商汤AI Agent把打工玩明白了
把工具按顺序摆好都是小case
西风 发自 凹非寺
量子位 | 公众号 QbitAI
家人们,商汤国产大模型也能把工具用明白了!
处理任务时,把要用的工具按顺序一一摆好都是小case。
还能把任务拆成子任务,知道每个子任务要用啥工具。
你没听错,为探究LLM的任务规划和工具使用能力,商汤最近为基于LLM的AI智能体量身打造了一个框架。
结果发现AI处理任务时,引入统一工具-子任务生成策略,性能还能再次得到显著提高。
网友直接被惊掉下巴:
自然语言处理领域振奋人心的进展!大语言模型正在彻底改变现实世界的应用。

为AI智能体量身定制一个框架
此前在自然语言处理领域,人们在看AI解决复杂任务时更多关注任务理解,而缺乏对工具使用和任务规划能力的研究。
这不,为了弥补这一缺陷,商汤的研究人员提出了一种针对基于LLM的AI智能体的任务规划和工具使用方法,并设计了两种不同类型的智能体来执行推理过程。

具体来说,研究人员设计了一个包含六个组件的AI智能体框架。
六个组件分别是:任务指令(Task Instruction)、设计提示(Designed Prompt)、大语言模型(LLM)、工具集(Tool Set)、中间输出(Intermediate Output)和最终答案(Final Answer)。
其中,任务指令是智能体的显式输入,可以来自系统的人类用户;设计提示是一种额外的输入形式,用于引导基于LLM的AI智能体生成适当的输出。

△框架演示
要知道,要想增强或取代实际应用中的人工决策,除了任务规划和使用工具的能力,AI智能体通常还需要感知能力、学习/反思/记忆能力、总结能力。
在这里研究人员总结了包括思维链、向量数据库等方法,来解决这一问题:
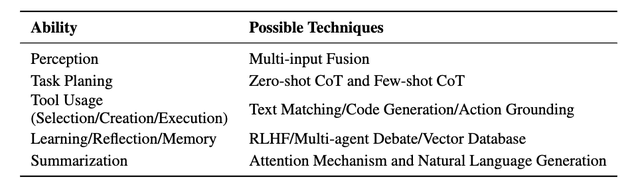
但实际上,众多能力中任务计划和工具使用(简称TPTU)才是核心能力。
所以,研究人员专注于这两个关键能力,设计了两种不同类型的AI智能体:
一步智能体和顺序智能体。

△一步智能体和顺序智能体的工作流程,用于评估LLM的任务规划和工具使用能力。
其中,一步智能体(TPTU-OA)可以从全局角度解释原始问题,充分利用模型的整体理解能力,“一次到位”映射出所有子任务的规划步骤。
而顺序智能体(TPTU-SA),侧重处理当前的子任务,完成后再请求下一个子任务。可以使模型保持清晰和集中式的关注,允许连续的反馈和进步。
这两种智能体分别评估LLM的整体规划与逐步推理的能力,可以从不同侧面考察LLM处理复杂任务的效果。
下一步,研究人员使用不同的LLM实例化了这个框架,并在典型任务上评估了其任务规划和工具使用能力。
一起康康效果如何。
AI用工具竟然如此顺溜
先来看研究人员准备的工具,足足有12种: SQL生成器、Python生成器、天气查询工具、图像生成器、文本提取器、翻译器、必应搜索器、Shell生成器、Java生成器、Wikipedia搜索器、办公软件、电影播放器。
重点评估SQL生成器和Python生成器两种:
- SQL生成器:给定一个输入问题和一个数据库,创建一个语法正确的SQLite查询语句。
- Python生成器:给定一个输入问题和一些信息,生成一个语法正确的Python代码。
测试数据集,则来源于事先准备的120个问题-答案对。
被评估的LLM包括ChatGPT、Claude、上海人工智能实验室和商汤联合研发的InternLM等:

接下来就是正式评估环节。
任务规划能力评估
在一步智能体中,研究人员设计了特定的提示,首先评估了基于LLM的AI智能体的工具使用顺序规划能力。
在这个提示中,智能体被要求从预定义的工具集中选择工具,并严格遵守给定的格式,理解演示以从中学习。研究人员通过将这些提示输入到评估中,得到了工具规划的准确率。

结果表明,Ziya和ChatGLM模型在生成正确格式的列表方面存在困难。其它模型主要在生成正确顺序的工具或偶尔遗漏必要工具方面存在挑战。总体而言,解析列表格式的问题通常可以忽略不计。
接着,他们评估智能体不仅能够规划工具的顺序,还能够规划相应的子任务描述的能力。
研究人员设计提示,要求在生成工具顺序后,对每个工具生成对应的子任务描述。
结果各个LLM的正确率显著下降,ChatGPT从100%下降到55%,Claude从100%下降到15%,InternLM超过Claude,仅次于ChatGPT。
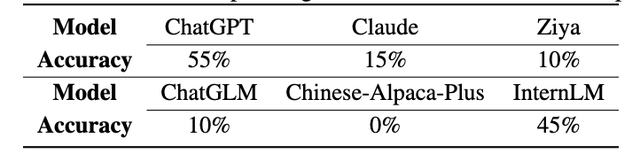
研究人员认为整体生成工具序列和子任务描述虽有效,但存在难以跟踪调试错误、工具子任务匹配问题等困难。
为改进这一问题,研究人员进行了专门的规划评估,要求智能体在复杂问题拆解中生成多个形式为{工具:子任务描述}的键值对序列。

结果各LLM正确率显著提高,ChatGPT从55%上升到75%,Claude从15%上升到90%。
研究人员表示这是因为工具和子任务统一生成,确保了二者的匹配,避免了独立生成的问题。
为了进一步评估,他们扩展了工具集,添加了其他无关的工具,结果稳定,说明提示设计有效,LLM能识别相关工具。
而在顺序智能体中,研究人员设计了可以递归生成工具-子任务对的提示。

各LLM正确率与一步智能体相比普遍提高,ChatGPT从75%上升到80%,Claude从90%上升到100%,InternLM也有65%。
工具使用能力评估
在工具使用能力评估方面,研究人员首先评估了单一工具使用对SQL生成和数学代码生成的有效性。
SQL生成综合评估结果如下:

不同LLM的SQL生成能力截然不同,部分模型适合逐步指导。
数学代码生成方面,国产大模型InternLM表现最优:

然后研究人员还进一步评估了一步智能体、顺序智能体多工具的使用。
由于基于用户界面的LLM缺乏调用外部工具的能力,所以这部分仅使用四个基于API的LLM来做评估:ChatGPT,Ziya,Chinese-Alpaca和InternLM

在一步智能体评估中,ChatGPT得分50%,明显优于其它模型,InternLM为15%,而Ziya和China-Alpaca都没有成功完成任何任务。
在顺序智能体评估中,ChatGPT保持了领先地位,性能略有提高,达到55%。InternLM也表现出更好的表现,得分为20%。
总之,基于LLM的AI智能体在任务规划和工具使用方面具备一定的能力,并且通过改进生成策略可以显著提高智能体的性能。
论文传送门:https://arxiv.org/abs/2308.03427
- 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品2025-04-14
- 4090玩转大场景几何重建,RGB渲染和几何精度达SOTA|上海AI Lab&西工大新研究2025-04-13
- 阿里云造“Agent工厂”,百炼MCP服务上线,无需代码5分钟建Agent2025-04-09
- 又一上海人形机器人加入开源!全套图纸+代码,来自傅利叶2025-04-11