RLHF缺陷完整揭示!MIT哈佛等32位学者联合发布
报告正文18页
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
MIT哈佛斯坦福等机构在内的32位科学家联合指出:
被视作ChatGPT成功关键的RLHF,存在缺陷,而且分布在各个环节。
他们调查翻阅了250篇相关论文,仅研究正文就长达18页,其中7页描述了具体缺陷。

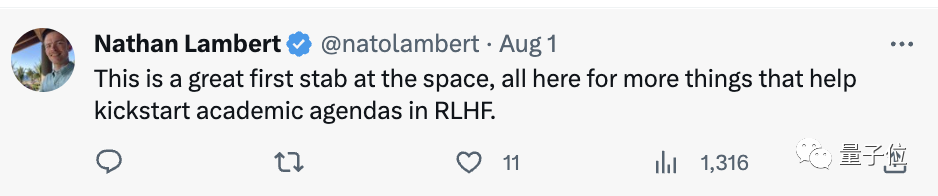
此研究一经发出,就受到大量关注。
有网友表示:这是一次伟大尝试。所有这些都是为了帮助启动 RLHF 的学术议程。
第一作者Casper还给了RLHF一个「新的解释」:
Rehashing Lessons from Historical Failures
从历史的失败中汲取经验

不仅指出问题,还有解决方案
作者在论文中表示,这项研究主要有三项贡献。
第一是指出了RLHF在人类反馈、奖励模型和决策三个主要环节中的缺陷。
第二点则是针对这些问题,提供了具体的解决思路。
第三则是呼吁提高RLHF训练出的模型的透明度,并表示训练信息公开有助于提高企业责任感。
我们先来看看作者在各个环节中都指出了哪些具体缺陷。
人类反馈的局限性
RLHF区别于其他强化学习方式的关键之处就在于人类反馈。
但作者认为,人类反馈很容易存在不准确的情况,因而是缺陷的一大重要来源。

在人类反馈环节中,作者首先提到的是人类会产生误导性评价。
对大模型而言,所涉及的专业领域涵盖了方方面面,没有人能做到样样精通。
因此需要在不同领域选择有代表力的人物,并让他们给出高质量的反馈。
但实际上这项工作是十分困难的。
此外由于人并非完全理性,个别评价者的观点难免带有偏见,甚至可能产生毒害。
除了观念问题引起的「故意」偏差,还有一些偏差是「不小心」的。
由于时间、注意力的不足,人类犯错误的情况是很难避免的
而一些带有迷惑色彩的信息,也可能导致人类被误导。
而一些对于有一定困难的任务,人类甚至难以对其做出评价。

论文介绍,不只是做出评价时会产生偏见,评价收集的过程同样是偏见的一大来源。
收集过程中需要对评价的有用性进行评估,所以评估人员的主观想法同样可能带来影响。
在这个过程当中,还不可避免地存在成本与质量之间的权衡,影响准确程度。
除了反馈的内容,反馈的形式也存在一定的局限性,这也是出于成本的考虑。
奖励模型和策略也需改善
接着,作者又指出,除了人类的反馈,RLHF本身的奖励模型和决策方式也有需要改进之处。
其中奖励函数可能难以准确描述价值判断,单个函数更是无法代表整个人类社会的价值观。
奖励模型还有泛化能力差的问题,存在奖励机制被恶意利用的风险。
此外,奖励模型的质量也难以评估,即使能够实现也需要很高的成本。
因为真实的奖励函数通常是不可知的,只能通过策略优化进行间接评估。

策略方面,论文指出很难高效地对策略进行优化,难以保证策略的鲁棒性。
在策略执行阶段,可能会出现与奖励阶段的差异,此前处理得很好的内容突然出现问题。
而策略阶段可能使用一些预训练模型,这同样可能引入其中所包含的偏见信息。
另外,在对奖励模型和决策方式进行协同训练时,会出现漂移问题,在效率和避免过拟合之间找到平衡点也存在困难。
如何解决
根据论文内容我们可以看到,从人类反馈到RLHF自身的奖励模型和决策方式,都存在不同程度的问题。
那么该如何解决呢?作者为我们提供了一些思路。

比如针对人类反馈的局限性问题,作者的策略是可以引入另一套AI系统或奖励模型,对反馈进行评价。
还有对过程进行监督指导、要求提供更精细化的反馈等措施。
另外两个环节,作者同样给出了解决方案。
对于可以奖励模型,把让AI协助人类反馈这个思路调换一下,让人类直接监督其表现。
而对于决策方式问题,可以在预训练阶段就对模型进行对齐,并在训练中加入指导。
作者还指出,除了RLHF,其他AI领域存在的安全问题同样需要引起重视,并提出了相应的对策。
RLHF is Not All You Need
作者简介
领衔的两位作者分别是MIT CSAIL实验室的Stephen Casper和哈佛大学的Xander Davies。
Casper的主要研究方向是对齐算法,此前曾发表过关于扩散模型评估的论文并获得ICML的Spotlight Paper奖。
Davies的主要研究方向是AI安全,今年有两篇论文被ICML Workshop收录。
其他作者当中,还可以看到不少华人的名字。
论文地址:
https://arxiv.org/pdf/2307.15217.pdf
参考链接:
https://twitter.com/StephenLCasper/status/1686036515653361664
— 完 —
- 文生图进入R1时代:港中文发布T2I-R1,让AI绘画“先推理再下笔”2025-05-14
- Manus终于开放注册!每天能免费玩一次2025-05-13
- 大模型终于通关《宝可梦蓝》!网友:Gemini 2.5 Pro酷爆了2025-05-03
- 10秒生成官网,WeaveFox重塑前端研发生产力 | 蚂蚁徐达峰@中国AIGC产业峰会2025-04-30