用多模态LLM做自动驾驶决策器,可解释性有了!比纯端到端更擅长处理特殊场景,来自商汤
自动驾驶新解法
丰色 曹原 发自 凹非寺
量子位 | 公众号 QbitAI
用多模态大模型做自动驾驶的决策器,效果居然这么好?
来自商汤的最新自动驾驶大模型DriveMLM,直接在闭环测试最权威榜单CARLA上取得了SOTA成绩——
跑分比基线Apollo还要高4.7,令一众传统模块化和端到端方法全都黯然失色。

对于该模型,我们只需将图像、激光雷达信息、交通规则甚至是乘客需求“一股脑”丢给它,它就能给出驾驶方案——直接能够控制车辆的那种,并告诉你为什么要这么开。

这不仅让驾驶逻辑可控、过程具备可解释性,且更擅长解决特殊和复杂情况。
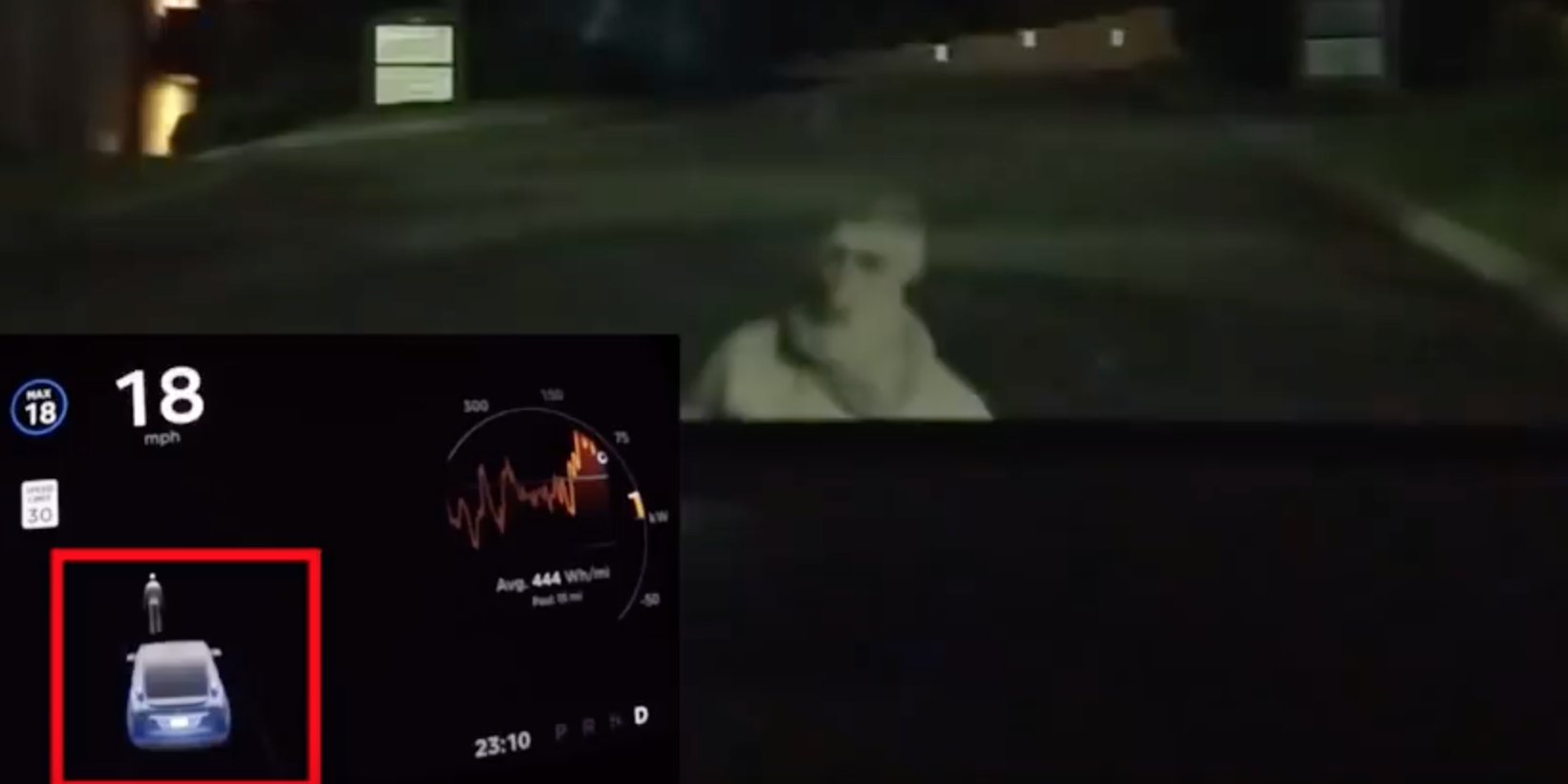
像什么给紧急车辆让行?小case:

