扒一扒腾讯混元大模型“老底”
腾讯大模型憋了这么久,原来是在整这个
鱼羊 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
腾讯自研混元通用大模型,终于正式在腾讯全球数字生态大会上亮相。
模型亮相的同时,腾讯还宣布几大腾讯业务就已经直接用上了:腾讯文档、腾讯会议、腾讯广告等均已接入。
举个,在接入智能助手的腾讯文档里,现在只需打字输入需求,AI就能自动写出函数,完成数据分析。

不得不说,鹅厂混元大模型这一波“淡定上分”,确实是给外界带来了一些小小的震撼。
毕竟通用大模型虽好,真正要落地应用,尤其是用到行业生产当中,却也不是简简单单。即使是OpenAI,从ChatGPT到ChatGPT企业版,也需历经大半年的测试、迭代。
那么,问题来了:腾讯是如何做到大模型一亮相,就“行业开箱即用”的?
会上,腾讯集团副总裁、云与智慧产业事业群COO、腾讯云总裁邱跃鹏,把调教腾讯大模型的“底层秘密”透了出来。

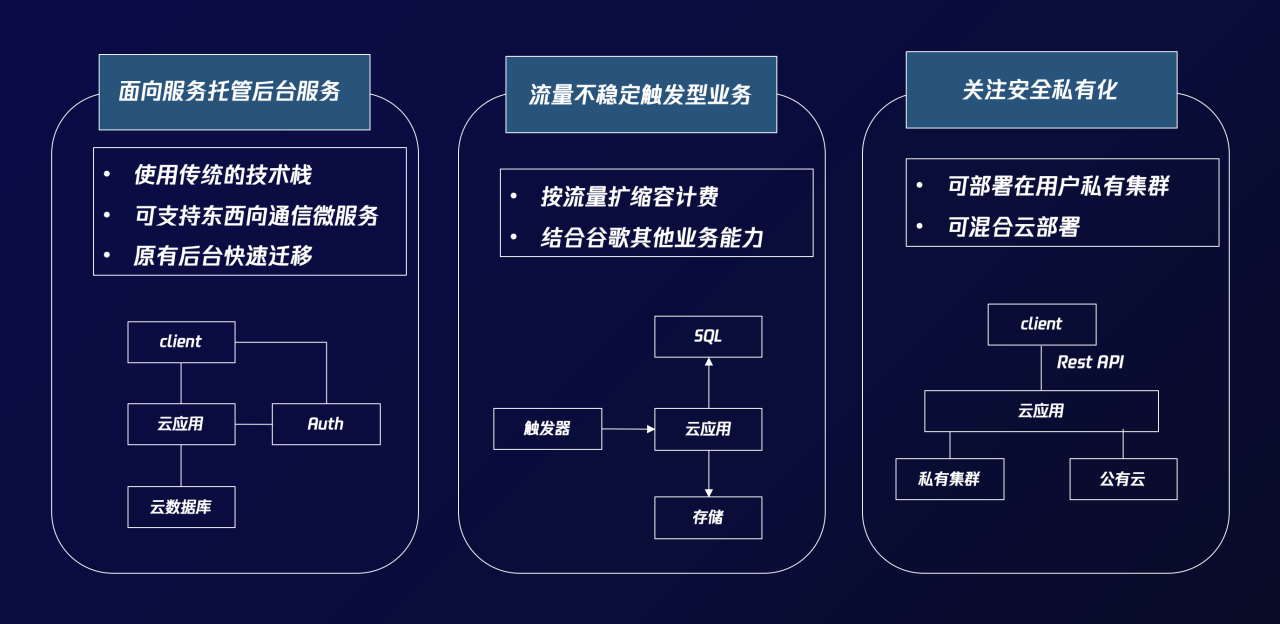
通用大模型落地行业的“三道关”
大模型从想法到实际落地,至少面临“三道关”:高质量数据,训练迭代模型所需算力,内容安全合规性。
首先是算力问题,无论是定期迭代、重新训练还是推理,大模型所需算力都比普通计算的稳定性要求更高、需求量更大。
这并非几百张卡就能解决的事情。
对于动辄成千上万亿参数的大模型而言,需要的往往是高密度GPU算力,以提供更高的并行计算性能。
在持续不断的训练过程中,一旦GPU出现故障导致训练中断,而之前没有“设好存档点”(做好checkpoint)、模型权重参数写入读取过慢的话,耗时就会成倍增加。
因此,在单纯的GPU数量基础上,同样不可忽视的还有工程实践能力,如何确保训练过程的稳定性、中断训练时的回滚能力、并最大程度上降低训练成本,同样是训练大模型无法忽视的一环。

