OpenAI新模型Q*的三种猜测,奥特曼:推开无知之幕,Ilya:数据限制可以被突破
Ilya:数据限制可以被突破
梦晨 发自 凹非寺
量子位 |公众号QbitAI
OpenAI宫斗大戏刚刚落幕,马上又掀起另一场轩然大波!
路透社曝光,在奥特曼被解雇之前,几位研究人员给董事会写的警告信可能是整个事件导火索:
内部名为Q (发音为Q-Star)*的下一代AI模型,过于强大和先进,可能会威胁人类。
Q*正是由这场风暴的中心人物,首席科学家Ilya Sutskever主导。
人们迅速把奥特曼此前在APEC峰会上的发言联系在了一起:
OpenAI历史上已经有过四次,最近一次就是在过去几周,当我们推开无知之幕并抵达探索发现的前沿时,我就在房间里,这是职业生涯中的最高荣誉。”
Q*可能有以下几个核心特性,被认为是通往AGI或超级智能的关键一步。
- 突破了人类数据的限制,可以自己生产巨量训练数据
- 有自主学习和自我改进的能力
这则消息迅速引发了巨大讨论,马斯克也带着链接来追问。
最新的梗图则是,好像一夜之间,人们都从研究奥特曼和OpenAI董事会的专家,变成了Q*专家。

突破数据限制
根据来自The Information的最新消息,Q*的前身是GPT-Zero,这个项目由Ilya Sutskever发起,名字致敬了DeepMind的Alpha-Zero。
Alpha-Zero无需学习人类棋谱,通过自己跟自己博弈来掌握下围棋。
GPT-Zero让下一代AI模型不用依赖互联网上抓取的文本或图片等真实世界数据,而是使用合成数据训练。
2021年,GPT-Zero正式立项,此后并未有太多直接相关的消息传出。
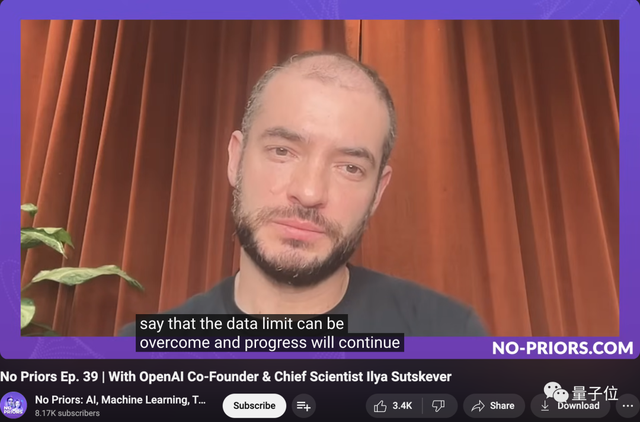
但就在几周前,Ilya在一次访谈中提到:
不谈太多细节,我只想说数据限制是可以被克服的,进步仍将继续。
在GPT-Zero的基础上,由Jakub Pachocki和Szymon Sidor开发出了Q*。
两人都是OpenAI早期成员,也都是第一批宣布要跟着奥特曼去微软的成员。
Jakub Pachocki上个月刚刚晋升研究总监,过去很多突破包括Dota 2项目和GPT-4的预训练,他都是核心贡献者。
Szymon Sidor同样参与过Dota 2项目,个人简介是“正在造AGI,一行代码接一行代码”。

在路透社的消息中,提到给Q*提供庞大的计算资源,能够解决某些数学问题。虽然目前数学能力仅达到小学水平,但让研究者对未来的成功非常乐观。