你说你着急能不能超车?它也能灵活处理(a为超车成功,b为车道不空,拒绝超车):

简直不要太惊艳~
具体怎么实现,我们扒开论文来看。
多模态LLM破解自动驾驶难题
目前,自动驾驶系统主要有两种方案,模块化和端到端。
模块化方案顾名思义,把自动驾驶任务拆解为感知、定位和规控三个模块,各模块各自完成任务,最后输出车辆控制信号。

而端到端则是一个整体的模型,包含了上述感知、定位等等所有模块的功能, 最后同样输出车辆控制信号。
但这两种方案,各有各的缺点。
模块化方案的算法依赖专家知识,所有规则都需要提前手写、定义。如果在实际驾驶场景中碰到没有提前写入的情况,很可能导致系统失效。比如救护车、消防车这种不会按照交通规则行驶的车辆,让自动驾驶系统自己去处理就很容易出错。
端到端方案则是依赖数据驱动,虽然靠大量、真实情况下的驾驶数据,可以不断驱动系统能力进行迭代,但这同样对输入的数据要求很高,需要大量的标注数据,这无异增加系统训练和迭代的成本。
同时,至今为止,端到端方案的神经网络还是一个“黑盒”,决策规划都在系统内部完成,缺乏可解释性。万一有问题,很难像模块化方案那样发现到底是哪一部分出了问题。

而对于增强端到端方案的可解释性,近年来也有许多研究将大语言模型(LLM)引入自动驾驶系统中,但缺点是LLM输出主要是语言,无法进一步用于车辆控制。
对此,商汤提出了DriveMLM模型,它和现有自动驾驶系统行为规划模块中的决策状态对齐,可实现闭环测试中操控车辆,超过之前的端到端和基于规则的自动驾驶系统方法。
和开环测试中,通过给定图片进行轨迹预测相比,闭环测试能模拟真实环境和场景,更接近真实驾驶效果。
具体来看,其整体框架如图所示。

首先它将LLM的语言决策输出,和成熟模块化方案中规控部分的决策状态对齐,由此LLM输出的语言信号就可转化为车辆控制信号。
其次,DriveMLM的MLLM planner模块,包含多模态分词器(Multi-modal tokenizer)和MLLM解码器两个部分。
前者负责将摄像头、激光雷达、用户语言需求、交通规则等各种输入转化为统一的token embedding;后者,即MLLM解码器则基于这里生成的token,再生成图片描述、驾驶决策和决策解释等内容。
训练上,DriveMLM在280小时长的驾驶数据上进行完成(共包含50000条路线、30种不同天气和照明条件的场景)。
所有这些数据全部收集自CARLA仿真器,也就是目前自动驾驶领域被使用最多的开源仿真工具和闭环测试基准。
格式如下:每帧都包含对应的图片描述、驾驶决策和决策解释三部分。

△数据案例
相比现有自动驾驶数据,DriveMLM的数据有两个不同之处:
一是决策部分能够与实际行为决策模块对齐,方便我们将MLLM规划器的输出转换为控制信号,直接控制闭环驾驶中的车辆;
二是包含与人类的交互数据,可以提高系统理解人类指令并做出反应的能力。

那么,基于以上一切实现,DriveMLM的具体效果如何?
能真正跑起来且具备可解释性
首先,和业内的其他驾驶方法相比,DriveMLM实现了闭环测试的SOTA成绩。
在CARLA中广泛使用的Town05Long基准上,它的驾驶得分(Driving Score)和路线完成度(Route Completion)明显比Apollo等非大模型方法都要高。
唯一惜败的是违规得分(Infraction Score),但也跟Apollo相差无几。
这表明,DriveMLM可以在遵守交规的同时做出更好的决定。
除此之外,DriveMLM (Miles Per Intervention)在MPI指标上也具备相当大的领先优势,说明它在相同里程内更少被人为接管,更为可靠。
从下面的演示来看,DriveMLM能够处理各种复杂情况,比如绕过未知障碍物:

