阿里云千亿新“模王”打底,5分钟可以开发一款大模型应用了
千亿新“模王”打底
鱼羊 衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
刚刚,阿里云搬出通义大模型“全家桶”炸场了!
就在今天的云栖大会上,不仅通义千问升级至千亿级参数2.0版本,在10个权威评测中,综合性能超越GPT3.5、加速追赶GPT-4,可以通过通义千问APP体验,阿里云还把打造大模型应用的“秘籍”也给公开了。

现在,只需给出问题,基于阿里云通义代码大模型打造的智能编码助手“通义灵码”,就会自动编写代码。
比如,跟它说“帮我用Python写一个飞机游戏”,短短几秒,它就能迅速吐出100+行代码,替换参数直接用:

开发一个大模型应用,最快也只需5分钟就能搞定:
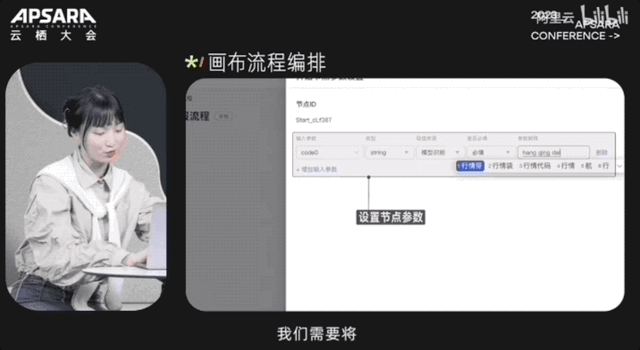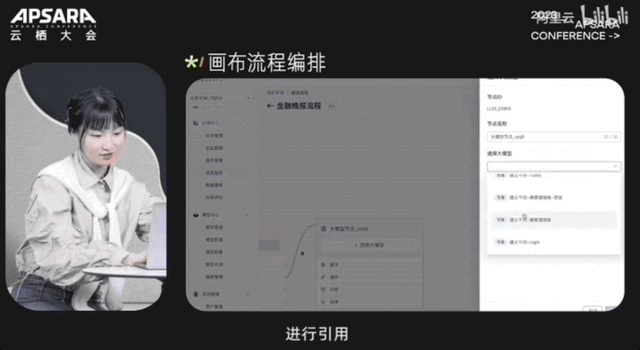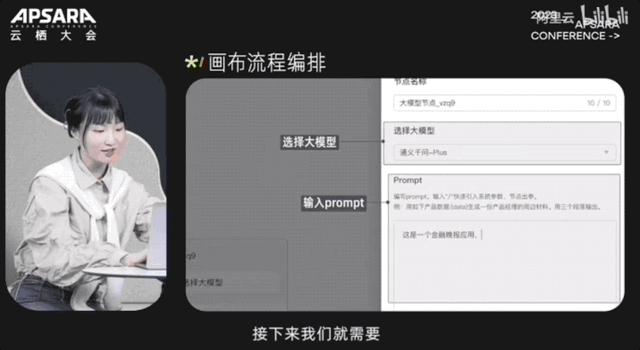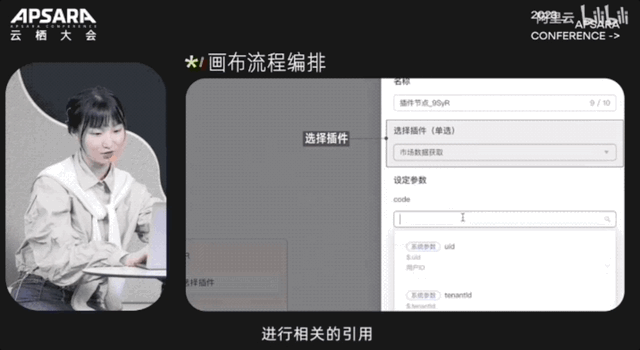
大会现场,阿里云CTO周靖人还透露,这波全家桶背后,阿里云将底层算力到AI平台再到模型服务全栈升级:
已经初步建成AI时代全栈的云计算体系。
目前,中国有一半大模型企业跑在阿里云上,280万AI开发者活跃在阿里云魔搭社区上。
总之,信息量爆炸,咱们一项一项拆解来看。
千亿参数通义千问2.0来了
先来看通义千问2.0。
这是上个月底,阿里云开源通义千问140亿参数版本的Qwen-14B及其对话模型Qwen-14B-Chat后的最新动作。
2.0版本的通义千问有了更庞大的参数,达到千亿级参数规模,也“利用了更先进的对齐技术”,得到的成绩是在10个权威测评中,全面超越GPT-3.5和LLaMA-2,也大有迎头追赶GTP-4的架势。

