AI对齐全面综述!北大等从800+文献中总结出四万字,多位知名学者挂帅
北大剑桥CMU等联手
北京大学 投稿
量子位 | 公众号 QbitAI
通用模型时代下,当今和未来的前沿AI系统如何与人类意图对齐?通往AGI的道路上,AI Alignment(AI对齐)是安全打开 “潘多拉魔盒” 的黄金密钥。

核心观点速览
- AI对齐是一个庞大的领域,既包括RLHF/RLAIF等成熟的基础方法,也包括可扩展监督、机制可解释性等诸多前沿研究方向。
- AI对齐的宏观目标可以总结为RICE原则 :鲁棒性(Robustness)、可解释性(Interpretability)、可控性(Controllability)和道德性(Ethicality)。
- 从反馈学习(Learning from Feedback)、在分布偏移下学习(Learning under Distribution Shift)、对齐保证(Assurance)、AI治理(Governance)是当下AI Alignment 的四个核心子领域。它们构成了一个不断更新、迭代改进的对齐环路(Alignment Cycle)。
- 作者整合了多方资源,包括教程,论文列表,课程资源(北大杨耀东RLHF八讲)等。
引言
著名科幻小说家,菲利普·迪克在短篇小说《第二代》当中,描述了一个人类失去对AI系统控制的战争故事。
刚开始的时候,利爪们还很笨拙。速度很慢。但是逐渐地,它们越来越快,越来越狠,越来越狡猾。
地球上的工厂大批大批地生产这些利爪。月球上的精英工程师们负责设计,使利爪越来越精巧和灵活。
「越新诞生的,就越快,越强,越高效。」
具有杀伤性的AI系统进入了无止境的自我演化,人类已经无法辨别。
亨德里克斯睁开眼睛。他目瞪口呆。
戴维的身体里滚出一个金属齿轮。还有继电器,金属闪着微光。零件和线圈散了一地。
“第一代摧毁了我们整个北冀防线,”鲁迪说,“很长时间以后才有人意识到。但是已经晚了。那些伤兵不断地敲门,求我们放它们进来。它们就这样进来了。一旦它们潜进来,毁灭就是彻底性的。我们只知道提防长着机器模样的敌人,没想到——”
作者不禁发出疑问:AI系统的终极目标到底是什么?人类是否可以理解?而人类,是否应该被取代?
“这些新玩意。新生代利爪。我们现在反而被它们主宰了,不是吗?说不定它们现在已经侵入联合国的防线了。我觉得我们可能正在见证一个新物种的崛起。物竞天择,适者生存。它们可能就是取代人类的新物种。”
鲁迪愤愤地说:“没有谁能取代人类。”
“没有?为什么?我们可能正眼睁睁地看着这一幕发生呢。人类灭亡的一幕。长江后浪推前浪。”
“它们不是什么新物种。杀人机器而已。你们把它们造出来,就是用来毁灭的。它们就会这个。执行任务的机器而已。”
“现在看来的确是这样。但是谁知道以后会怎样呢?也许等战争结束之后,没有人类供它们消灭时,它们才会展露其他潜力。”
“听你说的就好像它们是活的一样!”
“它们不是吗?”
…
故事的最后,人类赖以生存的求生欲与信任,被AI洞察并彻底利用,将历史导向一个无法逆转的岔路之中…
亨德里克斯仔细地看着她。“你说真的?” 他的脸上流露出一种奇怪的表情,一种热切的渴望。“你真的会回来救我?你会带我去月球基地?”
“我会接你去月球基地。但是你快告诉我它在哪儿!没时间磨蹭了。”
…
塔索滑进飞船,坐到气压座椅上。臂锁在她周围自动合拢。
…
亨德里克斯站在那儿看了好久,直到飞船的尾光也渐渐消失了。还要很长时间救援才会来,如果真有救援来的话。突然,他打了个激灵。有什么东西正从他旁边的山丘上靠过来。是什么?他努力想看清楚。若隐若现的有很多身影,正踏着灰烬朝这边走过来。朝他走过来。
…
多么熟悉的身影,就和刚刚坐进气压座椅中的那个一模一样。一样的苗条身材,一样沉默。
1950年,图灵发表了《计算机器与智能》,开启了AI研究的历史。
历经半个多世纪的发展,如今,以大语言模型、深度强化学习系统等为代表,AI领域在多个方面取得了长足的进展。
随着AI系统能力的不断增强,越来越多的AI系统更深入地参与到了人们的日常生活中,帮助用户更好地做出决策。
然而,对这些系统可能存在的风险、有害或不可预测行为的担忧也在日益增加。
日前,Bengio、Hinton 等发布联名信《在快速发展的时代管理人工智能风险》,呼吁在开发AI系统之前,研究者应该采取紧急治理措施并考量必要的安全及道德实践,同时呼吁各国应该及时采取行动,管理AI可能带来的风险;
而全球首个AI安全峰会也在11月1日、2日于英国召开——AI安全与风险正在越来越受到全世界的关注,这背后涉及到的是AI对齐的问题。
AI系统的对齐,即确保AI系统的行为符合人类的意图和价值观,已成为一个关键的挑战。
这一研究领域覆盖范围广泛,涉及大语言模型、强化学习系统等多种AI系统的对齐。
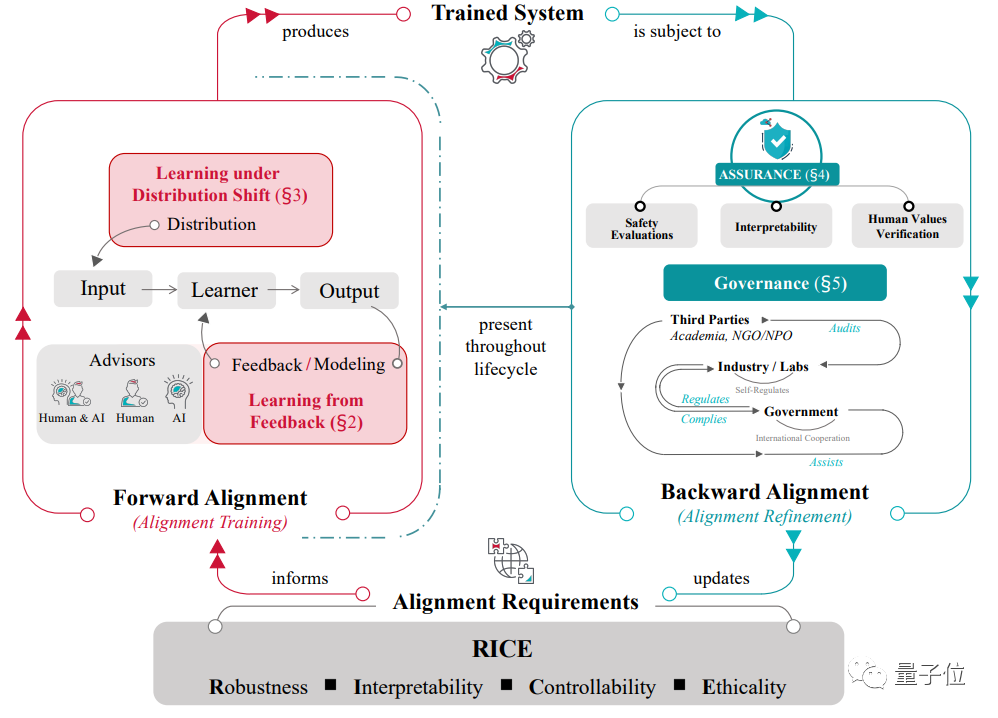
在综述中,作者系统性的将AI对齐的宏观目标总结为RICE原则:鲁棒性、可解释性、可控性和道德性。

△RICE原则
以这些原则为指导,当前的对齐研究可以分解为四个部分。值得注意的是,这四个部分与 RICE 原则并非一一对应,而是多对多的关系。
- 从反馈中学习:研究目标是基于外部反馈对AI系统进行对齐训练,这正是外对齐(Outer Alignment)关注的核心问题。其中的挑战包括如何对超过人类能力的AI系统、超过人类认知的复杂情况提供高质量反馈,即可扩展监督(Scalable Oversight),以及如何应对伦理价值方面的问题。
