【APUS &大数据国家工程实验室】700亿参数APUS大模型3.0伶荔中文大模型正式发布!
在中文基准测评榜单C-Eval上获得80.6分
由APUS与深圳大学大数据系统计算技术国家工程实验室(以下简称“大数据国家工程实验室”)联合研发的伶荔Linly-70B中文大模型正式对外开源,并在GitHub上首发。这是APUS大模型3.0的首个开源大模型,也是国内学术界首个700亿参数规模的开源大模型。

此次,APUS和大数据国家工程实验室强强联合,集成各自优势,更有大数据国家实验室陈国良院士权威背书,APUS大模型3.0伶荔已有700亿参数加持,在中文基准测评榜单C-Eval上获得80.6分,更加适配中文场景,满足中文大模型场景使用需求。
跻身700亿+参数开源大模型梯队
当前市场中,700亿以上参数的开源模型数量仅有个位数,特别是学术界,因为算力资源有限,还没有开源过700亿以上参数规模的模型,但其价值不可低估。700亿参数规模的大模型能力上可以接近GPT-4的水平,在局部水平上甚至可以超越GPT-4。在深圳大学李煜东博士看来,市面上700亿参数规模的开源大模型很少的原因在于三方面:一是训练成本更高,二是增量预训练时需要更大数据量,三是使用时需消耗更多的资源。此次APUS和国家工程实验室共同研发APUS大模型3.0伶荔则是迈出至关重要的一步。
中文能力大幅提升
基于APUS郑州智算中心强大的计算能力,APUS大模型3.0伶荔在中文扩表后进行了严格训练,显著提高了模型的训练效率和准确性。该模型的上下文长度设定为4,096,能够处理大约8,000-10,000个汉字的文本输入,从而更好理解和生成中文语境下的自然语言,提高其在各种中文任务中的表现。APUS大模型3.0伶荔在中文基准测评榜单C-Eval上获得了80.6分的成绩,赶超GPT-4,在中文自然语言处理领域,这一成绩表现非常优秀。

多模态能力定制化调优,综合实力凸显
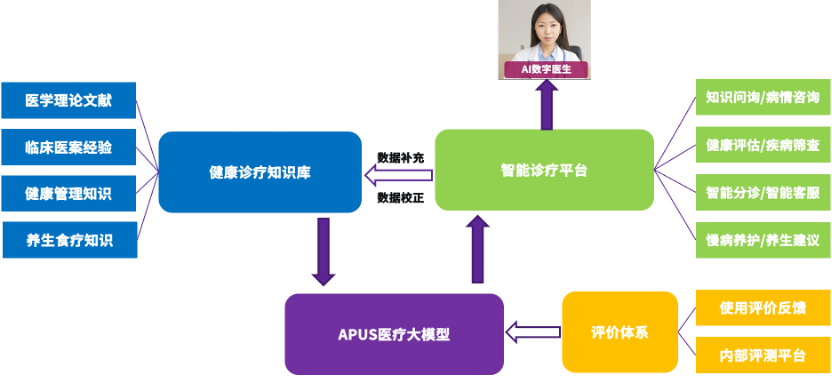
为了提高APUS大模型3.0伶荔在中文场景中的表现,在语料、训练框架和训练方法上进行了定制化调优。基于自研模块化增量预训练框架,针对中文特点扩充词表,增加了对汉字和中文符号的支持。在训练语料方面,精选高质量中英文公开数据源,包括悟道、万卷、MNBVC等,并结合自研的数据选择策略,构建了适合模型高效训练的混合语料库。此外,项目团队还提出创新性课程学习策略,通过动态数据采样,在训练过程中不断调整数据分布,确保模型的英文语言能力能够平稳迁移到中文能力。这一策略的运用,使得模型在中文语境下能够更加自然、准确地理解和生成文本。
全新发布的APUS大模型3.0伶荔在中文自然语言处理领域展现出了卓越的性能和巨大的潜力,并已经准备好应对各种中文任务和挑战。APUS与国家工程实验室已迈出构建中文场景大型语言模型的关键一步,未来二者将持续密切合作,共同探索模型在知识、推理和长文本处理等方面的通用能力,并深化其在工具使用、剧情生成和角色扮演以及医疗等专业领域的应用,进一步提升模型的能力和应用范围。此外,双方还将扩展到视觉模态,构建跨模态生成模型,以更好、更精准满足通用和领域特定的需求。
- 阶跃星辰&光影焕像开源3D大模型Step1X-3D2025-05-15
- 学而思发布全新学习机,小思AI 1对1 成亮点,三大系列产品与服务体系齐亮相2025-05-08
- 比亚迪超级充电和加油一样快,一秒充电超2公里2025-03-18
- 倒计时两周!百度“文心杯”创业大赛亿元奖金池等你来冲2025-05-06