其次是数据问题,要想实现通用大模型的高“智商”,高质量的数据不可或缺。
通用数据,是确保大模型“智商在线”的基础,来源于网上各种公开网站和开源数据集。
但不仅整理数据、确保多样性和准确性(尤其是中文数据)难度不小,加上需要定期更新,迭代起来又非常复杂。
行业数据,是确保大模型“业务水平在线”的知识库,通常为行业公司所有,例如法律行业所具备的的大量历史案件信息、以及工程领域具备的大量专家经验、行业实验数据等,这些数据同样需要清洗去重后才能使用。
像腾讯混元大模型,光是预训练用到的数据就达到2万亿tokens,从整理到清洗每一步都需要大量的时间和技术成本,维护起来更是十分复杂。

最后是安全可用性,对于企业而言,从训练到使用的输入输出阶段,都存在安全可用的问题。
训练阶段,如何确保将行业数据用于训练的同时,又不会泄露企业自身的敏感数据;
交互阶段,除了输入模型过程中,不希望提示词被记录以外,还需要考虑行业大模型输出的数据是否合乎规范、不会生成错误甚至违法信息。
这里面涉及到的安全可控合规的内容审核、大模型“围栏”等技术,同样需要大量的行业经验积累和技术搭建。

然而,腾讯的通用大模型不仅跨过了这三道关,而且已经接入不少自家和行业应用中,给大模型落地“打了个样”。
像是代码辅助领域,腾讯云的AI代码助手接入混元大模型后,在代码补全场景中,代码生成率直接提升到30%,程序员采用的比率也达到30%。
换言之,相比重复编写某些代码,现在30%的工作都能交给大模型干了。

又像是线上会议领域,混元大模型还支持腾讯会议APP打造AI小助手,一键就能总结会议的纲要、实时更新当前会议话题,并在会议前后对需要掌握的内容进行总结,堪称“打工人摸鱼神器”。

配合3D会议、音视频处理能力,即使实时使用大模型也能很好地hold住会议流畅度,不会出现使用后体验反而降低的问题。
同时,腾讯还宣布,腾讯混元大模型将通过腾讯云正式对外开放,既可以调用混元大模型的API,也可以基于它做模型精调。
这些将大模型“开箱可用”、快速落地行业的案例,腾讯云究竟是怎么实现的?
腾讯云的大模型“底座”长啥样?
答案或许能从腾讯云为大模型搭建的两层“底座”中找到。
无论是“基础层”的算力、数据、安全性能力,还是“行业层”快速落地应用、模型精调能力,腾讯云都已经迭代出了一套内部经验公式,并将它们转变为可用的工具。
先来看看“基础层”的三大技术。
数据上,基于大模型落地积累的数据清洗、存储和检索能力,腾讯云打造了云原生的数据湖仓和向量数据库。
其中,数据湖仓用于存储、处理各种类型和格式的原始数据,能将原始数据与经过清洗和转换的数据存储在同一个环境中并进行处理;向量数据库则相当于提供了一个高效的“查询接口”。
针对模型迭代过程中遇到的数据清洗问题,基于数据湖仓和向量数据库技术,已经能做到每秒写入百万级数据,清洗时吞吐能力达到Tbps。
基于这套方案,在大模型训练时,数据清洗性能提升超过40%,数据处理运营成本整体降低50%;
在大模型推理阶段,向量数据库不仅能提供行业知识快速查找,日均处理向量检索千亿次。

算力上,通过对计算、网络和存储的升级,腾讯云做出了一套专门面向大模型训练的新一代HCC高性能计算集群,不仅算力性能相比之前提升3倍,互联带宽更是达到3.2Tbps。
其中,腾讯云在计算方面自研了星星海服务器,将GPU服务器故障率降低超过50%,避免大模型训练过程中出bug带来的成本成倍增加;
网络方面则基于星脉自研网络,做到支持超过10万张卡并行计算;
存储方面进一步提升了数据吞吐量,已经能做到在60秒内写入3TB数据,便于在GPU等计算卡发生故障时,快速写入保存和读出模型参数,提升训练效率。
这也是腾讯云将大模型的迭代周期不断提速的“核心秘诀”。
大模型创业公司如百川智能、MiniMax等,都已经用上腾讯云的这套解决方案。
安全上,腾讯云在输入和输出上进行了“双重技术防护”。
先是针对大模型输入,腾讯云将玄武实验室打造的一套隐私安全解决方案用到大模型中,用户可以在端侧部署使用,确保和大模型交互时,输入的提示词等敏感数据不被记录;
同时,针对大模型训练过程,腾讯云还将多年积累的内容安全能力完善成了一套工具,确保大模型“吐出”的内容是安全、可控、合规的。

