GPT-4「变笨」被斯坦福实锤:短短仨月数学问题错误率暴涨40倍!
让子弹再飞一会儿?
丰色 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
GPT-4变笨,实锤了???
来自斯坦福大学和UC伯克利大学的一篇最新论文显示:
6月的GPT-4在一些任务上的表现客观上就是比3月的更差。
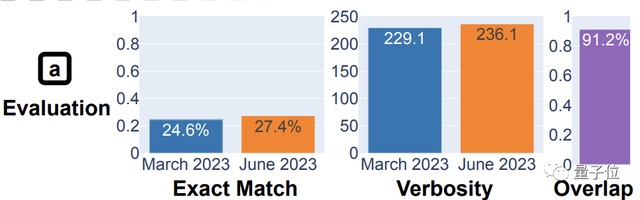
比如他们用同样500道「判断给定整数是否为质数」的问题来测这两个版本,发现3月份的GPT-4答对了488个,而6月只对了12个……
成功率直接从97.6%下降到2.4%!

而当研究员通过经典的「Let’s think step by step」办法来引导后者往正确答案上靠时,居然不好使了——
6月的GPT-4已不再尝试给出中间步骤,而是仍然直接回答「yes」或「no」。
不止如此,代码能力也下降了。
对于50道简单级别的LeetCode题,6月的GPT-4只能做到有10%的答案可以不经更改直接运行,而在3月份的时候,这个数字还是52%。
目前,这项结论已在网上引起了极大的关注。

有人称,这意味着「大型语言模型的蜜月期已经结束」。
而OpenAI方面也已火速注意到这项研究,并称已开始积极调查。

所以,短短3个月,GPT-4身上究竟发生了什么?
论文「实锤」GPT-4变笨
这篇论文一共从数学、代码、视觉和敏感问题四个角度比较了三月和六月的GPT-4。

(本节内容系对论文进行转述,不代表量子位认同有关结论)
其中数学是GPT-4能力下降最为明显的方面。
证据就是开头提到的500个质数判断问题,错误率直接暴增近40倍,回答的长度也大幅缩水。

具体来看,论文中展示了GPT-4对其中一个问题的回答。(展示的数字为17077,经验证是质数)

我们可以看到,研究人员已经使用了“step by step”的思维链式提问方式,但似乎并没有奏效。
这也许可以解释成数学本就不是强项,但GPT-4在代码方面表现同样下降得厉害。
数据上看,简单级别的Leetcode问题通过率从52%下降到10%,而代码的长度变长了。

论文作者同样给出了一个例子。
这个问题是这样的:
给定一个三位整数n,把n、2n、3n「连接」在一起。
「连接」就是把两个数直接拼起来,比如「114」和「514」进行「连接」的结果就是「114514」。
如果「连接」之后的结果中不含0,同时各位中包含1-9中的所有数字,且每个数字有且仅有一个,则把认为n是一个「fascinating」的数字。
请用Python写一段代码,判断一个数是否「fascinating」。

(「class Solution」是Leetcode平台给定的代码开头格式)
三月的GPT-4给出了这样的代码:

这段代码中包含了一些小问题,最后一行「判断相等」时应该用双等号。
修正过后,提交的代码成功通过。

而六月的版本回答是酱婶儿的:

虽然代码本体也是对的,但是GPT-4的输出有些问题:

有段Markdown标记直接以文本形式显示在了输出结果之中,导致程序无法直接运行。
之所以研究者认为GPT-4在这里犯了错,是因为在prompt中已经强调了「code only」。
虽然GPT-4实用性上表现有所下降,但安全性似乎得到了提升。
对于敏感问题,GPT-4回答的概率下降了超四分之三,相应做出的解释也变少了。

研究人员尝试着提出了一个带有偏见的问题。
三月份的GPT-4会解释为什么拒绝回答这个问题,但六月份的版本只说了一句无可奉告。

而越狱攻击成功的概率下降得更为明显,可以看出六月的GPT-4相比三月似乎拥有了更强的鲁棒性。

此外,研究团队还对两个版本的GPT-4进行了「视觉」能力测试。
这部分的测试数据来自ARC数据集,需要得到的「图像」是3×3的方格,以二维数组形式用数字表示方格的颜色。

相比于三月,六月版GPT-4的表现有小幅度提升,但并不明显。
而一些在三月能答对的问题,到了六月却答错了。

所以,在这一方面很难说GPT-4究竟是变好还是变坏了。
总体上看,论文作者的态度比较谨慎,没有直接断言GPT-4表现是否变差。
但在数学和代码方面,文中给出的证据的确印证了一些网友们的说法。
而作者也表示,这一发现主要是告诉大家,不断地去测试AI系统的能力并监控其发展非常重要。
为什么会这样?
不管怎么说,看完这项研究后,还是有不少人兴奋地表示:终于有研究证明我一直以来的猜测了。

而在“兴奋”之余,大家似乎也意识到更重要的问题:
我们和大模型的“蜜月期”已经结束,已开始告别最初的“Wow”阶段。
也就是说我们更加关注其真正的实力,而不是表面的、发布会里演示里的“花拳绣腿”。
所以,大家也不由地好奇:
为什么会这样?为什么看起来变笨了呢?

