
陈丹琦团队新作:5%成本拿下SOTA,“羊驼剪毛”大法火了
比从头训练划算得多
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
只用3%的计算量、5%的成本取得SOTA,统治了1B-3B规模的开源大模型。
这一成果来自普林斯顿陈丹琦团队,名为LLM-Shearing大模型剪枝法。

以羊驼LLaMA 2 7B为基础,通过定向结构化剪枝得到1.3B和3B剪枝后的Sheared-LLama模型。

分别在下游任务评估上超越之前的同等规模模型。

一作夏梦舟表示,“比从头开始预训练划算很多”。

论文中也给出了剪枝后的Sheared-LLaMA输出示例,表示尽管规模只有1.3B和2.7B,也已经能生成连贯且内容丰富的回复。
相同的“扮演一个半导体行业分析师”任务,2.7B版本的回答结构上还要更清晰一些。

团队表示虽然目前只用Llama 2 7B版做了剪枝实验,但该方法可以扩展到其他模型架构,也能扩展到任意规模。
另外还有一个好处,剪枝后可自行选用优质的数据集继续预训练。

有开发者表示,6个月前还几乎所有人都认为65B以下的模型没有任何实际用处。
照这样下去,我敢打赌1B-3B模型也能产生巨大价值,如果不是现在,也是不久以后。

把剪枝当做约束优化
LLM-Shearing,具体来说是一种定向结构化剪枝,将一个大模型剪枝到指定的目标结构。
之前的剪枝方法可能会导致模型性能下降,因为会删除一些结构,影响表达能力。
新方法将剪枝看成一种约束优化问题,学习剪枝掩码矩阵来搜索与指定结构匹配的子网络,同时以最大化性能为目标。

接下来对剪枝过的模型进行继续预训练,在一定程度上恢复剪枝造成的性能损失。
在这个阶段,团队发现剪枝过的模型与从头训练的模型对不同数据集的损失下降速率不一样,产生数据使用效率低下的问题。
为此团队提出了动态批量加载(Dynamic Batch Loading),根据模型在不同域数据上的损失下降速率动态调整每个域的数据所占比例,提高数据使用效率。

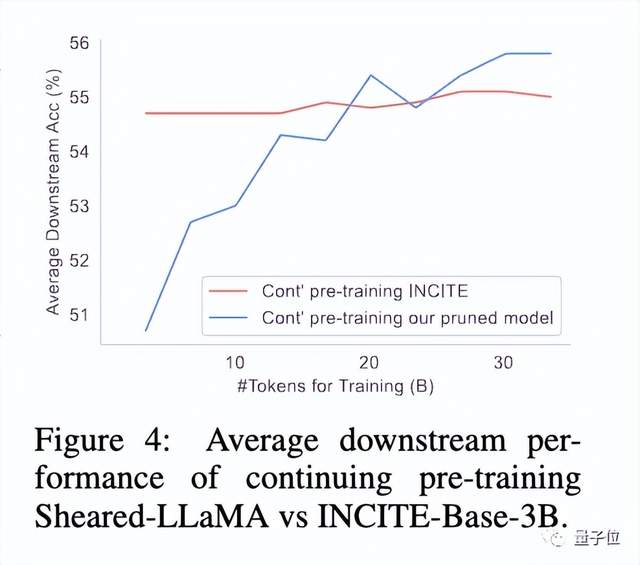
实验发现,虽然剪枝模型与从头训练的同等规模模型相比,虽然一开始表现差得多,但继续预训练可以迅速提高,最终超越。
这表明从强大的基础模型中剪枝,可以为继续预训练提供更好的初始化条件。
将持续更新,来一个剪一个
论文作者分别为普林斯顿博士生夏梦舟、高天宇,清华Zhiyuan Zeng,普林斯顿助理教授陈丹琦。
夏梦舟,本科毕业于复旦,硕士毕业于CMU。
高天宇,本科毕业于清华,是2019年清华特奖得主。
两人都是陈丹琦的学生,陈丹琦现在为普林斯顿助理教授,普林斯顿 NLP小组的共同领导者。
最近在个人主页中,陈丹琦更新了她的研究方向。
“这些日子主要被开发大模型吸引”,正在研究的主题包括:
- 检索如何在下一代模型中发挥重要作用,提高真实性、适应性、可解释性和可信度。
- 大模型的低成本训练和部署,改进训练方法、数据管理、模型压缩和下游任务适应优化。
- 还对真正增进对当前大模型功能和局限性理解的工作感兴趣,无论在经验上还是理论上。

目前Sheared-Llama已在Hugging Face上提供。

团队表示,开源库还会保持更新。
更多大模型发布时,来一个剪一个,持续发布高性能的小模型。

One More Thing
不得不说,现在大模型实在是太卷了。
一作Mengzhou Xia刚刚发布一条更正,表示写论文时还是SOTA,论文写好就已经被最新的Stable-LM-3B超越了。

论文地址:
https://arxiv.org/abs/2310.06694
Hugging Face:
https://huggingface.co/princeton-nlp
项目主页:
https://xiamengzhou.github.io/sheared-llama/
- 3D高斯泼溅算法大漏洞:数据投毒让GPU显存暴涨70GB,甚至服务器宕机2025-04-22
- PPIO姚欣:让免费成为可能,AI时代开启“提速降费”|中国AIGC产业峰会2025-04-22
- o3/o4-mini幻觉暴增2-3倍!OpenAI官方承认暂无法解释原因2025-04-21
- 手机实现GPT级智能,比MoE更极致的稀疏技术:省内存效果不减|对话面壁&清华肖朝军2025-04-12