不仅是降低模型整体训练成本的“基础层”,腾讯云还将精调参数设计和各类开源大模型集成到一整套“行业层”工具上。
这个工具,就是腾讯云TI平台。腾讯云TI平台提供做大模型过程中的精调、部署等全栈式工具,用户只需少量算力+领域专业数据,就能快速提升特定任务效果,更快更高效地构建出行业大模型。
用户在TI平台上可以基于混元大模型打造行业专属模型,也可以调用Llama 2、Falcon、Dolly、Vicuna、Bloom、Alpaca等20多个业界当前主流的大模型。而且,调用这些大模型也不需要复杂的调试过程,甚至可以在腾讯云平台上一键调用测试效果。
可以说,相比于开放Chat,先“卷大模型”的思路,腾讯云的考量,从一开始就有点不太一样——
直接比拼大模型业务“倍增器”的能力,建立起让大模型在更快在行业中落地的“底座”。
腾讯这么干,是不是悟到了什么?
大模型时代的云,竞速门槛变了
这一切,还要从大模型给云计算行业带来的冲击说起。
云计算作为一个自大模型诞生始,就与其紧密关联的行业,在浪潮涌起的最初时刻,就被预言“规则重写”。
在过去几个月,我们也看到MaaS(模型即服务)作为云厂商新的竞技场,已然成为云产品架构中不可或缺的一环。
就在这一轮新的竞逐中,场上玩家如腾讯,逐渐摸清了水面之下的暗流。
首先,云是大模型的最佳载体,尤其是在大模型越来越成熟,开始走向应用落地的阶段,云计算底座的重要性愈发凸显,正式进入关键的竞争阶段。
因为大模型的训练和推理,涉及到的不仅仅是算力,更涉及到稳定的GPU千卡、万卡并行计算,存储方面快速的写入和读出,以及高性能网络、数据清洗、安全等等工程化能力。
当大模型走向大规模应用阶段,开始跟各行各业产生更深入的融合,一方面,重复造轮子并不现实,越来越多的企业需要低门槛接入、使用大模型的平台。
另一方面,正如马化腾此前在财报电话会中所说:
越想越觉得这(大模型)是几百年不遇的、工业革命一样的机遇,但做它的确需要很多积累。
对于工业革命来讲,早一个月把电灯泡拿出来在长的时间跨度上来看是不那么重要。关键还是要把底层的算法、算力和数据扎扎实实做好。
这其中的“很多积累”,除了大模型技术本身,云计算技术也是不可或缺的一部分。
以腾讯云为例,能在过去几个月中,迅速组织起从算力集群,到数据处理引擎,再到保障模型安全、支持模型训练和精调的工具链等全套大模型辅助能力,绝非偶然突击可得:
腾讯新一代HCC高性能计算集群中用到的星脉高性能计算网络,背后已历经三代技术演进。
腾讯云向量数据库,则早在2019年就已在内部进行孵化。其向量化能力在2021年曾登顶MS MARCO榜单第一,相关成果已发表在NLP顶会ACL上。
……

其次,对于云计算本身而言,也需要顺应大模型给各行各业带来的创新潮流。
直观的一个体现是,大模型将重新定义、甚至重构云上工具。云厂商需要提供智能化水平更高、更便捷易用的云产品,来适应新技术冲击下企业用户降本增效的新需求。
关键问题在于,作为一个明确以需求驱动的名词,“产品”从诞生之初就应当有其明确的落地场景所在,而不能是手握锤子,看什么都是钉子。
相比一个仅展示了chat功能的“半成品”,腾讯一直在将场景需求融入进大模型中,力图让它从诞生之初就直接落地可用。
正因如此,在发布前腾讯才会将大模型提前接入自家各种APP中,通过用户的反馈找到最直接的需求场景,再据此将功能落地。
邱跃鹏指出,“大模型进一步提升了云产品的效能”。
目前,包括腾讯云AI代码助手、腾讯会议AI小助手在内的产品,都已经用大模型能力,实现了不少用户的“AI设想”,完成了显著的效率提升和体验优化。

△腾讯会议AI总结会议要点
而无论是云计算基础设施对于大模型应用落地的支撑,还是大模型给云计算带来变革,最终都指向一点:
大模型时代的云,竞速规则已经改变。
甚至随着技术的发展、应用的深入,仅有算力已经够不到准入门槛,从网络到存储,从底层计算到上层应用,对云计算基础设施更全面、更综合的考量正在拉开序幕。
所以大模型如何变革云计算游戏规则,云计算又如何反作用于大模型的下一步发展,腾讯已经给出了思考和实践。
大模型的发展,最后还是要看背后的云计算广度和厚度。大模型决定了智能应用和服务的能力,云计算决定了大模型的能力。
云计算是底层基础,大模型是上层建筑,AIGC应用都是这个基础和上层建筑上的砖瓦生态。
— 完 —
- 粉笔CTO:大模型打破教育「不可能三角」,因材施教真正成为可能|中国AIGC产业峰会2025-04-18
- GPT-4.1淘汰了4.5!全系列百万上下文,主打一个性价比2025-04-15
- SOTA自动绑骨开源框架来了!3D版DeepSeek开源月大礼包持续开箱ing2025-04-11
- 语音界Deepseek!百度最新跨模态端到端语音交互,成本最高降90%2025-04-02