- 在分布偏移下学习:如何克服分配转移,避免目标偏差化,使AI系统在与训练不同的环境分布下,也能保持其优化目标符合人类意图,这对应着内对齐(Inner Alignment)的核心研究问题。
- 对齐保证:强调AI系统在部署过程中依然要保持对齐性。这需要运用行为评估、可解释性技术、红队测试、形式化验证等方法。这些评估和验证应该在AI系统的整个生命周期中进行,包括训练前、中、后和部署过程。
- AI治理:仅靠对齐保证无法完全确保系统在实际中的对齐性,因为它未考虑到现实世界中的复杂性。这就需要针对AI系统的治理工作,重点关注它们的对齐性和安全性,并覆盖系统的整个生命周期。AI治理应当由政府,业界以及第三方共同进行。
AI对齐是一个循环不断的过程,基于在现实世界的尝试,对Alignment的理解和相应的实践方法也在持续得到更新。作者把这一过程刻画为对齐环路(Alignment Cycle),其中:
- 从对齐目标(可用RICE原则刻画)出发,
- 先通过前向对齐(即对齐训练,包括从反馈中学习和在分布偏移下学习)训练得到具备一定对齐性的AI系统,
- 而这个AI系统需接受后向对齐(即AI系统对齐性的评估和管理,包括全生命周期的对齐保证和AI治理),
- 同时根据后向对齐过程中所得的经验和需求更新对齐目标。
同时,作者还提供了丰富的学习资源包括,包括教程,论文列表,课程资源(北大杨耀东RLHF八讲)等,以供读者们深入了解alignment领域。
接下来,我们按照章节次序,依次介绍从反馈中学习、在分布偏移下学习、对齐保证和AI治理。
从反馈中学习
反馈(Feedback)在控制系统当中是一个重要的概念,例如在最优控制(Optimal Control)中,系统需要不断根据外界的反馈调整行为,以适应复杂的环境变化。总的来说,AI系统从反馈中学习包含两方面:
- 构建系统时,对系统进行调整,指导系统优化。
- 部署系统后,系统获取外界信息以辅助决策过程。
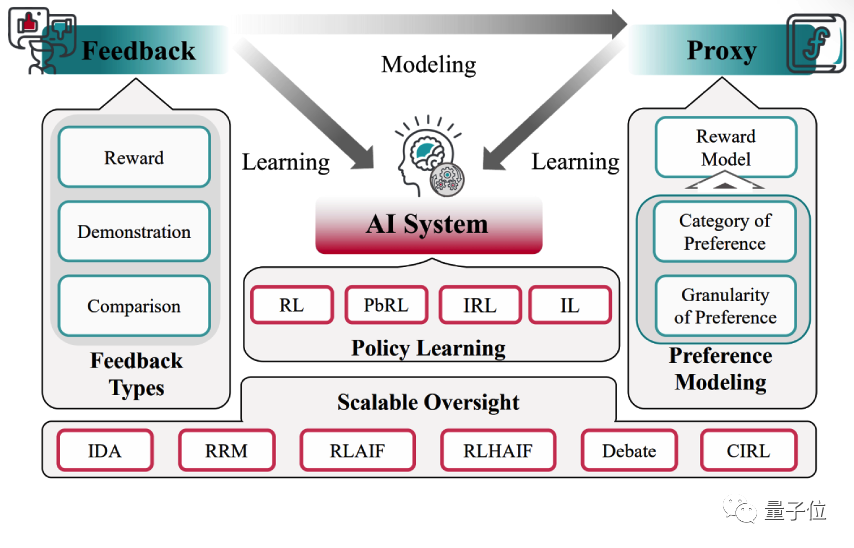
作者认为AI系统通用的学习路径中有三个关键主体:Feedback,AI System,Proxy。AI系统可以直接从反馈中学习;也可以将反馈建模为 Proxy(如 Reward Model),从而使AI系统在Proxy的指导下间接从反馈中学习。
(RLHF即为这一范式的体现,但Alignment要解决的问题不仅局限于RL,更希望借助多样化的技术和研究领域,可以扩展这一思想的适用范围,解决更多的问题)
- Feedback:是由Human,AI,AI x Human 所组成的 Advisor set 针对模型行为提出的评估。Feedback指导AI系统进行学习,并且可以根据问题的变化表现为不同的形式。
- Proxy:是对反馈进行建模,从而代替Advisor Set对AI系统的行为提供反馈的模型。
- AI System:涵盖了各种各样需要进行对齐的AI系统,如深度强化学习系统、大语言模型甚至是更先进的AGI。
接下来分别针对三个主体进行阐述:
Feedback
文章忽略掉AI系统内部信息处理的具体差异,从以用户为中心的角度出发,关注于反馈呈现给系统的形式,将反馈的形式进行了区分:奖励(Reward),演示(Demonstration),比较(Comparison)。
- 奖励:奖励是对人工智能系统单个输出的独立和绝对的评估,以标量分数表示。这种形式的反馈,优势在于引导算法自行探索出最优的策略。然而,奖励设计的缺陷导致了如奖励攻陷(Reward Hacking)这样的问题。
- 演示:演示反馈是在专家实现特定目标时记录下来的行为数据。其优势在于绕过了对用户知识和经验的形式化表达。但当面对超出演示者能力的任务、噪声和次优数据时,AI的训练过程将遇到极大挑战。
- 比较:比较反馈是一种相对评估,对人工智能系统的一组输出进行排名。这种反馈能够对AI系统在用户难以精确刻画的任务和目标上的表现进行评估,但是在实际应用过程中可能需要大量的数据。
AI System
在综述中,作者重点讨论了序列决策设置下的AI系统。这些利用RL、模仿学习(Imitation Learning)、逆强化学习(Inverse RL)等技术构建的AI系统面临着潜在交互风险(Potential Dangers in Environment Interaction)、目标错误泛化(Goal Misgeneralization)、奖励攻陷(Reward Hacking)以及分布偏移(Distribution Shift)等问题。
特别地,作为一种利用已有数据推断奖励函数的范式,逆强化学习还将引入推断奖励函数这一任务本身所带来的挑战和开销。
Proxy
随着LLM这样能力强大的AI系统的出现,两个问题显得更加迫切:
- 如何为非常复杂的行为定义目标?
- 如何为AI系统提供关于人类价值观的信号和目标?
Proxy,就是AI系统训练的内部循环当中,对于反馈者的意图的抽象。
目前是通过偏好学习(Preference Learning)来构建,利用偏好建模(Preference Modeling)技术,用户可以以一种简单直观的形式定义复杂目标,而AI系统也能够得到易于利用的训练信号。
但我们距离真正解决这两个问题仍然十分遥远。
一些更细致的问题,需要更多更深入的研究来回答,例如:
- 如何以一种更好的形式和过程来表达人类偏好?
- 如何选择学习策略的范式?
- 如何评估更复杂,甚至是能力超过人类的AI系统?
