AI看视频自动找“高能时刻”|字节&中科院自动化所@AAAI 2024
数据集代码都开放
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
大家看视频用过“高光时刻”功能吗?
观众可以直接空降到精彩时刻,主播也可以从长时间直播录像中复盘自己的表现。

字节跳动联合中科院自动化研究所提出新方法,用AI快速检测出视频中的高光片段,对输入视频的长度以及期望提取的高光长度都具有极高的灵活性,相关论文已被AAAI 2024收录。

基于原型学习的基准解决方案
连续学习问题在图像识别领域得到了很好的发展,有效缓解了深度学习模型所面临的灾难性遗忘问题。然而,现有的技术大多适用于图像域,在视频域上探索连续学习的相关方法还比较少。分析其中的原因,主要是两个方面的困境:其一是缺少用于增量学习的视频数据集以及评测标准;其二是缺少一个适用于视频域增量学习的基准方法。
面对这一挑战,字节跳动联合中科院自动化研究所标注了用于域增量学习的美食视频数据集LiveFood,并在此基础上,提出了基于原型学习的基准解决方案:Global Prototype Encoding(GPE)。
GPE克服了现有增量学习方案的诸多弊端,通过在图像帧级别上的打分,帮助快速检测出视频中的高光片段,对输入视频的长度以及期望提取的高光长度都具有极高的灵活性。
问题定义与数据搜集
要解决连续学习设定下的视频高光检测,避不开两个关键点:其一是数据集,其二是任务定义。
考虑到美食视频是当下的一大热点,本篇文章从美食视频入手,以期获得更大的应用范围。在美食垂类中,本文定义了四个域,分别是:食材准备(ingredients),烹饪(cooking),成品展示(presentation),以及美食享用(eating)。
这四个域可以基本涵盖美食视频中的精彩部分。在此基础上,作者收集了5100多条美食视频数据,组成了LiveFood数据集。标注人员对该数据集做了详细的人工标注,指明高光的片段的起止时间以及对应的域。标注的过程经过两次校对,确保标注的准确性。LiveFood数据集的基本信息如下:

△ 图片1
图片1(a)反映了LiveFood中的视频,多数时长都在200秒以内,是短视频的范畴;图片1(b)反映了LiveFood中的高光标注,主要集中在9秒钟以下;图片1(c)反映了LiveFood中的视频高光较均匀地分布在整个视频,可以有效防止模型学习捷径。
作者指出,在图像识别中,由于每张图像大多只包含一种域(风格),因此域增量学习任务较容易定义,但是在视频任务中,该前提不再成立。例如,在LiveFood中,一个视频可能包含着若干美食域。
基于此,作者约束:在当前训练阶段中,视频中不可以包含前序训练阶段中出现的域组合。
例如,在第一训练阶段,所有的视频只包含「美食展示」这一域,在第二个训练阶段,新增「美食享用」这一域,那么,在第二阶段出现的每个视频,其域组合有两种,其一是仅有「美食享用」,其二是同时包含「美食展示,美食享用」。
而在第一阶段出现的「美食享用」不可再单独出现。评测集中的视频有着所有的域标注,在对应的训练阶段,只评测该训练阶段及前序阶段出现的域,未出现的域不参与评测。评测指标为高光检测的mAP。下表展示了LiveFood和现有数据的一些对比,表明LiveFood更适合用来做增量学习:

△表格1
技术创新路径
现有增量学习的解决方案可以粗略分为三个大方向:
其一是数据回放,即通过一定的筛选机制,在每个训练阶段保存具有代表性的数据,这些数据将参与后续阶段的训练,从而减缓模型的遗忘现象;
其二是参数正则,即约束模型参数的变化量,保持对前序阶段所学内容的响应;
其三是模型增长,即使用不同的模型,来解决不同训练阶段的任务,用隔离的方式缓解遗忘现象。
GPE的设计期望达成以下目标:
其一,不显式使用数据回放,因为选择代表性数据并不容易,并且视频数据的存储和读取有一定代价;
其二,避免参数正则化方案中,模型受少数参数主导的问题;
其三,不采用模型增长,维护同一个模型结构,从而在不同的训练阶段,都可以复用相同的部署方案。
基于此,GPE使用了高光原型学习的方案,在视频帧级别上做二分类任务,判断视频帧属于高光还是非高光。
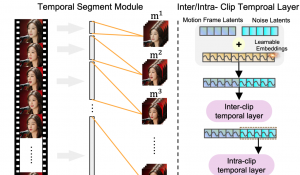
首先,GPE使用ConvNeXt网络提取视频帧的特征,并利用编码器(encoder)对这些特征做时序上的融合,获得上下文的信息。经过时序融合后的特征计算到高光原型点和非高光原型点的距离,这些距离会使用Softmax函数映射成概率的形式,用于做二分类任务。

△ 图片2
GPE缓解深度学习模型的灾难性遗忘,是通过限制不同训练阶段之间原型点的变化实现的。分别用θ,ϕ,π表示CNN的参数,编码器的参数,以及可学习的高光/非高光原型点。GPE的优化目标为:在相邻训练阶段之间,π的变化量不超过γ的前提下,最小化高光和非高光的分类损失。对于带约束的优化问题,我们使用拉格朗日方法求解,其中拉格朗日对偶表达式如下:

使用启发式思想,在约束条件成立时,减小惩罚因子λ是拉格朗日乘子,还需要保证其大于零。在训练过程中,利用每个批次的训练数据,交替优化上述参数即可:

基准测试结果
GPE在LiveFood上取得了良好的高光检测性能,可以对初始训练阶段中的美食高光产生较高的响应。参与对比的方案包括:性能下界(Lb),性能上界(Ub),SI,oEWC,ER,DER等。
GPE有两个变式,其Mf指的是动态增加原型点的数量,在每个训练阶段只约束原来原型点的变化,新增的原型点可以自由学习。带星号(*)的方法使用了随机数据回放。表格2展示了在不同训练阶段,GPE检测美食高光的能力(mAP)。

△表格2
美食高光检测可视化。在训练过程中,域的出现顺序为:presentation,eating,ingredients,以及最后的cooking。图片3展示了GPE在第四阶段训练完成后(T4,橙色),仍然对第一阶段的域presentation有着很高的响应,超过了DER在第四阶段对presentation的响应程度。

△图片3
高光原型点与非高光原型点可视化。图片4展示了在不同训练阶段的高光原型点以及非高光原型点的分布状态。考虑到非高光片段大多为无意义片段,特征相似,因此在不同的训练阶段,只增加高光原型点(每个训练阶段增加80个),不增加非高光原型点。图片4展示了,即使随着训练阶段的不断增加,高光原型点与非高光原型点还是能够被模型很好的分开,这也表明了GPE有着较强的抵抗遗忘的能力。

△图片4
项目链接: https://foreverps.github.io/
- 心影随形创始人刘斌新:做不跟用户抢时间的AI产品丨中国AIGC产业峰会2025-04-22
- 狸谱App负责人一休:从“叫爸爸”小游戏到百万月活AI爆款,社交传播有这些底层逻辑丨中国AIGC产业峰会2025-04-23
- 直观即时绘制3D模型,可添加文本提示,VAST又开源了2025-04-21
- LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯2025-04-06