另外还提到了OpenAI成立了“AI科学家”新团队,由早期的“Code Gen”和“Math Gen”两个团队合并而来,正在探索优化提高AI的推理能力,并最终开展科学探索。
三种猜测
关于Q*到底是什么没有更具体的消息传出,但一些人从名字猜测可能与Q-Learning有关。
Q-Learning可以追溯到1989年,是一种无模型强化学习算法,不需要对环境建模,即使对带有随机因素的转移函数或者奖励函数也无需特别改动就可以适应。
与其他强化学习算法相比,Q-Learning专注于学习每个状态-行动对的价值,以决定哪个动作在长期会带来最大的回报,而不是直接学习行动策略本身。
第二种猜测是与OpenAI在5月发布的通过“过程监督”而不是“结果监督”解决数学问题有关。
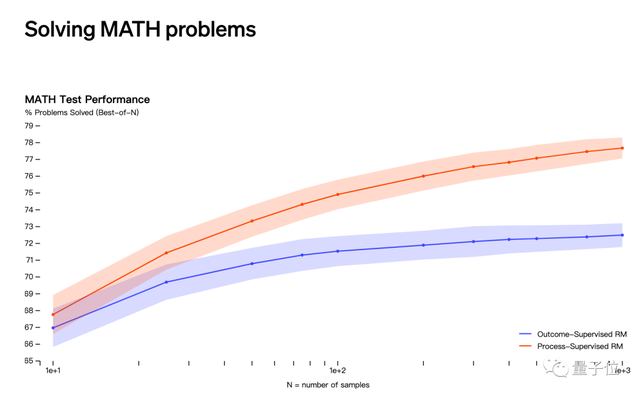
但这一研究成果的贡献列表中并未出现Jakub Pachocki和Szymon Sidor的名字。

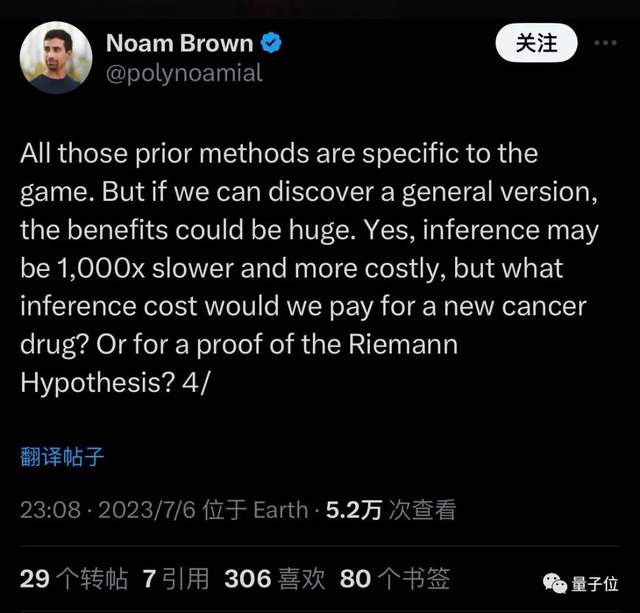
另外有人猜测,7月份加入OpenAI的“德扑AI之父”Noam Brown也可能与这个项目有关。
他在加入时曾表示要把过去只适用于游戏的方法通用化,推理可能会慢1000被成本也更高,但可能发现新药物或证明数学猜想。
符合传言中“需要巨大计算资源”和“能解决一定数学问题”的描述。
虽然更多的都还是猜测,但合成数据和强化学习是否能把AI带到下一个阶段,已经成了业内讨论最多的话题之一。
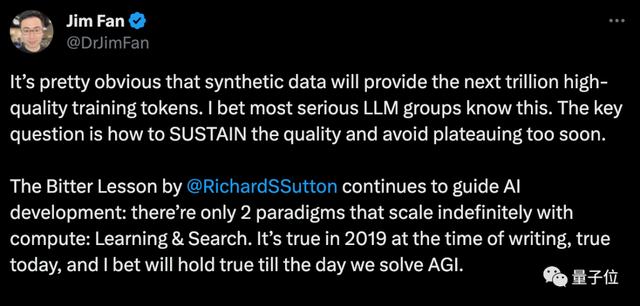
英伟达科学家范麟熙认为,合成数据将提供上万亿高质量的训练token,关键问题是如何保持质量并避免过早陷入瓶颈。
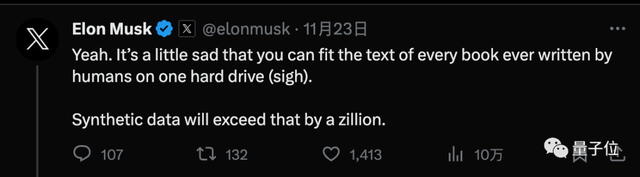
马斯克同意这个看法,并提到人类所写的每一本书只需一个硬盘就能装下,合成数据将远远超出这个规模。
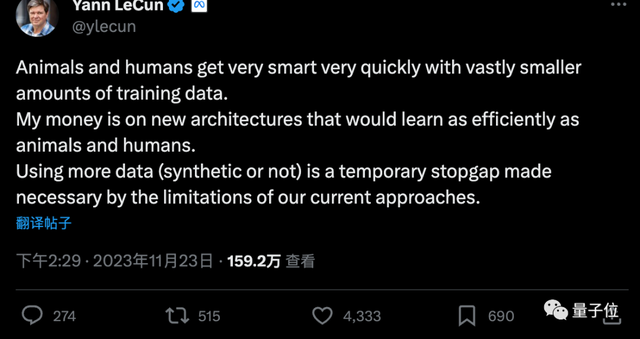
但图灵奖三巨头中的LeCun认为,更多合成数据只是权宜之计,最终还是需要让AI像人类或动物一样只需极少数据就能学习。
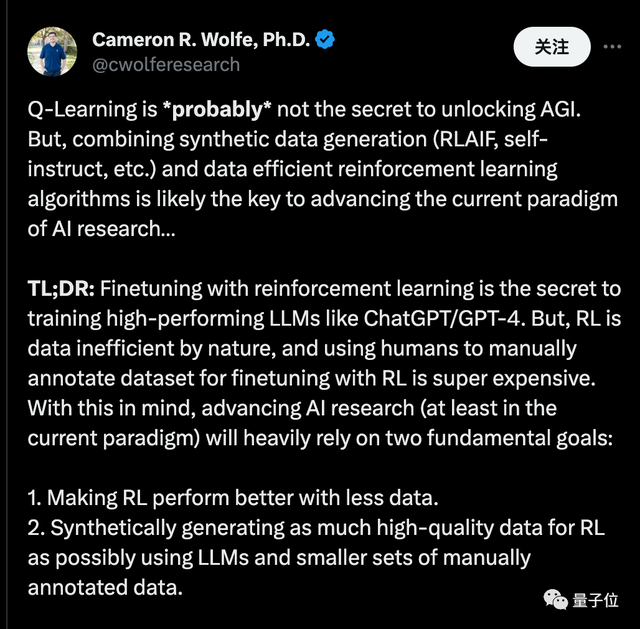
莱斯大学博士Cameron R. Wolfe表示,Q-Learning可能并不是解锁AGI的秘诀。
但将“合成数据”与“数据高效的强化学习算法”相结合,可能正是推进当前人工智能研究范式的关键。