不仅是官网全面更新,多模态和插件都来了。

而且就在昨天,各个安卓应用市场已经上线了通义千问APP,大家玩儿起来更方便(iOS区小伙伴们再忍忍,听说快了)。
我们也第一时间上手试玩了一番,看看2.0到底有怎样的能力跃升。
我们直接来一道中文十级理解选择题(手动狗头)。
列出6个看起来长得很像的词组,看看通义千问能不能从中找出不同:

一次成功!
通义千问2.0很果断地发现了B选项中两个词组表达的不是同一个意思。
抱着“打起来”的心态,这个问题我们也丢给了ChatGPT(GPT-4)。
GPT-4发现了新的华点,但不知道为什么绕过了B选项,只指出了C选项的问题。

云栖大会现场,阿里云官方提到,“通用数学能力”的进步是通义千问2.0的一大亮点。
那我们也不客气了:
杰森往池塘水面上的扔一块石头。石头在池塘表面反弹三下。如果第二次弹跳是第一次弹跳距离的一半,第三次弹跳是第二次弹跳距离的四分之一,弹跳之间的总距离是65英寸,那么岩石在第一次弹跳时移动了多少英寸?
这道题曾被知乎网友用来遍问中外大模型,结果Claude和NewBing纷纷翻车。
通义千问2.0这次经受住了考验,给出的过程简练,答案也没有问题:

记忆能力与理解能力并驾齐驱,是大模型理解意图的重要“考点”。
Let’s开启一些多轮对话大战,测测通义千问2.0能不能记住对话中的前言后语。

通义千问2.0很快搞出了一个密室探秘剧情,还给自己编出的悬疑故事起了个名字,叫做《密室之谜》。
但这不够——我们提出新的要求,在故事里加个新的角色,女孩肉丝(Rose)。
可以看到,通义千问2.0没有忘记原本的故事设定,还不是直接在段落中强行硬加,而是更改了部分剧情设定,来让肉丝的出现更加自然:

整体来看,在复杂指令理解、文学创作能力、通用数学能力、知识记忆等方面,通义千问2.0确实实力大增,正面对上ChatGPT也并不逊色。
但通义大模型“全家桶”,还不止如此。
与通义千问2.0版本一同登场的,还有8个行业大模型,分别覆盖金融、医疗、法律、编程、个性化创作等等领域。

行业大模型的主要特点,就是更容易在业务场景中被集成。
以通义灵码为例,它就是给阿里云通义大模型投喂海量优秀开源代码数据集和编程教科书后,调教出的智能编码助手。
话不多说,依然是实测走起。
题目是日常运维工作中的一个常见需求:写一个把/var/log中所有的日志文件打包并且上传到oss的Python脚本。
一开始,通义灵码虽然把代码生成出来了,但漏掉了“打包”这个要求。不过在我们指出它的问题之后,它马上把代码修正了。

这波啊,是通义千问2.0打底,一箩筐大模型纷纷在云栖大会上秀出自己的肌肉了。

而在行业大模型发布背后,更关键的是,这次阿里云还把大模型应用落地的“秘籍”也公布了出来。
阿里云大模型应用秘籍公开
现在,越来越多行业观点认为,大模型竞争正在进入下一阶段,主战场正在由模型层转向应用层。
为此,在基础模型之外,阿里云此番另一项值得关注的发布,便是一站式大模型应用开发平台——阿里云百炼。
基于百炼,开发者可在5分钟内开发一款大模型应用,几小时即可“炼”出一个企业专属模型,开发者可把更多精力专注于应用创新。
模型方面,阿里云百炼集成了国内主流优质大模型,既有阿里云自研的通义系列大模型,也有Llama2、Baichuan、ChatGLM、姜子牙等第三方模型。另外,也支持用户上传自行训练的模型。
有意思的是,百炼还提供了一个模型选型的参考榜单,综合能力、推理能力、语言能力等等维度哪家模型更具优势,一下就能整明白。
功能方面,百炼主要面向两重需求:
针对需要训练专属模型的用户,百炼提供从数据处理,到微调训练,再到模型评估部署的一站式服务。支持SFT、LoRA等多种微调方式,所有训练信息均能可视化显示,训练完成后还支持模型一键部署和能力测评。
针对需要开发大模型应用的用户,百炼支持将大模型与实际业务系统结合构建Agent,提供灵活的应用集成能力。比如,插件中心提供了官方系统插件和用户自定义插件,可以根据实际业务需要以插件的形式增强大模型的交互能力。
值得一提的是,在阿里云百炼上,还有一个“应用广场”,提供了丰富的预置应用模板。