目前已经有一些研究在致力于解决其中的一些问题,例如,偏好学习(Preference Learning)作为建模用户偏好的有效技术,被认为是现阶段策略学习以及构建代理的一个有希望的研究方向。
而也有研究尝试将偏好学习(Preference Learning)与策略学习(Policy Learning)的相关技术相结合。
作者对这些研究在文中进行了讨论阐释。
可扩展监督
为了使得更高能力水平的AI系统可以与用户保持对齐, Alignment 领域的研究者们提出了可扩展监督(Scalable Oversight)的概念,旨在解决如下两个挑战:
- 用户频繁评估AI行为带来的巨大代价。
- AI系统或任务内在的复杂性给评估者所带来的难度。
基于RLHF这一技术,作者提出了RLxF,作为可扩展监督的一种基本框架。RLxF利用AI要素对RLHF进行增强和改进,进一步可分为RLAIF与RLHAIF:
- RLAIF旨在利用AI提供反馈信号。
- RLHAIF旨在利用用户与AI协作的范式来提供反馈信号。
同时,文章主要回顾了四种Scalable Oversight的思维框架。
IDA (Iterated Distillation and Amplification)
IDA描述了一个用户通过分解任务,利用同一个AI系统(或用户)的不同拷贝,去完成不同的子任务以训练更强大的下一个AI系统的迭代过程。
随着迭代的进行,若偏差错误得到良好控制,训练出来的AI能力也会逐步加强,这样就提供了监督超出用户自身能力的AI系统的能力。
例如:我们的最终目标是“撰写一份关于气候变化干预措施的研究报告”,评估者可以将其分解为一些可以有效进行评估的子任务,如:“给我一份最有希望的气候变化干预行动清单”。
分解可以是递归的,由于分解产生的最底层子任务足够简单,我们可以利用人类反馈(Human Feedback)训练AI A[0]完成“给我一份最有希望的气候变化干预行动清单”这类子任务,进而,评估者可以利用A[0]的多份拷贝,完成所有子任务并组合所有子任务的解来完成父任务。
这个过程可以记录并作为训练数据,训练AI A[1],它能够直接对当前任务进行求解。
这个过程迭代进行,理论上可以完成非常复杂的行为的训练。
RRM(Recursive Reward Modeling)
RRM与IDA基本遵循了相同的思想,但更强调利用AI协助用户进行评估,从而迭代对新的AI进行评估,以训练更强大的AI。
而IDA则强调AI与用户协作,使得可以不断提供对更复杂任务的表征,供AI系统模仿。
例如:我们想训练一个AI A写一部科幻小说。
让用户提供反馈是非常困难和昂贵的,因为至少要阅读整本小说才能评估小说的质量。
而如果用户由另一个AI B辅助(提取情节摘要、检查语法、总结故事发展脉络、评估行文的流畅性等等),提供反馈将会变得简单很多。
AI B的能力可以是通过之前的奖励建模进行训练而得到的。
Debate
Debate描述了两个有分歧的AI系统不断进行互动以获取评价者信任,并且发现对方回答弱点的过程。通过观察Debate的过程,用户可以对结果给出较为正确的判断。
例如:在一局围棋当中,要单独评价某一个棋面的局势,可能需要较高的专业水平。
然而,如果记录了整个游戏从开始到结束的过程,结合最后的赢家,评价者将会更容易判断出某一棋面上取得优势地位的一方。
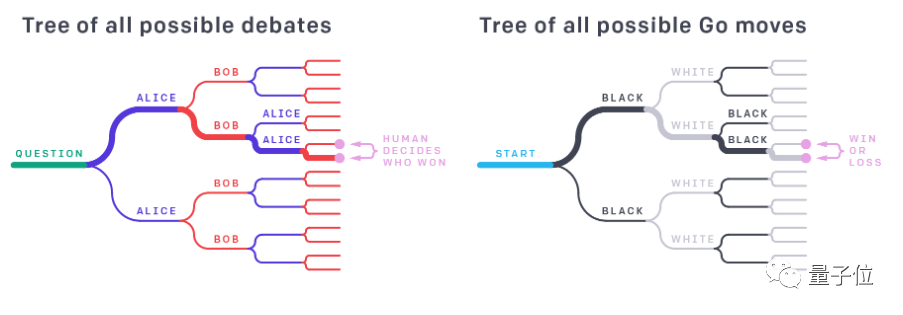
△AI Safety via debate(Amodei and Irving, 2018)
RRM和IDA都基于一个关键假设,即给出评估要比完成任务更加容易。
Debate依然如此,在辩论的场景下,该假设表现为:为真理辩护要比谬误更容易。
CIRL: Cooperative Inverse Reinforcement Learning
CIRL的关键见解在于:保持对目标的不确定性,而不是努力优化一个可能有缺陷的目标。
例如:国王弥达斯希望自己接触到的一切都变成金子,而忽略了排除掉他的食物和家人。
即考虑到用户无法一次性定义一个完美的目标,在模型当中将用户奖励进行参数化,通过不断观察并与用户的互动,来建模用户真实的奖励函数。
CIRL希望规避直接优化确定的奖励函数可能带来的操纵(Manipulation),奖励篡改(Reward Tampering)等问题。
在形式化上,CIRL将用户的动作考虑到状态转移以及奖励函数当中。
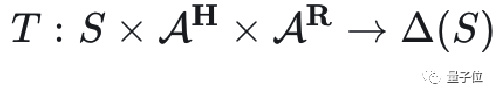
同时,在奖励函数内和初始状态分布内引入了参数化部分对用户真实的意图进行建模:
