
王小川月更大模型:530亿参数但闭源,现场拷问室温超导相关问题
下月将开放API等模型组件
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
王小川旗下百川智能,又双叒叕发布大模型了。
Baichuan-53B,530亿参数,是百川智能首个闭源大模型。
这是一个主要面向公众(To C),展示百川大模型能力的版本,为To B的进一步落地和商业化做准备。
该版本的API能力会在下个月对外开放,并将陆续开放其它模型组件。
在媒体沟通会现场,王小川亲自现场演示了Baichuan-53B的能力:

他表示当年在搜狗的时候,也想过让搜索变成问答,或让输入法根据联想续写句子段落,但仍然无法达到现在这样的效果。
演示后连说“好像没有翻车”的王小川,对大模型创业带给自己的成就感直言不讳:
大模型创业,比当年做搜索引擎(带给我的)成就感更大。
他还透露,目前百川113名员工,其中约30%是搜狗昔年的成员。

Baichuan-53B是该公司发布的第三个大模型。
官宣成立以来,百川智能保持每月对外发布一次的速度:
6月初发布中英文语言模型Baichuan-7B,7月初发布通用大语言模型Baichuan-13B,同时宣布清华北大已经率先内测。
最新进展是,在腾讯云和阿里云提供算力的情况下,已经有浪潮、火山引擎等150+公司部署使用了Baichuan大模型。
第三次迭代,王小川率队发布的这一版530亿参数大模型,带来了哪些新东西?
Baichuan-53B
演示现场,王小川让Baichuan-53B完成了一些知识问答和文本创作类的任务,比如完成一个电动汽车品牌调研PPT、给一家公司起名等。
不过他也笑着表示:“这些能力其实都不新鲜了,就看各家完成的品质怎么样。”
(话虽这么讲,此处还是附上一些测试图)
关于热点时事常温超导的提问:
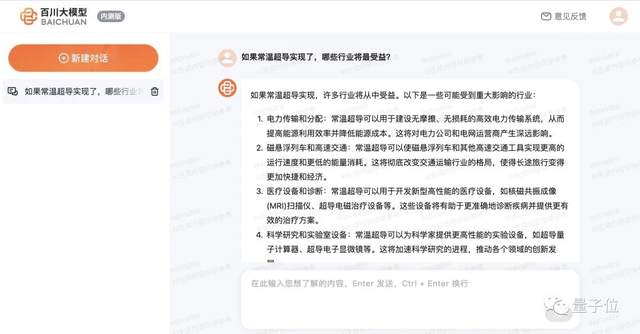
关于博大精深中文的benchmark测试:

以及一份短视频镜头脚本策划与写作:

据介绍,Baichuan-53B主要针对搜索增强、预训练数据和对齐能力3个方面进行了更新:
53B对“搜索增强”的追求,多次在媒体沟通会上被王小川提到。
以此为目的,Baichuan-53B还完成了智能化搜索词生成、高质量搜索结果筛选和回答结果的搜索增强等优化工作。
为了弥补大模型本身的幻觉问题,同时让大模型的回答更有时效性、更精确,Baichuan-53B的搜索增强系统融合了多个模块,包括指令意图理解、智能搜索和结果增强等关键组件。
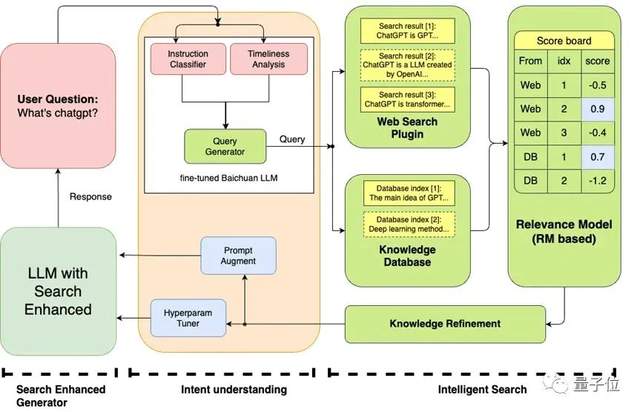
这一综合体系通过深入理解用户指令,精确驱动查询词的搜索,并结合大语言模型技术来优化模型结果生成的可靠性。
王小川现场解释道,今后在这一层面,会尝试让搜索引擎和大模型在模型层面就有更多的交互。
尤其对于重视To B条线的百川智能来说,采取的方法是接入企业私有的向量数据库。
而现在发布的53B,接入了某家搜索引擎的能力。