比如给紧急车辆让行:

特别值得一提的是,大模型的自然语言处理能力让它更具人性化,通过语言指令,还能处理来自人类乘客的特殊需求,进一步更改MLLM规划器的决策。
例如有人表示“我着急能不能开快点”,它完全能够根据实际路况灵活处理,能超就超,不能超便拒绝,相当“贴心”。
其次,和其他多模态大模型例如GPT-4V相比,DriveMLM也表现亮眼:具备更高的决策准确率和解释合理性。
如下图所示,GPT-4V解释了一大堆,却没有看到红灯(a)/前方车辆(b),给出了错误的建议,而DriveMLM在这两个场景中都简单干脆、直击重点,给出了正确的驾驶方法。

最后,DriveMLM还在真实驾驶场景上展现出了零样本能力(基于nuScenes验证集)。
如下图所示, DriveMLM能够识别现实环境中的红灯并停车(左)、推断现实十字路口的位置并提前减速(右)。

总的来看,以上测试证明,借助多模态大模型的能力,商汤提出的DriveMLM确实展现出了巨大的智驾潜力。
而相比此前的一系列传统方法,它的最大优势和价值主要包含三个方面:
一是一致的决策指令设置使得DriveMLM可以直接与现有的模块化AD系统(如Apollo)进行对接,无需任何重大更改就能够实现闭环驾驶,让车真的跑起来。
二是可以直接输入自然语言指令传达乘客需求或高级系统消息,交给模型来处理。
这样一来,自动驾驶系统便能适应越发多样、高阶的驾驶场景。
三是基于大模型不光输出结果还能给出逻辑推理过程的特性,DriveMLM作出的每一个行为和选择都会跟有详细的说明来解释它为什么要这么做。
可解释性和安全之间的强关联关系不用多说,DriveMLM的高可解释性,将有助于我们不断开发更为安全透明的自动驾驶系统。
自动驾驶的未来,就靠大模型了
有观点云:自动驾驶一定有ChatGPT时刻,且最快就在今年到来。
如何到来?
业内普遍将目光投向了大模型。
商汤联合创始人、首席科学家王晓刚最近就发表观点称:
接下来的一到两年,是智能汽车关键突破的时间点。
无论是端到端数据驱动的自动驾驶、还是智能座舱大脑等等,都将以大模型为基础。
他指出:其中在智能驾驶方面,大模型将包揽并连通感知、融合、定位、决策、规控等一系列模块的功能并进行连通,来真正解决各种Corner Case。

而商汤的这次成果就让我们看到,用大模型,特别是能处理多种类型数据的多模态LLM来做决策,对自动驾驶能力确实有很大提升。
其中最关键的,就是自动驾驶系统能更像人类,具备一定的常识,对驾驶环境、规则有相应的理解。
所以可以摆脱对手写规则的依赖,在遇见没有碰到过的驾驶场景时,比如上面提到的前方道路转弯、需要提前减速的情况,系统能够自己处理。
并且除了以往的传感器数据,人类的语言输入也能够参与车辆控制的流程中,同时系统能够理解意图,并根据实际情况做出驾驶决策。
其实要说将大模型应用于自动驾驶,商汤DriveMLM并非行业先例。
但它作为业内首个将大模型应用于驾驶决策的方案,实现了对车辆的实际控制,更容易在车端构建端到端的解决方案,让我们看到了大模型这一新解法的巨大潜力,所以值得关注。
此外,说起商汤,它本身在自动驾驶方面也有积淀。
不久前,他们的感知决策一体化自动驾驶通用大模型还入选了CVPR 2023最佳论文:《Planning-oriented Autonomous Driving》,DriveMLM正是在这个成果上进行的后续研究。

最后,我们也不由地期待,DriveMLM真正落地量产车的那一天。
所以,你看好大模型这一新解法吗?你认为还有哪些挑战需要解决?
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10