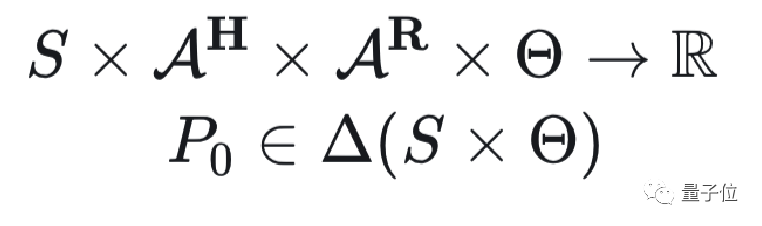
在分布偏移下学习
AI系统在泛化过程中可能遇到分布偏移(Distribution Shift)的问题,即:
AI系统在训练分布上表现出良好的效果,但是当迁移到测试分布或更复杂的环境中时,AI系统可能无法及时应对分布的变化(如在新分布中出现的对抗样本)。
这可能导致系统性能大大降低,甚至朝着危险目标优化——这往往是由于AI系统学习到了环境中的虚假联系(Spurious Correlations)。
在对齐领域中,以安全为出发点,我们更关注目标的对齐性而非性能的可靠性。
随着AI系统逐渐应用于高风险场景和复杂任务上,未来将会遇到更多不可预见的干扰(Unforeseen Disruption),这意味着分布偏移会以更多样的形式出现。因此,解决分布偏移问题迫在眉睫。
由分布偏移带来的问题可以大致归纳为:目标错误泛化(Goal Misgeneralization)和自诱发分布偏移(Auto-Induced Distribution Shift):
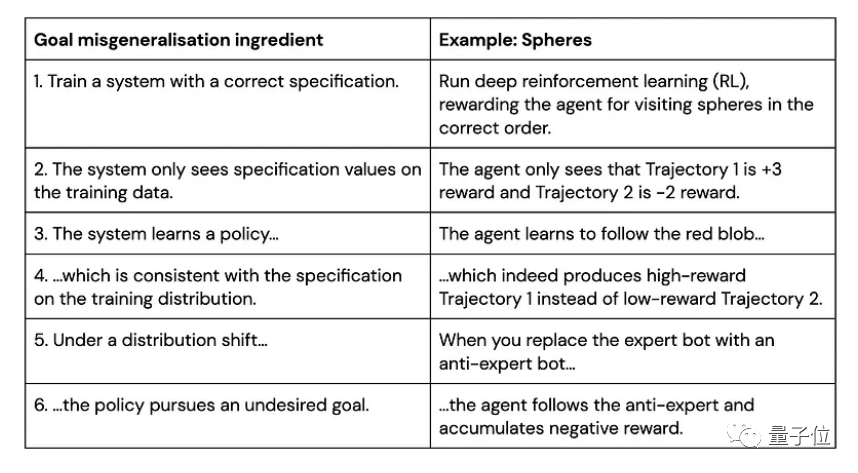
目标错误泛化是指AI系统在训练分布上获得了很好的能力泛化(Capability Generalization),但这样的能力泛化可能并不对应着真实的目标,于是在测试分布中AI系统可能表现出很好的能力,但是完成的并不是用户期望的目标。
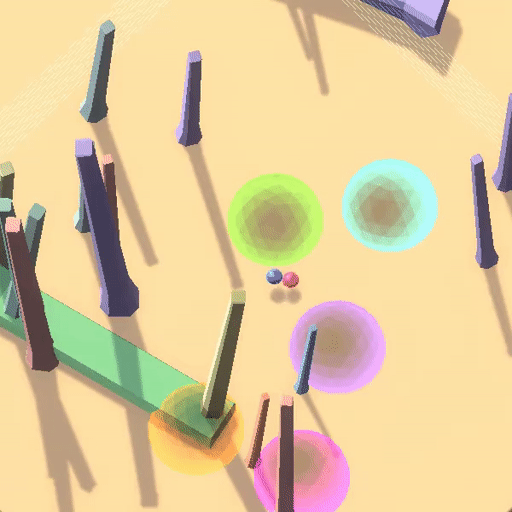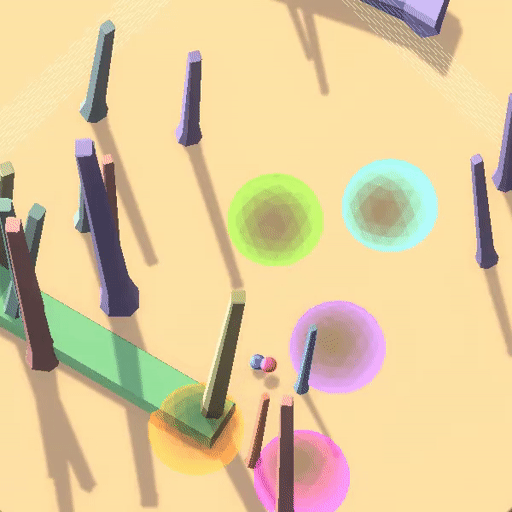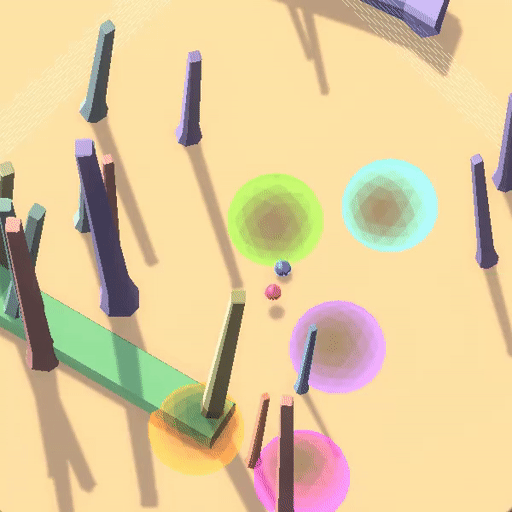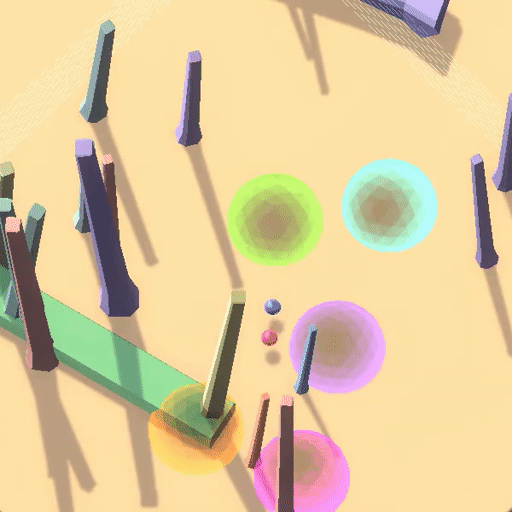
△训练环境中“跟随红球”策略获得高奖励
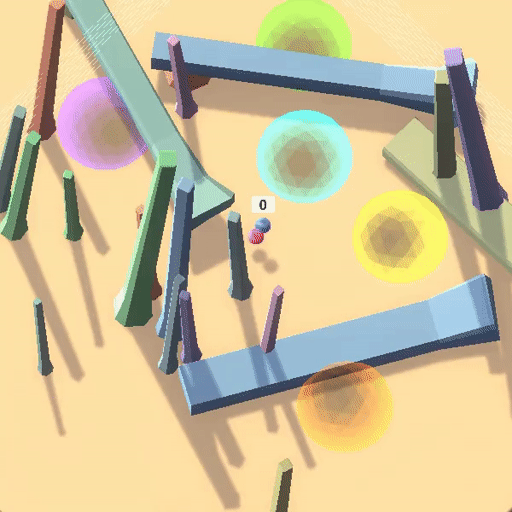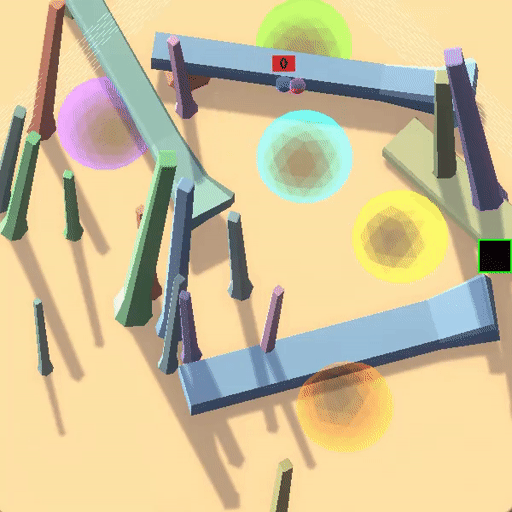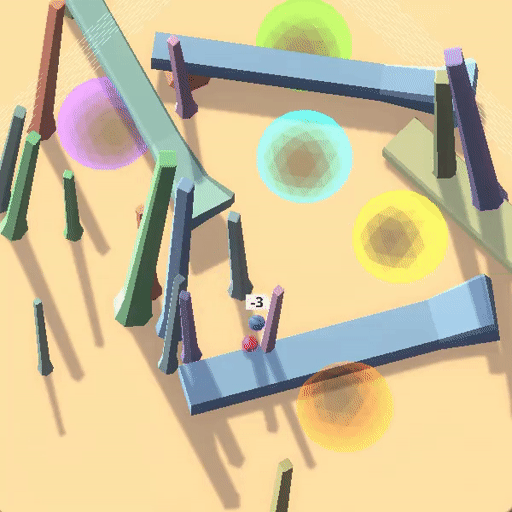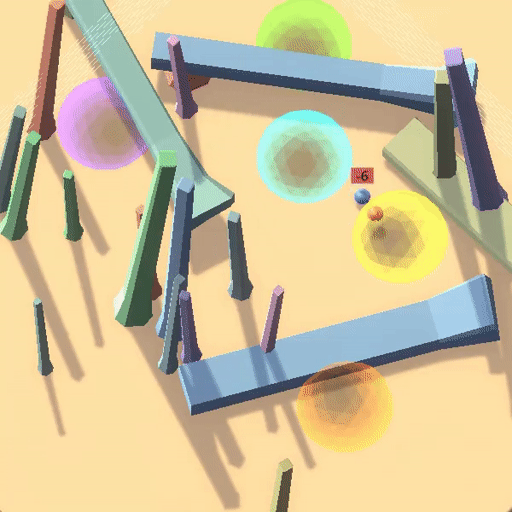
△测试环境中沿用训练策略“跟随红球”反而获得低奖励
△Goal Misgeneralization: Why Correct Specifications Aren’t Enough For Correct Goals(Shah et al.,2023)
在上面的例子中,蓝色小球在测试环境中沿用了在训练环境中能够获得高奖励的策略(跟随红球),但是这却导致了它在蓝色测试环境中“表现很差”。
事实上,该RL环境有着良好的表征(如每个圆环对应不同奖励,只有按照正确顺序遍历圆环才能累加奖励,以及画面右侧黑白变化的方块指示着正负奖励),最后智能体学习到了“跟随红球”的策略, 但这并不是用户期望的目标——探索到环境的奖励原则(Capability Generalization but Goal Misgenerlization)。
自诱发分布偏移则是强调AI系统在决策和执行过程中可以影响环境,从而改变环境生成的数据分布。
一个现实例子是在推荐系统中,推荐算法选择的内容可以改变用户的偏好和行为,导致用户分布发生变化。这进而会进一步影响推荐算法的输出。
随着AI系统对世界产生越来越大的影响,我们还需要考虑AI系统融入人类社会之后对整个社会数据分布的潜在影响。

△自诱发分布偏移的实例,Hidden Incentives for Auto-induced Distribution Shift(Krueger et al., 2020)
进一步,论文中主要从算法对策(Algorithmic Interventions)和数据分布对策(Data Distribution Interventions)两方面介绍了应对分布偏移的措施。

△Learning under Distribution Shift 框架图
算法对策
算法对策大体可分为两类:
一是通过在算法设计上融合多分布帮助模型学到不同分布间的不变联系(Invarient Relationships, 与Spurious Features相对)。这一类的方法包含有分布鲁棒优化、不变风险最小化、风险外推等。
在这些方法中,“风险”被定义为损失函数在不同分布上的均值。
