苹果芯跑大模型不用降计算精度,投机采样杀疯了,GPT-4也在用
生成结果不变的情况下获得2-3倍的推理加速
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
专攻代码的Code Llama一出,大家伙都盼着谁来后续量化瘦身一下,好在本地也能运行。
果然是llama.cpp作者Georgi Gerganov出手了,但他这回不按套路出牌:
不量化,就用FP16精度也让34B的Code LLama跑在苹果电脑上,推理速度超过每秒20个token。

原本需要4个高端GPU才能搞定的活现在用只有800GB/s带宽的M2 Ultra就够了,代码写起来嗖嗖快。
老哥随后公布了秘诀,答案很简单,就是投机采样(speculative sampling/decoding)。

此举引来众多大佬围观。
OpenAI创始成员Andrej Karpathy评价这是一种非常出色的推理时优化,并给出了更多技术解读。
英伟达科学家范麟熙也认为,这是每个大模型从业者都应该熟悉的技巧。

GPT-4也在用的方法
其实不光想在本地跑大模型的人在用投机采样,谷歌OpenAI这样的超级巨头也在用。
根据之前泄露的资料,GPT-4就用了这个方法来降低推理成本,不然根本承受不起这么烧钱。

而最新爆料表示谷歌DeepMind联手开发的下一代大模型Gemini很可能也会用。
虽然OpenAI的具体方法都保密,但谷歌团队已经把论文发出来了,并且入选ICML 2023 Oral。

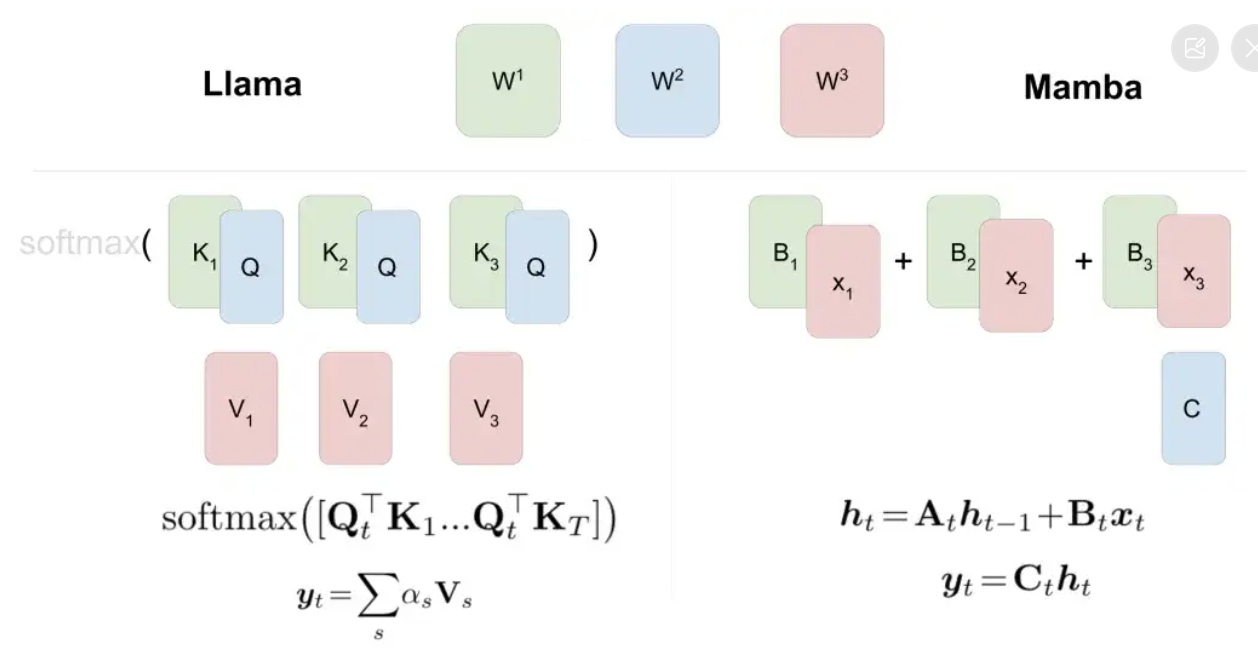
方法很简单,先训练一个与大模型近似、更便宜的小模型,让小模型先生成K个token,然后让大模型去做评判。
大模型接受的部分就可以直接用,大模型不接受的部分再由大模型修改。
在原始论文中使用T5-XXL模型演示,在生成结果不变的情况下获得了2-3倍的推理加速。

Andjrey Karpathy把这个方法比喻成“先让小模型打草稿”。
他解释这个方法有效的关键之处在于,给大模型一次输入一个token和一次输入一批token,预测下一个token所需时间是差不多的。
但每一个token都依赖前一个token,所以正常情况无法一次对多个token进行采样。
小模型虽然能力较差,但实际生成一个句子时有很多部分是非常简单的,小模型也能胜任,只有遇到困难的部分再让大模型上就好了。
原论文认为,这样做无需改变大模型的结构,也无需重新训练,就可以直接加速已有的现成模型。
对于不会降低精度这一点,在论文附录部分也给出了数学论证。

了解了原理,再来看Georgi Gerganov这次的具体设置。
他使用4bit量化的7B模型作为“草稿”模型,每秒约能生成80个token。
而FP16精度的34B模型单独使用每秒只能生成10个token。
使用投机采样方法后获得了2倍的加速,与原论文数据相符。

他额外表示,速度可能会根据生成的内容而有所不同,但在代码生成上非常有效,草稿模型能猜对大多数token。

最后,他还建议Meta以后在发布模型时直接把小的草稿模型附带上吧,受到大伙好评。

作者已创业
作者Georgi Gerganov,今年三月LlaMA刚出一代的时候就移植到了C++上,开源项目llama.cpp获星已接近4万。

最开始他搞这个只是当成一个业余兴趣,但因为反响热烈,6月份他直接宣布创业。
新公司ggml.ai,主打llama.cpp背后的C语言机器学习框架,致力于在边缘设备上运行AI。

创业时获得来自GitHub前CEONat Friedman、Y Combinator合伙人Daniel Gross的种子前投资。
LlaMA2发布后他也很活跃,最狠的一次直接把大模型塞进了浏览器里。

谷歌投机采样论文:
https://arxiv.org/abs/2211.17192
参考链接:
[1]https://x.com/ggerganov/status/1697262700165013689
[2]https://x.com/karpathy/status/1697318534555336961
- 扩散模型还原被遮挡物体,几张稀疏照片也能”脑补”完整重建交互式3D场景|CVPR’252025-04-23
- 3D高斯泼溅算法大漏洞:数据投毒让GPU显存暴涨70GB,甚至服务器宕机2025-04-22
- PPIO姚欣:让免费成为可能,AI时代开启“提速降费”|中国AIGC产业峰会2025-04-22
- o3/o4-mini幻觉暴增2-3倍!OpenAI官方承认暂无法解释原因2025-04-21