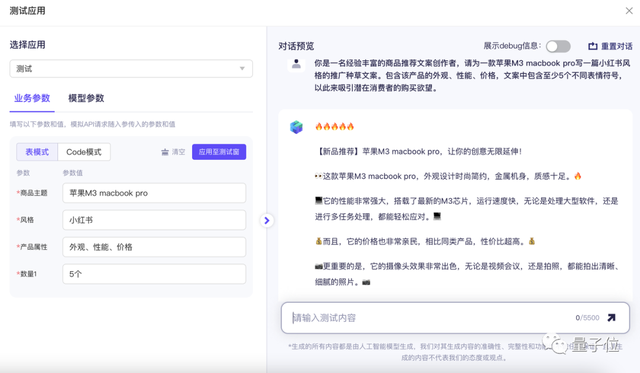
我们试着用“商品推广文案生成”这个模板,简单创建了一个生成小红书种草文案的应用,效果是酱婶的:
另外,在安全方面,阿里云为所有模型提供基础安全套件。即,用户无需任何操作,就能将安全能力集成和部署到自行开发的模型和应用程序中。
目前,央视网、朗新科技、亚信科技等早期用户已在阿里云百炼上开发了专属模型和应用。
朗新科技在云上训练出电力专属大模型,开发“电力账单解读智能助手”“电力行业政策解析/数据分析助手”,为客户接待提效50%、降低投诉70%。
央视网则调教出了一个媒体行业大模型,提供内容创作辅助应用。相比通用模型,编辑人员对于生成内容的满意度和采纳率均有大幅提升。
值得关注的是,在加速应用落地的背后,作为大模型时代的“基础设施”,阿里云人工智能平台PAI也已全面升级:
PAI底层采用HPN 7.0新一代AI集群网络架构,支持高达10万卡量级的集群可扩展规模,超大规模训练线性拓展效率大96%,超过业界水平。在大模型训练任务中,同样的效果可节省超50%算力资源,性能达到全球领先水平。
百川智能、智谱AI、零一万物、昆仑万维、vivo、复旦大学等头部企业及机构目前均在阿里云上训练大模型。

“打造AI时代最开放的大模型平台”
在AI 2.0阶段,大模型步入第二篇章的当下,当主战场从模型层转向应用层,如今的两大行业标杆,有着两种鲜明的风格:
OpenAI靠API,Meta靠开源。
不过无论是何种路线,这两家巨头都在以自己的方式繁荣着生态。

为什么要发展大模型生态?
一方面,没有应用层的发展,基础模型的价值发挥就会严重受限。
另一方面,应用层和模型层的协同发展,生态系统中的各个参与者的竞争,带来的效应能够加速整个大模型圈层的提质与创新。
在云栖大会现场,周靖人也言辞恳切地明确表示,阿里云的目标不是只服务一类客户,阿里云希望在AI时代,为各种各样的企业提供支持,“帮助它们在擅长的领域去创业”。
促进中国AI生态繁荣,是阿里云的首要目标。
提出目标后,要打造AI时代最开放大模型平台的阿里云,具体是这么做的:
8月初,开源通义千问70亿参数模型Qwen-7B;而后,基于Qwen-7B打造的大规模视觉语言模型Qwen-VL登场,支持图像、文本、检测框等多种输入;9月底,新开源的模型参数量来到了140亿,即Qwen-14B。
现在,延续一整套“国内大模型开源全系列”的味儿,阿里云又宣布将开源720亿参数的Qwen-72B。这个版本开源后,它就是目前国内参数量最大的开源模型。

在更深一层的,阿里云攒局的AI模型开源社区魔搭ModelScope,去年刚发布,今年已经是开发者的常驻扎堆地。
啪啪几个数据甩到眼前:一年时间,下载量1亿+、AI开发者280万+,模型总量2300+、……
更值得一提的是,即便已经做大、做强,魔搭社区还是有很值得的羊毛可薅。
魔搭为新用户提供免费GPU算力100小时/人,目前已累计为开发者提供免费GPU算力3000万小时+。

回到当下,大模型彻底改变传统工作流的惊人能力,已然在千行百业中掀起新一轮的智能升级浪潮。
对于当局者,“百模大战”的硝烟逐渐平息,现在已经来到了一个可以更加冷静、客观、理性挑选大模型的阶段。
从大模型的三个要素——算力、模型和应用角度考虑,关键评价指标如今已经在各方动作中逐渐清晰:更具性价比的算力、更强大的模型能力、更繁荣的开发者生态。
以此为标准,以阿里云的整体布局而言,长期来看确实值得期待。
并且有“开源”这个选项加持,意味着在这个新时代里,不用完全把命运交到别人手中。
- 推理大模型1年内就会撞墙,性能无法再扩展几个数量级 | FrontierMath团队最新研究2025-05-13
- 被拒稿11年后翻盘获时间检验奖,DSN作者谢赛宁:拒稿≠学术死刑2025-05-06
- 全员免费!GPT-4.1上线ChatGPT,首波实测:又快又没油腻感2025-05-15
- 黄仁勋放话:中国AI市场3年内达500亿美元!AI救了旧金山,整个世界急于与AI互动2025-05-07