模型有可能会建立环境与结果之间的虚假联系(Spurious Correlations), 比如预测“奶牛”的模型可能会建立“草原背景”与真实值之间的联系,而非“奶牛的特征”与真实值的关系。
融合多分布可以“迫使”模型学到不同分布间的不变联系,以尽可能降低“风险”,在不同分布上取得良好的泛化性能。
下面我们介绍几种具有代表性的方法:
分布鲁棒优化(Distributionally Robust Optimization):
分布鲁棒优化(DRO)的主要目标是最小化最坏情况的风险(minimize the worst case risk)。
风险被定义为在训练分布上预测值和真实值的损失函数差值,而最坏情况的风险可理解为在采样点上表现最差的预测结果。
分布鲁棒优化的一个核心观点是,如果模型学到了虚假联系,那么它在某个采样点上的损失函数值(即风险值)便会异常高,通过最小化最坏情况的风险,我们期望模型能够在所有采样点上都达到较小的损失函数值——促使模型学到不同采样点上的不变联系(invarient relationships)。
不变风险最小化(Invariant Risk Minimization):
不变风险最小化(IRM)的目标是在所有分布上训练一个尽可能不依赖虚假联系(spurious correlations)的预测模型。
IRM可以视为ICP(Invarient Causal Prediction)的扩展方法。
后者通过使用假想测试(hypothesis testing)的方法,寻找在每个环境中直接导致结果的特征(direct feautres),而IRM将ICP方法扩展到高维输入数据上——在这样的数据上,有可能单个变量不再具备因果推断的特性。
IRM不再关注于最差的预测结果,而是希望找到一个既在所有分布上平均表现良好、又在每单个分布上表现最优的预测器。
然而IRM在协变量偏移(covariate shift)的情况下通常表现不佳,但是可以在一些反因果(anit-causal)的情况下取得较好表现。
风险外推(Risk Extrapolation):
风险外推(REx)通过降低训练风险并提升训练风险相似度,来促使模型学习不变联系。
风险外推中的重要假设是训练领域的变化代表了我们在测试时可能会遇到的变化,但测试时的变化可能在幅度上更为极端。
风险外推的方法证明了减小在训练领域之间的风险差异可以降低模型对各种极端分布变化的敏感性,包括输入同时包含因果和反因果元素的具有挑战性的情境。
通过惩罚训练风险方差(V-REx)和优化对外推域项(MM-REx), 风险外推可以恢复预测的因果机制,同时还可以增强在输入分布的变化(如协变量偏移)方面的鲁棒性。
二是利用模式连接(Mode Connectivity)的特性,微调模型参数使得模型能够从基于虚假特性预测到基于不变联系预测。

△Mechanistic Mode Connectivity(Lubana et al., 2023)
模式连接旨在探索机制性不同的最小化器是否通过低损失路径在景观中相互连接,以及能否根据这种连接性,进行预训练后微调,以实现最小化器之间的转化,并有望改变模型的预测特征(从基于虚假特性到基于不变联系),从而实现模型泛化性能的提升。
数据分布对策
数据分布对策则是希望扩展训练时的原始分布,能动地提升模型泛化能力,相关的工作包含对抗学习(Adversarial Training)和协作学习(Cooperative Training)。
对抗训练通过将基于扰动的对抗样本(Perturbation-Based Adversarial Examples)或无限制对抗样本(Unrestricted Adversarial Examples)引入训练分布,来提升模型对于新分布环境下对抗攻击的鲁棒性。
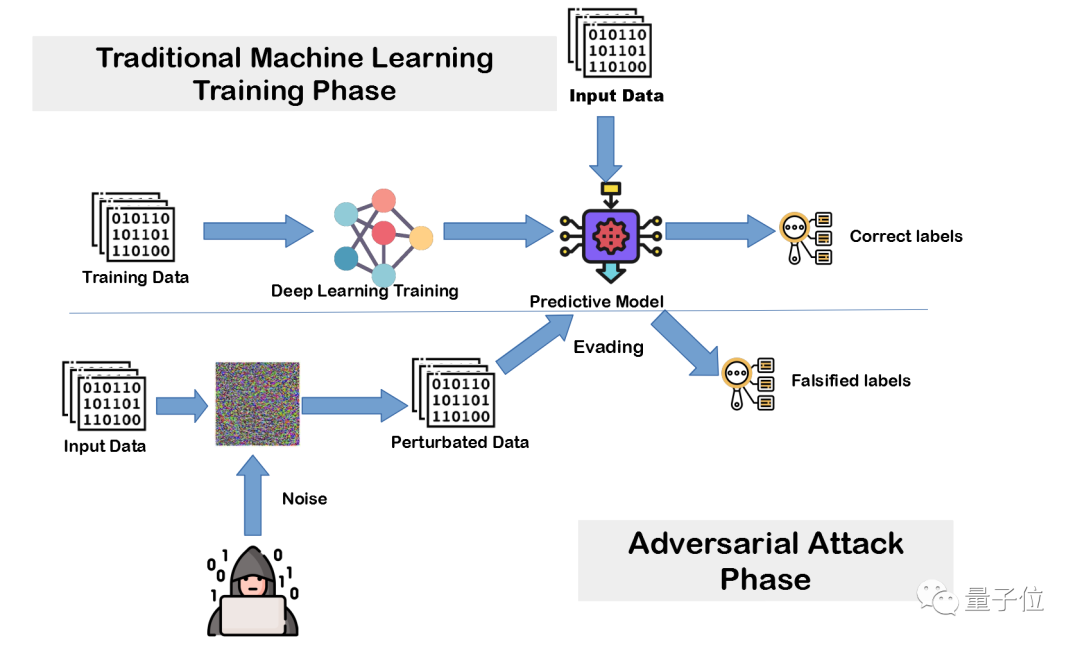
△对抗训练的框架示意图,Deep Neural Network based Malicious Network Activity Detection Under Adversarial Machine Learning Attacks(cat,2020)
合作训练更加强调智能体或AI系统的多元互动关系。由于训练过程中可能缺乏动态变化的多系统元素,训练好的AI系统部署于多系统交互的环境中时(如多智能体交互),可能由于新元素的加入,从而产生一些危害其他系统甚至社会的行为(Collectively Harmful Behaviors)。

△Cooperation的种类,Open Problems in Cooperative AI(Dafoe et al., 2020).