他表示,通过强化学习微调是训练高性能大模型(如ChatGPT/GPT-4)的秘诀。但强化学习本质上数据低效,使用人工手动标注数据集进行强化学习微调非常昂贵。考虑到这一点,推进AI研究(至少在当前范式中)将严重依赖于两个基本目标:
- 让强化学习在更少数据下表现更好。
- 尽可能使用大模型和少量人工标注数据合成生成高质量数据。
……如果我们坚持使用Decoder-only Transformer的预测下一个token范式(即预训练 -> SFT -> RLHF)……这两种方法结合将使每个人都可以使用尖端的训练技术,而不仅仅是拥有大量资金的研究团队!
One More Thing
OpenAI内部目前还没有人对Q*的消息发表回应。
但奥特曼刚刚透露与留在董事会的Quora创始人Adam D’Angelo进行了几个小时的友好谈话。
看来无论Adam D’Angelo是否像大家猜测的那样是这次事件的幕后黑手,现在都达成和解了。
参考链接:
[1]https://www.theinformation.com/articles/openai-made-an-ai-breakthrough-before-altman-firing-stoking-excitement-and-concern
[2]https://www.reuters.com/technology/sam-altmans-ouster-openai-was-precipitated-by-letter-board-about-ai-breakthrough-2023-11-22/
[3]https://www.youtube.com/watch?v=ZFFvqRemDv8
[4]https://www.youtube.com/watch?v=Ft0gTO2K85A
[5]https://x.com/cwolferesearch/status/1727727148859797600
[6]https://twitter.com/DrJimFan/status/1727505774514180188
- DeepSeek新数学模型刷爆记录!7B小模型自主发现671B模型不会的新技能2025-05-01
- 自动化所:基于科学基础大模型的智能科研平台ScienceOne正式发布2025-04-30
- 小扎回应Llama4对比DeepSeek:榜单有缺陷,等推理模型出来再比2025-04-30
- 蚂蚁数科发布智能体开发平台Agentar 金融机构可“零代码”搭建专业智能体应用2025-04-29