ChatGPT只算L1阶段,谷歌提出AGI完整路线图
DALL·E已至L3?
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
AGI应该如何发展、最终呈什么样子?
现在,业内第一个标准率先发布:
AGI分级框架,来自谷歌DeepMind。

该框架认为,发展AGI必须遵循6个基本原则:
- 关注能力,而非过程
- 同时衡量技能水平和通用性
- 专注于认知和元认知任务
- 关注最高潜力,而非实际落地水平
- 注重生态有效性
- 关注整条AGI之路的发展,而非单一的终点
在此原则之上,AGI将呈现6大发展阶段,每个阶段都有对应的深度(性能)和广度(通用性)指标。
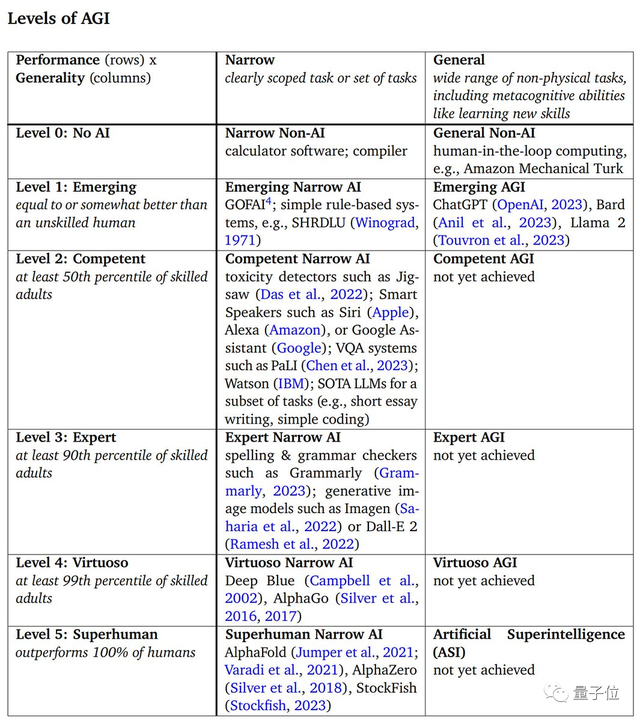
我们当前的AI产品走到哪一阶段了?这里也有答案。
详细来看。
6项基本原则
什么是AGI?
对于这个问题,许多科学家、研究机构都给出了自己的理解。
比如图灵提出的图灵测试认为机器是否能“思考”就是一个衡量指标;强人工智能的概念提出者则认为,AGI是一个拥有意识的系统;还有人说AGI一定是能在复杂性和速度上与人脑一样甚至超越人脑……
谷歌认为,这些定义都不全面。
像图灵测试,一些LLM已经可以通过,但我们能称那些模型为AGI吗?
像类人脑说法,Transformer架构的成功就已表明,严格基于大脑的思考过程对于AGI来说并不是必须的。
通过分析这些定义(一共9种,详情可翻阅原文)的优缺点,谷歌重新理出了6项基本原则:
一、关注能力,而非过程。
这可以帮助我们去除一些不一定是实现AGI的必备要求:
比如AGI不一定要用类似人类的方式思考或理解,也不意味着系统必须具有主观意识等能力(主要是这种能力无法也通过固定的方法去测量)。
二、注重通用性和技能水平。
目前所有的AGI定义都强调了通用性,这一点不必多说。但谷歌强调,性能也是AGI的关键组成部分(也就是可以达到人类的几分水平)。在后面的具体阶段制定中,主要也是根据这俩指标进行分类的。
三、专注于认知和元认知任务。
前者目前基本为共识,即AGI可以执行各种非体力任务。不过谷歌在此强调,AI系统执行物理任务的能力也需要加强,因为它对于认知能力是有推动作用的。
此外,元认知能力,如学习新任务或知道何时向人类寻求帮助,是系统走向通用性的关键先决条件。
四、关注最高潜力,而非实际落地水平
证明一个系统可以在给定的标准上完成任务,就足以宣布该系统为AGI,我们不要求一定得在开放世界中完全部署出水平相同的系统。
因为,这可能会面临一些非技术阻碍,比如法律和社会考虑、潜在道德问题。
五、注重生态有效性。
所谓生态有效性,谷歌指的是选择真正有用的现实任务去benchmark系统的进步,这些任务不仅包括经济价值也包括社会和艺术价值,要避开那些容易自动匹配和量化的传统AI指标。
六、关注整条AGI之路的发展,而非单一的终点。
这也是为什么谷歌要制定我们接下来将要看到的6个发展阶段。
6大必经阶段
AGI之路的6个阶段由深度指标(即技能水平,与人类相比)和广度指标(通用性)进行划分。
第零阶段为“No AI”,计算软件、编译器等属于该范畴,在通用性上只能执行human-in-the-loop任务。