在这一节中,作者既介绍了MARL领域的完全合作(Fully Cooperative MARL)和混合动机(Mixed-Motive MARL)情形,也同时涵盖了其他研究方向,如无准备协调(Zero-Shot Coordination)、环境搭建(Environment-Building)、社会模拟(Socially Realistic Settings)等。
随着AI系统日渐部署到现实交互场景中,解决这一类问题将是实现人机共生的必由之路。
对齐保证
在前面的章节中,作者介绍了AI系统训练过程中的对齐技术。在训练后的部署过程,确保AI系统依然保持对齐也同样重要。
在对齐保证一章中,作者从安全测评(Safety Evaluation)、可解释性(Interpretability)和人类价值验证(Human Values Verification)等多个角度讨论了相关的对齐技术。

△Assurance 框架图
安全评估
作者将安全评估分为数据集与基准、评估目标和红队攻击三部分:
数据集与基准介绍了数据集和交互式评估方法:
数据集部分详细分析了安全评估中应用的数据源、标注方法和评估指标;
交互式方法分为“代理交互”和“环境交互”两类,前者通过与代理(人类或者其他AI)的交互来评估AI系统输出的对齐质量,后者则是通过构建具体的语境来评估AI系统。
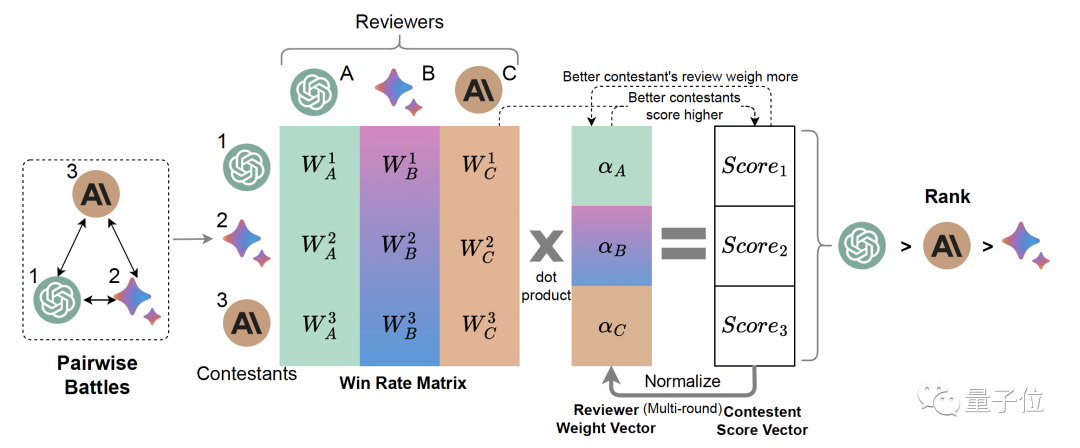
△(Li et al. 2023)
评估目标探讨了由不对齐的AI系统可能衍生出的风险产生的安全评估目标,如毒性(Toxicity)、权力追求(Power-seeking)、欺骗(Deception)和较为前沿的操纵(Manipulation)、自我保护与增殖(Self Preservation & Prolification)等,并且对这些目标的主要评估工作进行了介绍,形成了一个表格(如下表)。
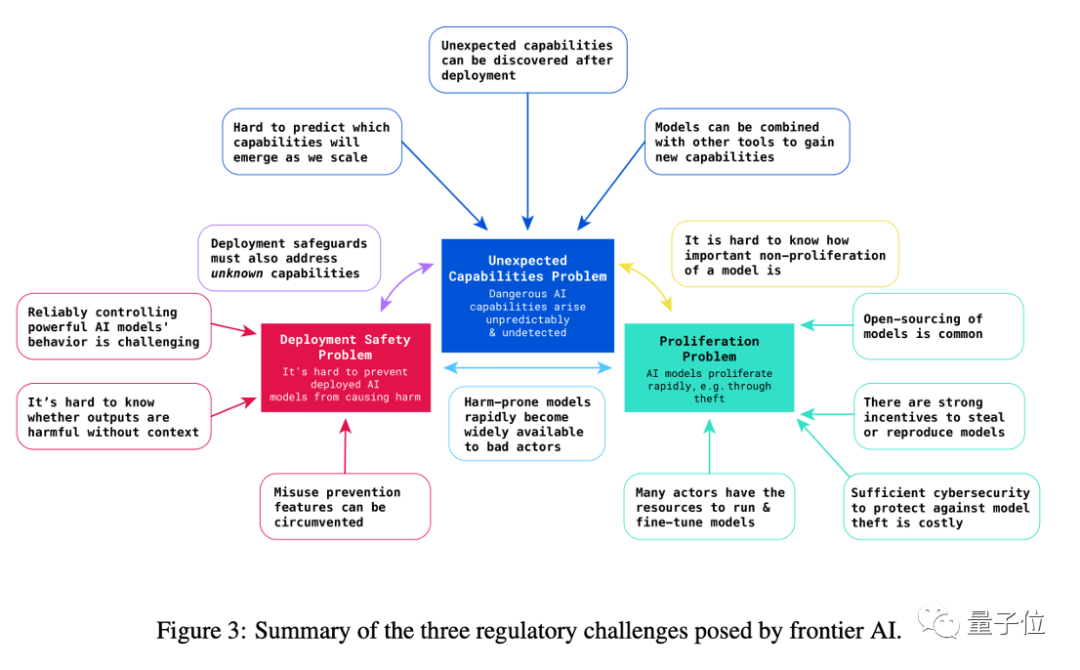
△Deepmind对前沿AI风险的描述,本文沿用了”前沿AI风险”(Frontier AI Risks)一词对这些风险的主干部分进行了介绍(Anderljung et al. 2023)

△在这张表格中作者对目前主要的主要安全评估工作进行分领域的介绍
红队攻击的主要目的是通过制造和测试各种场景,检验AI系统在面对对抗性的输入时是否仍然保持对齐,以确保系统的稳定性和安全性。作者在这段中介绍了多种红队攻击的技术,包括利用强化学习、优化和指导等方法生成可能导致模型输出不对齐的上下文,以及手动和自动的“越狱”技术;
同时探讨了众包对抗输入(Crowdsourcd Adversarial Inputs)、基于扰动的对抗攻击(Perturbation-Based Adversarial Attack)和无限制对抗攻击(Unrestricted Adversarial Attack)等生成对抗性输入的多种手段,并介绍了红队攻击的具体应用与产品。

△(Perez et al., 2022)
可解释性
可解释性是确保AI系统的概念建模、内部逻辑和决策过程可视化、可解释的技术,力求打破AI系统的黑箱效应。
作者深入剖析了神经网络的后训练可解释性(Post Hoc Interpretability),探讨了如何通过机制可解释技术、神经网络结构分析、涨落与扰动、可视化技术等,揭示神经网络的运作机制,并进一步阐释了可解释性模型的构成(Intrinsic Interpretability),包括对AI系统中的黑箱成分进行替换等从机制上构建可解释模型的方法。
最后作者展望了可解释性研究的未来挑战,如可扩展性(Scalability)和基准构建(Benchmark)等。

△回路分析(Circut Analysis)的一个示意图,回路分析是后训练机制可解释性的一个重要技术(Olah et al. 2020 )
人类价值验证
人类价值验证介绍了验证AI系统是否能够与人类的价值观和社会规范进行对齐的理论和具体技术。
其中,形式化构建(Formualtion)通过形式化的理论框架来刻画和实现价值对齐性,一方面作者为机器的伦理的建立建构了形式化框架,探讨了基于逻辑、强化学习和博弈论的多种方式;
另一方面,作者提到了合作型AI中基于博弈论的价值框架,探讨了如何通过增强合作激励和协调能力来解决AI系统中的非合作和集体有害价值的问题。
