一张图转3D质量起飞!GitHub刚建空仓就有300+人赶来标星
分辨率飞升8倍
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
最新“只用一张图转3D”方法火了,高保真那种。

对比之前一众方法,算得上跨越式提升。(新方法在最后一行)

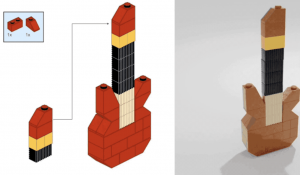
挑出一个结果放大来看,几何结构细节丰富,渲染分辨率也高达1024×1024。

新方法Magic123,来自KAUST、Snap和牛津联合团队,一作为KAUST博士生钱国成。
只需输入单个图像,不光生成高质量3D网格,连有视觉吸引力的纹理也一起打包生成。

甚至论文刚挂在arXiv上,代码还没来得及上传时,就已经有300+人赶来标星码住(顺便催更)。

从粗到精,两阶段方案
以往2D转3D最常见方法就是NeRF。但NeRF不光占显存高,分辨率还低。
论文中指出,即使资源效率更高的Instant-NGP方案在16G显存GPU上也只能达到128×128的分辨率。
为进一步提高3D内容的质量,团队在NeRF之后引入了第二阶段,采用DMTet算法将分辨率提高到1024×1024,并且细化NeRF得出的几何结构和纹理。

对于仅有一张的2D参考图像,首先使用现成的Dense Prediction Transformer模型进行分割,再使用预训练的MiDaS提取深度图,用于后续优化。
然后进入第一步粗阶段,采用Instant-NGP并对其进行优化,快速推理并重建复杂几何,但不需要太高分辨率,点到为止即可。
在第二步精细阶段,在用内存效率高的DMTet方法细化和解耦3D模型。DMTet是一种混合了SDF体素和Mesh网格的表示方法,生成可微分的四面体网格。
并且在两个阶段中都使用Textural inversion来保证生成与输入一致的几何形状和纹理。
团队将输入图像分为常见对象(如玩具熊)、不太常见对象(如两个叠在一起的甜甜圈)、不常见对象(如龙雕像)3种。

发现仅使用2D先验信息可以生成更复杂的3D结构,但与输入图像的一致性不高。
仅使用3D先验信息能产生精确但缺少细节的几何体。
团队建议综合使用2D和3D先验,并经过反复试验,最终找到了二者的平衡点。

2D先验信息使用了Stable Diffusion 1.5,3D先验信息使用了哥伦比亚大学/丰田研究所提出的Zero-1-to-3。

在定性比较中,结合两种先验信息的Magic123方法取得了最好的效果。

在定量比较中,评估了Magic123在NeRF4和RealFusion15数据集上的表现,与之前SOTA方法相比在所有指标上取得Top-1成绩。

那么Magic123方法有没有局限性呢?
也有。
在论文最后,团队指出整个方法都建立在“假设参考图像是正视图”的基础上,输入其他角度的图像会导致生成的几何性质较差。
比如从上方拍摄桌子上的食物,就不适合用这个方法了。
另外由于使用了SDS损失,Magic123倾向于生成过度饱和的纹理。尤其是在精细阶段,更高分辨率会放大这种问题。
项目主页:
https://guochengqian.github.io/project/magic123/
论文:
https://arxiv.org/abs/2303.11328
GitHub:
https://github.com/guochengqian/Magic123
参考链接:
[1]https://twitter.com/_akhaliq/status/1675684794653351936
- DeepSeek新数学模型刷爆记录!7B小模型自主发现671B模型不会的新技能2025-05-01
- 自动化所:基于科学基础大模型的智能科研平台ScienceOne正式发布2025-04-30
- 小扎回应Llama4对比DeepSeek:榜单有缺陷,等推理模型出来再比2025-04-30
- 蚂蚁数科发布智能体开发平台Agentar 金融机构可“零代码”搭建专业智能体应用2025-04-29