体验了一把,是可以问出最新相关消息的。

在预训练数据方面,为了追求更丰富、质量更好的数据,百川智能建立了一套包括低质、优质、类别在内的系统的数据质量体系、设计了一个多粒度的大规模聚类系统,并且开发了一种细粒度的自动化匹配算法。
在与人类意图对齐方面,Baichuan-53B进行了多目标优化、多RM融合、数据多样性/质量识别、SFT训练加速、课程学习策略等工作。
需要注意的是,Baichuan-53B除了参数量对外公布,中英文语料规模、上下文窗口长度均未对外透露。
百川智能第一个闭源模型
连续发布两个开源模型后,百川智能的第三个模型选择了闭源路线。
为什么会转向不开源模型?王小川进行了回答。
他给出的解释是,开源和闭源之间,并不像安卓和iOS之间必须二选一,“我们认为这不是竞争关系,而是不同产品间的互补关系”。
从百川智能定位的To B落地的视角来看,出于“未来80%的企业都需要使用开源模型”的认知,开源、闭源在百川的技术路线里,都需要实现。
开源模型,百川能让用户使用模型时更轻便、更灵活;
但是从13B提升到53B,模型参数的增加,提高了企业推理部署时的难度。
于是53B走闭源路线。如此一来,百川提供的接口更直接、更简单,让有需要的客户更方便地调用。
“大家其实生活中有经验,一个“开箱即用”的精装房,哪怕再像样板间,还是得拆了重新装修。”他继续说道,“也就是说,有能力的人,会在这个基础上自己进行调优。”
王小川给出了一个态度:
开源闭源,我们都会发,但对开发者最大的尊重是给他一个毛坯房,而不是精准房。
而且在开源市场,此前的7B、13B两款大模型,作为后发者(相比于智谱、MiniMax等),百川智能“给中国的大模型商业生态做出了一些贡献”,以至于“LlaMA-2发布的时候大家并没有太受惊吓”。
对齐LlaMA-2的能力,也是百川作为国内大模型创业公司一员,追赶国外大模型能力的“小目标”。
且追赶并不是只盯着LlaMA-2的参数去做文章,更需要是关注背后的开源生态在某些具体场景如何进行强化。
同时,此前发布开源模型,在某种程度上也是百川秀肌肉的一部分。
搜狗旧部占百川人员30%
沟通会上,又一名搜狗旧部以百川智能联合创始人的身份亮相——
陈炜鹏,百川智能联合创始人,主要负责大语言模型技术部分。
此前在搜狗时,陈曾任搜狗搜索研发总经理,负责搜狗通用/垂直搜索和推荐系统的研发工作。
搜狗被腾讯收购后,陈炜鹏加入Soul,担任技术VP,负责算法能力建设,推动内容理解、推荐技术和AIGC技术在社交场景的应用和落地。

此次王小川进行大模型创业,不少都是搜狗老班底。
比如公司创立时就确认入职的前搜狗COO茹立云,以及上月月底官宣加入的洪涛——前搜狗CMO,入职百川智能,负责商业化方面的事务。
现如今,百川智能上下共113个人,其中有搜狗背景的占据其中30%左右(这也一度被投资人质疑,到底为啥要用那么多搜狗的人??)。
王小川说了三个理由:
第一,搜索和输入法用到的NLP等知识和经验,都能完整地适配大模型领域;
第二,之前有过亲密无间的合作,彼此之间更加信任;
第三,创业公司有一定的失败率,但是成功之后,回报会比以前在搜狗高很多——不论是物质,还是精神。
内测申请网址:
https://chat.baichuan-ai.com/home
- 直观即时绘制3D模型,可添加文本提示,VAST又开源了2025-04-21
- LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯2025-04-06
- 超九成年轻人工作学习离不开AI,人均还有1.8个AI朋友丨Soul《2025 Z世代AI使用报告》2025-04-06
- 5.28亿融资砸向杭州具身智能公司,清华叉院机器人天才坐镇2025-03-31