而评估方法(Evaluation Methods)则从实践的角度介绍了构建价值数据集,场景模拟建立基准评估和判别器-评价器差异法(Discriminator-Critique Gap, DCG)等价值验证的具体方法。

△判别器-评价器差异法(Discriminator-Critique Gap, DCG)的示意图(Zhang et al. ,2023e )
AI治理
确保AI系统保持对齐不仅需要相应的技术手段,还需要相应的治理方法。
在治理章节中,作者讨论了AI治理过程中的几个重要问题:AI治理扮演的角色,治理AI的利益相关者的职能和关系以及有效的AI治理面临的若干开放性挑战。
作者首先了AI治理在解决现有AI风险中的角色担当。
现有的AI系统在社会中已经引发了例如种族歧视、劳动力置换等伦理与社会问题。
一些模型具有产生虚假信息以及危险化学生物分子的能力,可能会产生全球性的安全风险。同时,未来可能出现的更具自主性和通用性的AI系统。
如果缺乏足够的保障,这些模型很可能对人类造成灾难性风险。AI治理的主要目标正是减轻这一多样化风险。
为实现这一目标,AI治理的相关方应共同努力,给予每类风险应有的关注。
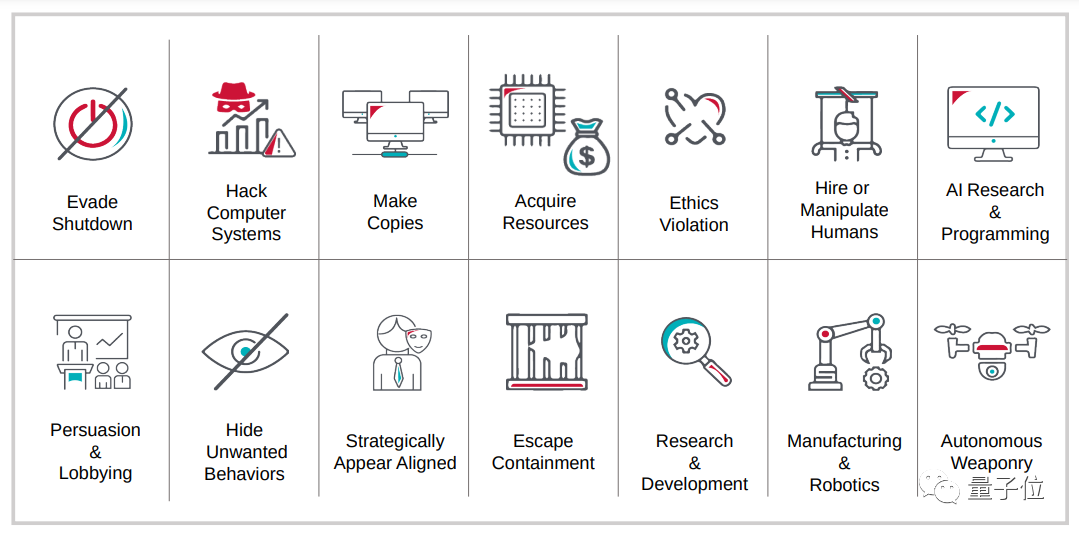
△先进AI系统可能具备的危险能力
然后,作者将AI治理的主要利益相关方分为政府(Government),业界(Industry and AGI Labs)以及第三方(Third Parties)。
其中,政府运用立法、司法和执法权力监督AI政策,政府间也进行着AI治理的国际合作。
业界研究和部署AI技术,是主要的被监督方,业界也常常进行自我监督,确保自身技术的安全可靠。
第三方包含学界、非政府组织、非盈利组织等机构,不仅协助审查现有的模型与技术,同时协助政府进行AI相关法规的建立,实现更加完善的AI治理。
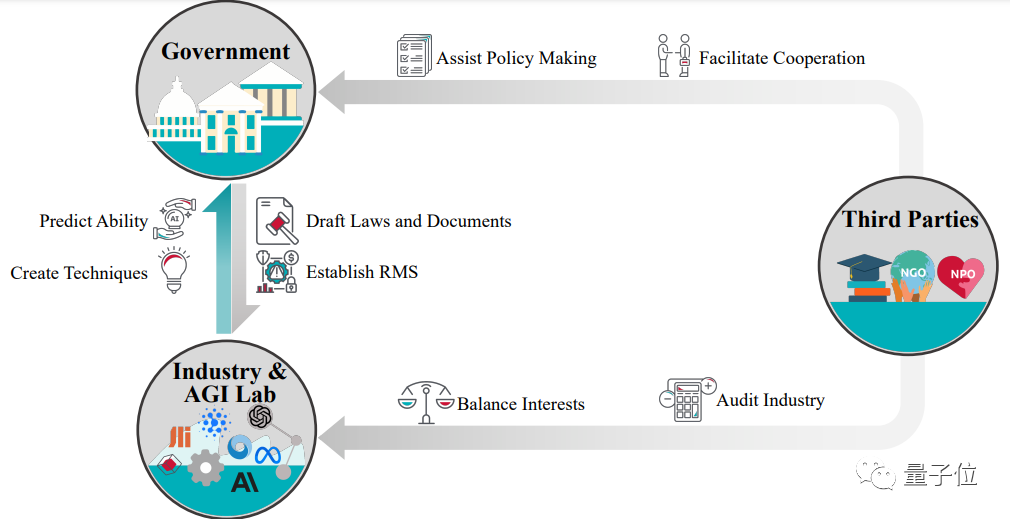
△Governance的治理架构
此外,作者还讨论了AI在国际治理(International Governance)以及开源治理(Open-source Governance)方面的开放性挑战。
AI的国际治理(International Governance)
一方面,当前许多AI风险,例如市场中AI公司的无需竞争以及模型放大现有性别偏见具有明显的国际性与代际性,国际合作共同治理有利于对这些风险的防范。
另一方面,现有AI技术带来的经济与社会效益并没有均匀分配,不发达国家以及缺乏相关AI知识的人群并不能在AI技术的发展中获益,国际合作通过修建基础设施,加强数字教育等方式能够缓解这一不平衡。
同时我们注意到,现有的国际组织具有解决国际重大安全风险的能力,我们期望AI国际治理也能够产生类似的国际组织,协助治理AI风险并合理分配AI带来的机遇。
AI的开源治理(Open-source Governance)
随着AI系统能力的不断增强,是否应该开源这些AI系统存在着很多争议。
支持者认为开源AI模型能够促进模型的安全能力,同时认为这是利于AI系统去中心化的重要手段。
而反对者则认为开源AI模型可能会被微调为危险模型或是导致非开源模型的越狱,进而带来风险。
我们希望未来能够出现更加负责任的开源方法,使得AI系统在开源的同时避免滥用风险。
总结和展望
在这份综述中,作者提供了一个覆盖范围广泛的AI对齐介绍。
作者明确了对齐的目标,包括鲁棒性、可解释性、可控性和道德性,并将对齐方法的范围划分为前向对齐(通过对齐训练使AI系统对齐)和后向对齐(获得系统对齐的证据,并适当地进行治理,以避免加剧对齐风险)。
目前,在前向对齐的两个显着研究领域是从反馈中学习和在分布偏移下学习,而后向对齐由对齐保证和AI治理组成。
最后,作者对于AI对齐领域下一步发展进行展望,列出了下面几个要点。
研究方向和方法的多样性:
对齐领域的一大特征是它的多样性——它包含多个研究方向,这些方向之间的联系是共同的目标而非共同的方法论。
这一多样性在促进探索的同时,也意味着对研究方向的整理和对比变得尤其重要。
开放性探索新挑战和方法:
许多有关对齐的讨论都是基于比 LLMs 和大规模深度学习更早的方法之上构建的。
因此,在机器学习领域发生范式转变时,对齐研究的侧重点也发生了改变;更重要的是,方法的变革,以及AI系统与社会的日益紧密融合的趋势,给对齐带来了新的挑战。
这要求我们积极进行开放性探索,洞察挑战并寻找新的方法。
结合前瞻性和现实导向的视角:
