,共计6个模型,全部免费可商用:
- InternLM2-Base(7B、20B)
- InternLM2(7B、20B)
- InternLM2-Chat(7B、20B)
当时在与全球众多7B量级选手的同台竞技中,InternLM2便以“大圈包小圈”的姿势在性能上取得了一定的优势。

而且在与ChatGPT的比较过程中,在重点能力上,例如推理、数学、代码等方面是超越了ChatGPT的。
比如InternLM2-Chat-20B在MATH、GSM8K上,表现都超过ChatGPT;在配合代码解释器的条件下,则能达到和GPT-4相仿水平。

InternLM2还支持200K超长上下文,可轻松读200页财报。200K文本全文范围关键信息召回准确率达95.62%。
例如在实际应用过程中,将长达3个小时的会议记录、212页长的财报内容“投喂”给它,InterLM2可以轻松hold住。

在不依靠计算器等外部工具的情况下,可进行部分复杂数学题的运算和求解。
例如100以内数学运算上可做到接近100%准确率,1000以内达到80%准确率。
如果配合代码解释器,20B模型已可以求解积分等大学级别数学题。

如何做到的呢?我们从研究团队了解到,其所采取的策略关键并非是卷大模型的参数,而是在数据。
在团队看来,提炼出一版非常好的数据后,它可以支持不同规格模型的训练:
所以首先把很大一部分精力花在数据迭代上,让数据在一个领先的水平。在中轻量级模型上迭代数据,可以让我们走得更快。
团队为此开发了一套先进的数据清洗和过滤系统,核心工作分为三个关键部分:
- 多维度数据价值分析:该系统通过评估数据的语言质量和信息密度等多个方面,对数据的价值进行全面分析和提升。例如,研究发现论坛网页评论对模型性能的提升作用有限。
- 基于高质量语料的数据扩展:团队利用高质量语料的特性,从现实世界、网络资源和现有语料库中收集更多相关数据,以进一步丰富数据集。
- 目标化数据补充:通过有目的性地补充语料,特别是强化世界知识、数学逻辑和编程代码等领域的核心能力,以提升数据集的深度和广度。
如此“三步走”的系统设计便让数据集得到了相应的优化,让它更加丰富、准确,并更好地支持模型的训练和应用。
当然,InternLM2的开发不仅仅局限于提升模型的基础性能,同时也紧跟当前的应用趋势,对特定的下游任务进行了性能增强。
例如,针对当前流行的超长上下文处理需求,团队指出,在工具调用、数理推理等应用场景中,需要处理更长的上下文信息。
为了应对这一挑战,InternLM2通过扩大训练窗口的容量和改进位置编码技术,同时确保训练数据的质量和结构化关系,成功地将上下文窗口的支持能力扩展到了20万个tokens。
如此一来,不仅提高了模型处理长文本的能力,也优化了整体的训练效率。
这便是InternLM2从“出道”至今,即便是面对顶流Gemma依旧能够稳坐榜首的原因了。
结语
最后,回答一下文章最开始的那个问题——
Gemma给开源大模型到底带来了什么?
首先,是趋势。
自从大模型的热度起来之后,对于开源和闭源的话题也是一直在持续。
OpenAI的ChatGPT、GPT-4等,所代表的就是闭源大模型,其所具备的实力也是有目共睹;而此前Llama、Mitral等则是开源大模型的代表。
谷歌作为AI巨头,在此前大模型巨头混战中是略显疲态的,毕竟作为对标产品的Gemini,似乎也并未能撼动OpenAI的领先地位。
而此次谷歌罕见的开源了大模型、发布Gemma,则是要以此来对标开源界的其它选手,并且从目前公布的成绩来看,谷歌是取得了一定的优势。
同时,从侧面也反应出了,开源项目在大模型的发展中有着重要的作用。
其次,是信心。
或许很多人对于大模型的发展依旧停留或关注于国外主流的科技巨头。
但从各种榜单、评测的数据上来看,中国的大模型同样也具备很强的竞争实力。
不仅仅是InternLM2-7B的开源模型,在不同参数体量的模型上,都有国产大模型选手在加入竞争。
而且从结果上,已然是做到了中文和英文整体能力上的全面超越。
从这一点上来看,Gemma的发布不仅是在开源大模型界新添强势玩家这么简单,更是给中国开源大模型,甚至整个AI大模型行业都带来了一份信心。
总而言之,从开年到现在短短2个月的时间,我们能够非常直观感受到的一点便是大模型的战场是越发的热闹。
不论是国内国外、开源闭源,亦或是各种多模态,从Gemini到Gemma,从Sora到Stable Diffusion 3,各大科技厂商你追我赶的态势愈演愈烈。
但有一点是较为明确的,那就是所有发布都在趋向于推理,趋向于如何把技术用起来。
因此,或许大模型在接下来的进程中,谁能让自家的产品“快好省”地用起来,谁就能笑到最后。
- 智能车速度刷新:仅10个月,首个纯端侧大模型上车量产!2025-04-24
- 百度阮瑜:大模型应用落地正从简单高容错向复杂低容错场景延伸|中国AIGC产业峰会2025-04-24
- 全球首个无限时长视频生成!新扩散模型引爆万亿市场,电影级理解,全面开源2025-04-21
- 教育信创到底怎么选?能做到”无感切换”的只有C862025-04-21