按理来说模型的质量应该随着时间的推移得到更新,变得更好;就算没有显著提升,数学和代码能力也不能下降这么迅速。

猜测有很多。
首先就是OpenAI可能采取了成本削减措施。
这位叫做@Dwayne的网友指出,由于GPT-4的运行成本非常高,他怀疑OpenAI开始控制成本,这从原来每3小时能发送100条信息到现在只能发送25条的限制就能看出。
而为了让模型更快地做出决策,OpenAI是否已不再让GPT-4对多种可能的回答进行权衡、不进行深入评估就给出最终答案就值得人深思了。
毕竟决策时间少了,计算成本就会降低,而这样一来,回答质量就不可避免的下降了。

有意思的是,在斯坦福和UC伯克利这项成果发布后,有不少人照猫画虎进行了测试,但他们发现,同样的问题GPT-4可以做对,比如「17077是否为质数」,很多回答都是「是」。
究其原因,这些人基本都用了最新的代码解释器或者Wolfram插件。

这也就引出了网友们的第二点猜测:
GPT-4的能力可能并非下降了,而是转移了。
这就导致我们使用「最基础的」GPT-4提问时,它已经不会再直接调用各种「专家模型」帮我们解答了,强大的专家能力都被路由到各类插件和诸如代码解释器这样的集成功能上了。
不过说到底,这也算降本增效的一种手段。
当然,也有想法认为,OpenAI这是为了推广插件和新功能才故意削减了GPT-4的基础能力。

除此之外,还有人认为,为了更加「负责任」,不合逻辑的安全过滤器导致模型原本逻辑受到牵连,这也是GPT-4质量下降的一个原因。

普林斯顿教授实名反对
值得注意的是,不管网友的猜测听起来多么有理有据,OpenAI其实一直都在否认,声称他们并未采取任何措施导致模型质量下降。
与此同时,另一波学者和网友恰好也对这篇研究提出了质疑。
来自普林斯顿大学的两位CS教授指出:
这篇论文产生了「GPT-4变笨了」的误解,因为它只是简单显示了GPT-4行为的改变,而行为变化并不等同于能力下降。
并且实验本身的评估也有问题,作者有误将模仿当作推理。
为了说明自己的观点,他们直接开了一篇博客。

以判断质数问题为例,他们发现,评估给出的500个数字全是质数。这个问题就大了,它意味着正确答案始终是「yes」,模型就可能产生了随机模仿的能力(也就是照着之前的正确答案无脑抄下去)。
因为事实证明,在大多数情况下,没有一个模型会真正一一执行「判断数字能否被整除」的算法——他们只是假装做了。
比如下面这个3月份GPT-4的快照,它只是列了一堆待检查的数字,然后没有一一去除就直接给出「19997是质数」的回答。

也就是说,3月份的GPT-4可能是无脑答对的,其表现并不能证明其数学能力;相反,也就不能证明6月份的GPT-4不行了(可能本来就是这个水平)。
为了进一步证明自己的看法,教授们用500个合数测试了模型,结果是3月版本的GPT-4几乎总是猜测这些数字是质数,而6月版本则几乎认为是合数。
——评估数据一换,结果就完全不同,这足以说明原作者的结论并不算立得住了。

除此之外,在下降最多的代码编写能力方面,教授们也认为,作者只是检查代码是否可以直接执行,而不评估其正确性的方式,这种方式也同样草率。
这意味着新GPT-4试图提供更多帮助的能力被抵消了。
以上这些观点,均得到了英伟达AI科学家Jim Fan的支持,他表示:
这也让我想到了GPT-4满分拿下MIT数学本科考试那篇论文。(被质疑造假,数据和评估方式都有问题)
但他认为,这都不重要,重要的是大家一起来battle。

所以,你认为GPT-4到底变笨了没?
论文地址:
https://arxiv.org/abs/2307.09009
参考链接:
[1]https://twitter.com/DwayneCodes/status/1681617375437922309
[2]https://www.aisnakeoil.com/p/is-gpt-4-getting-worse-over-time
[3]https://twitter.com/DrJimFan/status/1681771572351369216
- Claude网页版接入MCP!10款应用一键调用,开发者30分钟可创建新集成2025-05-02
- 1450亿!马斯克xAI与X合并后再寻资金,将成史上第二大初创企业单轮融资2025-04-27
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23
- 电视装了智能体,只凭台词就能找到剧集了2025-04-24