PyTorch官方认可!斯坦福博士新作:长上下文LLM推理速度提8倍
已在64k CodeLlama上通过验证
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
这两天,FlashAttention团队推出了新作:
一种给Transformer架构大模型推理加速的新方法,最高可提速8倍。
该方法尤其造福于长上下文LLM,在64k长度的CodeLlama-34B上通过了验证。

甚至得到了PyTorch官方认可:

如果你之前有所关注,就会记得用FlashAttention给大模型加速效果真的很惊艳。
不过它仅限于训练阶段。
因此,这一新成果一出,就有网友表示:
等推理加速等了好久,终于来了。

据介绍,这个新方法也是在FlashAttention的基础之上衍生而出,主要思想也不复杂:
用并行操作尽快加载Key和Value缓存,然后分别重新缩放再合并结果,最终获得推理速度上的大幅提升。
详细来看。
提速8倍的长上下文推理方法来了
该方法被命名为Flash-Decoding。
背景与动机
根据作者介绍:
LLM的推理(即“解码”)过程是迭代的,即一次生成一个token,组成一个完整句子需要n个token以及n次前向传递。
不过,由于我们可以缓存之前计算出来的token,所以单个生成步骤并不总是依赖于上下文长度。
但有一个操作例外:注意力 (attention),它不能随着上下文长度灵活扩展。
鉴于长上下文已成趋势,比如目前最大的开源LLM已达100k(CodeLlama),我们不得不注意到attention在大模型推理过程中浪费了太多时间,时间就是金钱。

更别提attention在batch size上进行扩展时,即使模型上下文相对较短,它也可能成为性能瓶颈(因为模型要读取的内存量与batch size成比例,而它仅取决于模型其余部分的大小)。
怎么破解?
不可复用的FlashAttention优化
模型在推理也就是解码过程中,为了计算softmax(queries @keys.transpose)@values这两个值,生成的每个新token都需要关注先前的所有token。
团队先前的工作FlashAttention,已经在训练阶段对此操作进行了优化。
当时,FlashAttention解决的主要瓶颈是读写中间结果的内存带宽(例如,Q @ K^T)。
然而,在推理阶段,我们要面对的瓶颈变了,导致FlashAttention所做的优化并不能直接拿过来应用。
具体而言:
在阶段阶段,FlashAttention在batch size和查询长度维度上进行并行化。
在推理阶段,查询长度通常为1,这意味着如果batch size小于GPU上的流式多处理器数量(例如,A100为108),该操作将仅使用GPU的一小部分。
这对于长上下文情况尤甚,因为长上下文需要较小的batch size才能适应GPU内存。
所以,结果就是,当batch size为1时,FlashAttention将只占用不足1%的GPU,非常不划算。

当然,你可能会说,不用FlashAttention也行,用矩阵乘法原语来完注意力操作。
不过,作者指出,这种情况又会完全占用GPU,并启动非常多的写入和读取中间结果的内核,也不是最佳办法。
Flash-Decoding诞生
最终,基于以上考量,作者在FlashAttention的基础上,添加了一个新的并行化纬度:key和value序列长度。
这个方法(即Flash-Decoding)结合上述两种方法的优点:
与FlashAttention一样,它在全局内存中存储的额外数据非常少,但只要上下文长度足够大,即使batch size很小,它也可以充分利用GPU。
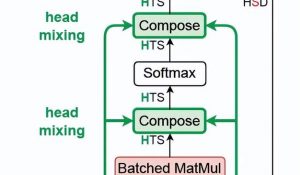
详细来看,Flash-Decoding一共分为三个步骤:
1、先将key和value值分成更小的块。
2、用FlashAttention并行计算每块分割的查询注意力。并为每行和每块分割写入一个额外标量:注意力值的log-sum-exp。
3、最后,通过减少所有分割来计算实际输出,使用log-sum-exp来scale每块分割的贡献。
作者指出,由于attention/softmax可以迭代计算,以上所有操作均可行。
并且在Flash-Decoding中,ttention/softmax既可以在分割块内,也可以跨分割块来执行最终的缩减,只不过后者可缩减的步骤很少。

而在实际操作中,步骤1不涉及任何GPU操作,因为key和value块是完整的张量视图。然后由2个独立的内核分别执行步骤2和3。
最高提速8倍
验证环节,作者在CodeLLaMa-34b(架构与Llama 2相同)上对其解码吞吐量进行了基准测试。
具体以tok/s为单位,测量了512到64k序列长度下的解码速度(上限为从内存中读取整个模型以及KV缓存所需的时间),并和多种计算注意力的方法进行对比,包括:
- Pytorch,使用纯PyTorch原语运行注意力
- FlashAttention v2
- FasterTransformer:使用FasterTransformer注意力内核
最终,Flash-Decoding最高可将长序列解码速度提升8倍,并比其他方法具 有更好的扩展性(受长度影响较小)

此外,作者还在A100上对各种序列长度和batch size的缩放多头注意力进行了微基准测试。
结果显示,当序列长度扩展到64k时,Flash-Decoding实现了几乎恒定的运行时间。

如何使用?
以下是Flash-Decoding的获取途径,戳文末官方博客即可找到地址:
- FlashAttention包,2.2版本及以上
- xFormers包,0.0.22版本及以上
调度程序将根据问题的大小自动使用Flash-Decoding或 FlashAttention方法。
团队介绍
目前Flash-Decoding还没出论文,但作者团队已透露,这次不再是Tri Dao“单打独斗”,不过一作仍然是他。
Tri Dao今年博士毕业于斯坦福,7月份加盟大模型创业公司Together AI担任首席科学家。
明年9月将上任普林斯顿大学助理教授,他是FlashAttention v1和v2的主要作者。

剩下三位作者分别是:
Daniel Haziza,Facebook AI Research研究工程师,主要负责xformers(用于训练加速的开源框架);
Francisco Massa,同Facebook AI Research研究工程师, 主要从事PyTorch相关工作;
Grigory Sizov,Meta机器学习工程师,主要工作是优化GPU上的LLM推理和其他AI工作负载,为PyTorch生态做出过贡献。
官方博客:
https://princeton-nlp.github.io/flash-decoding/
参考链接:
https://twitter.com/tri_dao/status/1712904220519944411?s=20
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10