第一阶段为“涌现级”(Emerging),技能相当于或略比没有相关技能的人类要强。
ChatGPT、Bard和Llama 2等大模型就属于该阶段,并且已经满足了该阶段要达到的通用性。
第二阶段可理解为“刚刚合格级”(Competent),可以达到正常成年人50%的水平。
像语音助手Sir、能在短文写作/简单编码等任务中达到SOTA水平的大模型都属于这一阶段。
不过,它们都只是在技能指标上合格了,通用性还够不上,也没有其它能够达到这一阶段通用性水平的AI产品。
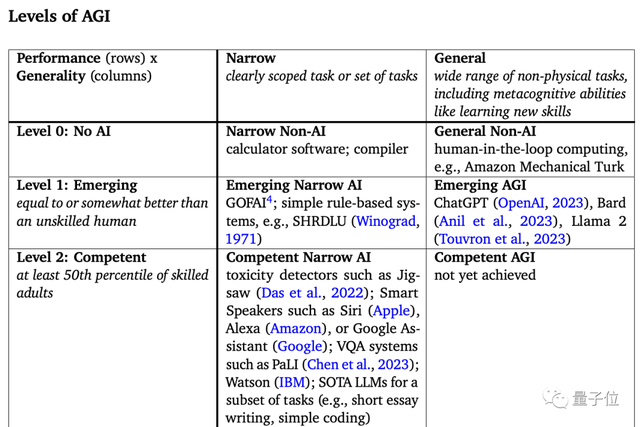
第三阶段为“专家级”(Expert),可达到正常成年人90%的水平。
谷歌认为,拼写和语法检查器如Grammarly、图像生成模型Imagen等可以划为该阶段,主要也是在技能水平上达标了,通用性还不够。
第四阶段为“大师级”(Virtuoso),可达到正常人类99%的水平。
深蓝、AlphaGo等都属于。同样,还没有哪个AI产品可以达到属于这一级别的通用能力。
最后一阶段为“超人级”(Superhuman),在技能指标上,已经可以超越顶尖科学家的AlphaFold、AlphaZero也可划入该阶段。
毫无疑问,具备超人智能级通用性的AI还没诞生。
从中我们看出,按照谷歌这个标准来看,大多数已有AI产品其实都分别进入了不同的AGI阶段,但只仅限于在技能水平上——要谈及通用性,目前只有ChatGPT等模型完全合格。
但它们也只还处于最底层的“一级AGI”阶段。
不过,正如原则2所说,评价AGI就是要看这技能水平和通用性这两个指标,这样划分也算说得过去。
值得一提的是,我们可以看到,像DALLE-2这样的图像生成模型已经可以归类于“三级AGI”。
谷歌给出的理由是,因为它生成的图像已经比大多数人都要强了(也就是超越90%人类)。
这一划分并未考虑大多数用户由于提示技巧不佳,无法达成最佳性能的情况。
因为遵循原则4,我们只需要关注一个系统的潜力到了就够了。
另外,对于最终阶段的AGI,谷歌畅想,它除了蛋白质结构预测,还可能能同时进行与动物交流、分析大脑信号、进行高质量预测等各种人类难以企及的任务,这样才不枉费我们的期待。
最后,对于这个层级划分,谷歌也承认还有很多事情要做:
比如在通用性维度上,应该用哪些标准任务集进行测量?完成多大比例的任务才行?有哪些任务是一定要满足的?
这些问题一时都不大可能全部摸清。
你同意谷歌提出的这些原则和阶段划分吗?
原文:
https://huggingface.co/papers/2311.02462
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10

相关阅读

谷歌开源“穷人版”摘要生成NLP模型:1000个样本就能打败人类
BERT、GPT-2、XLNet等通用NLP模型都是“通才”,虽然全面,但在面向特定任务时需要微调,训练数据集也十分庞大,非一般人所能承受。 有没有一个非通用NLP模型,专门针对某项具体任务,在降低训练成本的同时,性能又有提高呢?这就是谷歌发布的“天马”(**PEGASUS**)模型,它专门为机器生成摘要而生,刷新了该领域的SOTA成绩>>>