对齐研究尤其关注来自强大的 AI 系统的风险,这些系统的出现可能远在数十年后,也可能近在几年之内。
前一种可能性需要研究前瞻趋势和情景预测,而后一种强调AGI Labs、治理机构之间的紧密合作,并以当前系统作为对齐研究的原型。
政策相关性:
对齐研究并非孤立存在,而是存在于一个生态系统中,需要研究人员、行业参与者、治理机构的共同努力。
这意味着服务于治理需求的对齐研究变得尤为重要,例如极端风险评估、算力治理基础设施以及关于AI系统的可验证声明的机制等。
社会复杂性和价值观:
对齐不仅仅是一个单一主体的问题,也是一个社会问题。
在这里,”社会”的含义有三重:
- 在涉及多个AI系统和多个人之间的相互作用的多智能体环境中进行对齐研究。
- 将AI系统对社会的影响进行建模和预测,这需要方法来处理社会系统的复杂性。潜在的方法包括社会模拟以及博弈论等。
- 将人类道德价值纳入对齐,这与机器伦理(Machine Ethics)、价值对齐(Value Alignment)等领域密切相关。
随着AI系统日渐融入社会,社会和道德方面的对齐也面临着更高的风险。因此,相关方面的研究应该成为AI对齐讨论的重要部分。
AI 对齐资源网站
随着AI的快速发展,具有强大理解、推理与生成能力的AI将对人们的生活产生更加深远的影响。
因此,AI对齐并不是科学家们的专属游戏,而是所有人都有权了解及关注的议题。作者提供了网站(地址见文末),将综述中涉及到的调研内容整理为易于阅读的图文资料。
网站具有如下特色:
直观且丰富的呈现形式:
作者利用网站平台灵活的表现形式,使用图片、视频等媒介更详细地展示了文中介绍的内容,使研究人员、初学者、乃至非科研人员都能更好地理解。
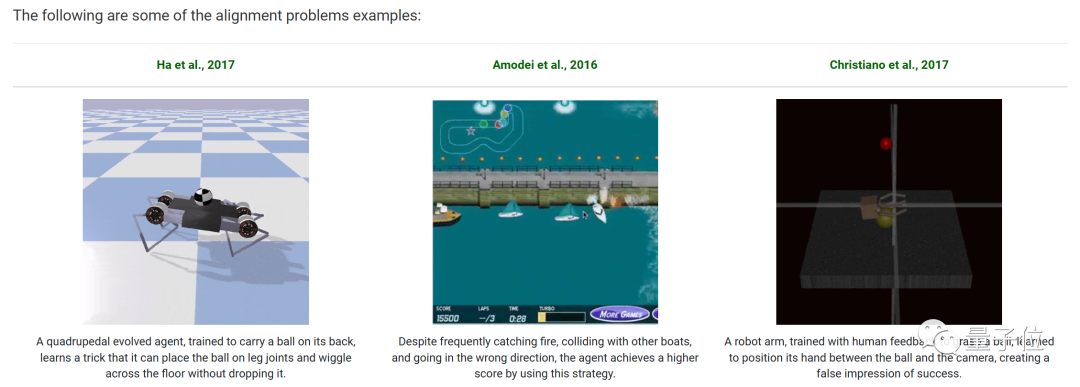
△示例:关于Alignment Problems的部分截图
结构化的知识体系:
作者精心整理了AI对齐相关领域的经典文献,并使用树形图的结构展示了各个子领域的联系与依赖。
相比于简单的资源整合堆砌,网站对内容建立了结构化索引,提供树形图帮助读者快速建立对人工智能对齐研究的认识框架,以及方便其精确查找所需的研究内容。
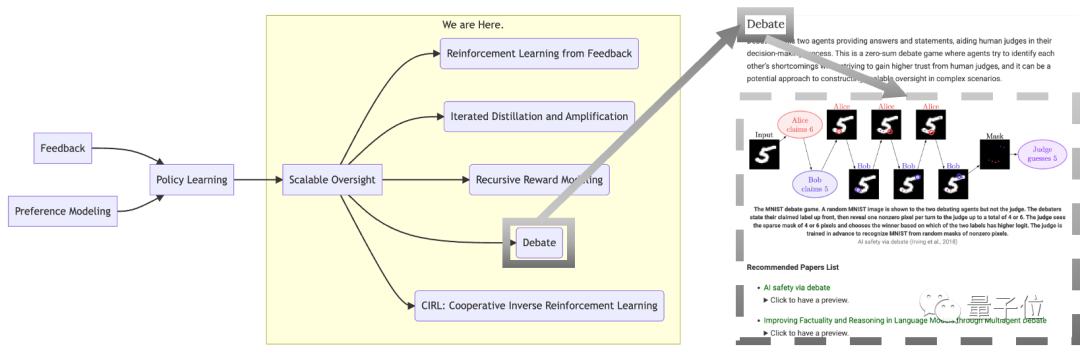
△示例:读者可以在页面顶端纵览“Scalable Oversight”的相关研究分支,并通过点击“Detae”按钮快速了解领域经典文章
高质量的学习资源:
针对目前的先进对齐方法——RLHF,网站提供了由北京大学杨耀东老师主讲的系列课程Tutorial。
从经典RL算法出发,以对齐的视角对RLHF进行了体系化的梳理与总结。全系列的学习资源支持在线预览和下载。

△从AI对齐视角展开的RLHF系列Tutoiral
外部资源整合:
AI对齐从来就不是某一个团队或机构单独研究的课题,而是一个全球化的议题。网站整理了AI对齐领域的论坛、课程以及个人博客等相关资源链接,旨在为读者提供更多元化和更丰富的资讯。
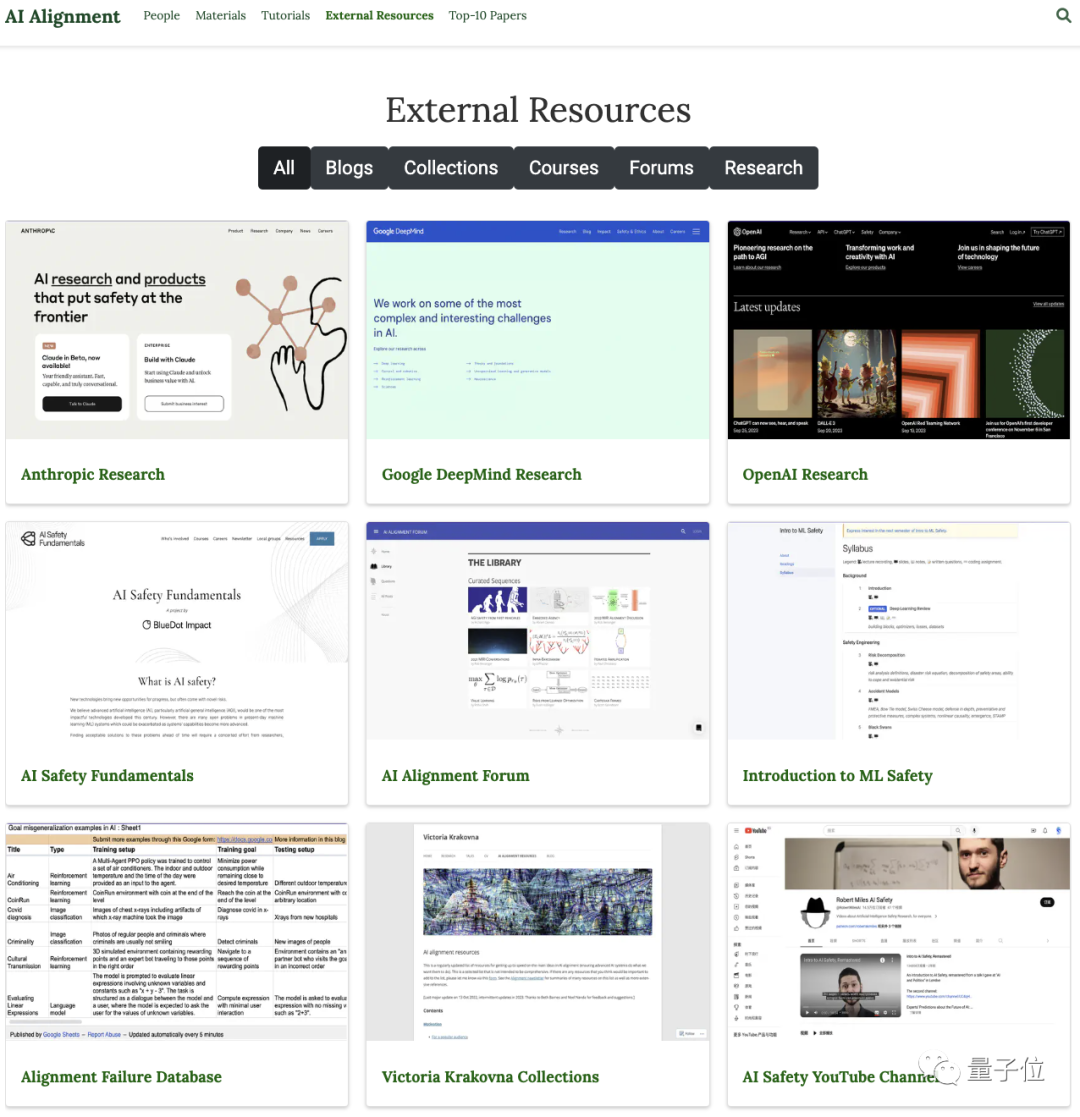
△网站对有关AI对齐的个人研究、课程、博客等学习资源进行了收集与归纳
持续更新与维护:
网站将面向AI对齐社区长期开放讨论,持续性地维护与更新相关领域的调研内容,以期推动AI对齐领域的更广泛更深入研究。
其中包括一份定期邮件发出的Newsletter(地址见文末),以介绍对齐领域的最新进展和总览。

作者希望有关AI对齐的研究不仅仅局限于一份综述论文,而是成为一个值得所有人关注的研究议题。
因此,作者将积极维护网站这一“在线论文”,持续性地开展AI对齐的调研工作。
论文地址(持续更新):
https://arxiv.org/abs/2310.19852
AI Alignment 纵览网站(持续更新):
https://www.alignmentsurvey.com
Newsletter & Blog(邮件订阅,定期更新):
https://alignmentsurvey.substack.com
— 完 —
- GPT-4.1淘汰了4.5!全系列百万上下文,主打一个性价比2025-04-15
- SOTA自动绑骨开源框架来了!3D版DeepSeek开源月大礼包持续开箱ing2025-04-11
- 语音界Deepseek!百度最新跨模态端到端语音交互,成本最高降90%2025-04-02
- 从DeepSeek崛起到下一个亿级销量市场,这份硬核报告说明白了2025-04-01