SuperCLUE中文大模型评测:商汤商量揽总榜、AI智能体两项第一
近日,中文通用大模型综合性评测基准SuperCLUE发布9月总排行榜和各个分类任务榜单,商汤商量SenseChat 3.0 位列中文大模型总榜排名第一。
近日,中文通用大模型综合性评测基准SuperCLUE发布9月总排行榜和各个分类任务榜单,商汤商量SenseChat 3.0 位列中文大模型总榜排名第一。在新增的AI Agent(AI智能体)子榜中,SenseChat 3.0 同样排名第一,领先所有国内中文大模型以及GPT-3.5 和 Claude 2,表现仅次于GPT-4,展示了商汤在大模型领域创新发展及释放生产力的优势,以及在探索AGI道路上的积累与潜力。

注:国外代表性模型(GPT4.0/Claude2/gpt-3.5)不参与排名。
SuperCLUE是中文通用大模型的综合性评测基准,旨在对大模型在各个能力维度上的表现进行全方位的评估,是国内最具专业性和代表性的中文大模型评测基准之一。此次评测选取了目前国内外最具代表性的20个通用大语言模型。
商量总榜第一,客观题成绩超GPT-3.5
9月最新发布的SuperCLUE总排行榜和各个分类任务榜单,主要聚焦于大模型的四个能力象限,语言理解与生成,包括语言理解与抽取、上下文对、生成与创作、角色扮演;专业技能与知识,包括知识与百科、计算、代码、逻辑与推理;Agent智能体,包括工具使用、任务规划;安全性,包括系统安全、指令攻击,总共12项基础能力。
在总排行榜中,商汤科技商量SenseChat 3.0以总分62.75分位列第一,其中在OPT客观题部分,商汤SenseChat 3.0得分还超过了GPT-3.5,展示了在中文大模型方面极强的综合竞争力。
商汤商量SenseChat于2023年4月正式推出,是国内最早的基于千亿参数大语言模型之一,并不断迭代更新。其背后依托的是商汤AI大装置SenseCore,目前上线GPU数量约30,000块,算力规模提升至6 ExaFLOPS,有效支持语言大模型的训练、升级迭代和服务。
推动AI智能体发展,加速迈向AGI
随着大模型发展,“聊天”已远远不能满足人们的要求,能够准确使用工具成为解放大模型生产力的关键。SuperCLUE新增的AI Agent(AI智能体)子榜,是业界首个AI Agent榜单,它重点评估了AI Agent在“工具使用”和“任务规划”两个关键能力上的表现。评测显示商汤商量SenseChat 3.0具备作为人类超级助手的潜力,可以根据人类需求自主完成任务,进而充分释放大模型的生产力,使其在 AI Agent 榜单上表现仅次于GPT-4,全面领先其余参评大模型。

目前全球领先的AI 智能体,几乎都以领先大模型GPT-4为核心驱动,它们借助强大的工具使用能力等,可将复杂问题拆解成可实现的子任务、类人的自然语言交互等能力。商量SenseChat 3.0作为领先的中文大模型,通过使用代码解释器、API调用和搜索三类常用工具来解决复杂任务,灵活搭建AI智能体应用,支撑企业的生产力革新。
目前,商量SenseChat已经在金融、手机、医疗、汽车、地产、能源、传媒、工业制造等众多垂直行业与超过500家客户建立了深度合作。作为具备强大工具使用能力的大模型,商量SenseChat的持续快速提升,为商汤发展更强大的、能够像人类一样进行交互的AI智能体,以及面向AGI道路的探索,都将提供重要的基础和支撑。
- 阶跃星辰推出开源 SOTA 图像编辑模型,一个月连发三款多模态模型2025-04-27
- 清华系智谱×生数达成战略合作,专注大模型联合创新2025-04-27
- 夸克AI超级框上新“拍照问夸克” 加码多模态能力2025-04-27
- 一季度超百万辆!比亚迪凭实力书写行业 “霸榜” 传奇2025-04-27

相关阅读
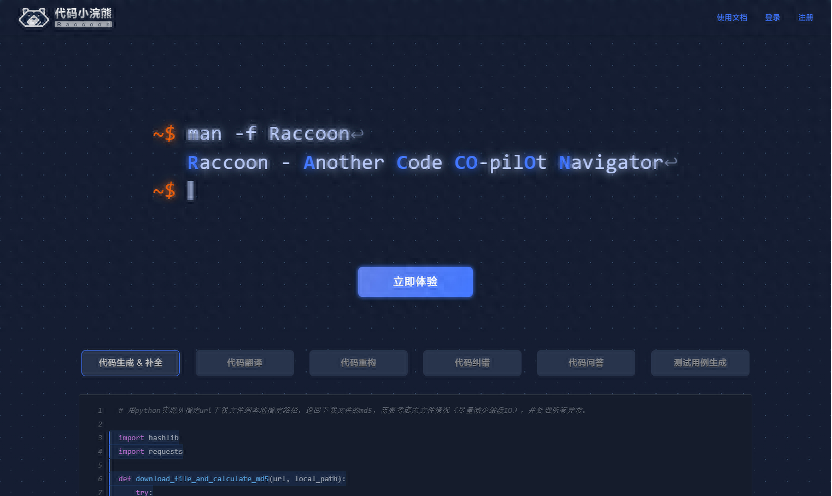
代码小浣熊Raccoon公测,商汤大语言模型加持,编程效率提升超50%
它支持Python、Java、JavaScript、C++、Go、SQL等30+主流编程语言和VS Code、IntelliJ IDEA等主流IDE。实际应用中,可帮助开发者提升编程效率超50%。