比Meta「分割一切AI」更全能!港科大版图像分割AI来了:实现更强粒度和语义功能
多个粒度上分割和识别物体的通用图像分割模型
Semantic-SAM团队 投稿
量子位 | 公众号 QbitAI
比Meta“分割一切”的SAM更全能的图像分割AI,来了!
模型名为Semantic-SAM,顾名思义,在完全复现SAM分割效果的基础上,这个AI还具有两大特点:
- 语义感知:模型能够给分割出的实体提供语义标签
- 粒度丰富:模型能够分割从物体到部件的不同粒度级别的实体

用作者自己的话说:
Semantic-SAM,在多个粒度(granularity)上分割(segment)和识别(recognize)物体的通用图像分割模型。
据我们所知,我们的工作是在 SA-1B数据集、通用分割数据集(COCO等)和部件分割数据集(PASCAL Part等)上联合训练模型的首次尝试,并系统研究了在SA-1B 上定义的交互分割任务(promptable segmentation)和其他分割任务(例如,全景分割和部件分割)上多任务联合训练的相互促进作用。
论文来自香港科技大学、微软研究院、IDEA研究院、香港大学、威斯康星大学麦迪逊分校和清华大学等研究单位。
具体详情,一起来看~
- 论文地址:https://arxiv.org/abs/2307.04767
- 代码地址:https://github.com/UX-Decoder/Semantic-SAM
- 在线Demo地址:上述代码仓库的首页
(以下为论文作者投稿)
简介
Semantic-SAM可以完全复现SAM的分割效果并达到更好的粒度和语义功能,是一个强大的vision foundation model。Semantic-SAM 支持广泛的分割任务及其相关应用,包括:
- Generic Segmentation 通用分割(全景/语义/实例分割)
- Part Segmentation 细粒度分割
- Interactive Segmentation with Multi-Granularity Semantics 具有多粒度语义的交互式分割
- Multi-Granularity Image Editing 多粒度图像编辑

1.1 复现SAM
SAM是Semantic-SAM的子任务。我们开源了复现SAM效果的代码,这是开源社区第一份基于DETR结构的SAM复现代码。
1.2 超越SAM
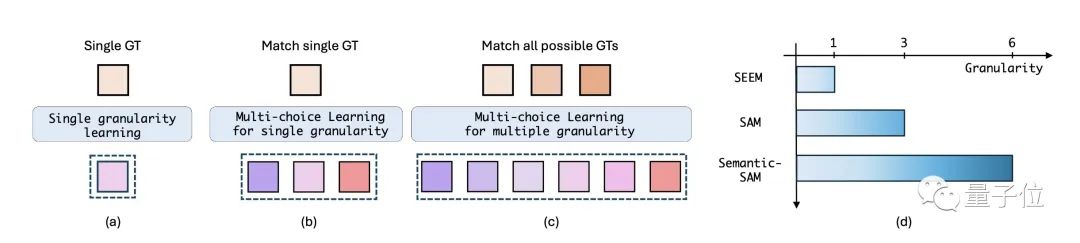
- 粒度丰富性: Semantic-SAM能够产生用户点击所需的所有可能分割粒度(1-6)的高质量实体分割,从而实现更加可控和用户友好的交互式分割。
- 语义感知性。Semantic-SAM使用带有语义标记的数据集和SA-1B数据集联合训练模型,以学习物体(object)级别和细粒度(part)级别的语义信息。
- 多功能。Semantic-SAM 实现了高质量的全景,语义,实例,细粒度分割和交互式分割,验证了SA-1B 和其他分割任务的相互促进作用。
只需单击一下即可输出多达 6 个粒度分割!与 SAM 相比,更可控地匹配用户意图,不用担心鼠标移动很久也找不到想要的分割了~

2. 模型介绍
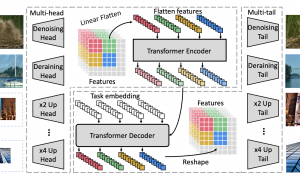
2.1 模型结构
Semantic-SAM的模型结构基于Mask DINO进行开发。Mask DINO是基于DETR框架的统一检测和分割的网络,目前仍然是相同模型size下的SOTA模型。Semantic-SAM的模型结构主要改进在decoder部分,同时支持通用分割和交互式分割。通用分割的实现与Mask DINO相同。交互式分割包括point和box两种形式,其中box到mask不存在匹配的ambiguity,实现方式与通用分割相同,而point到mask的匹配是Semantic-SAM的关键设计。
在Semantic-SAM中,用户的point输入被转换成6个prompt, 每个prompt包含一个可学习的level embedding进行区分。这6个prompt通过decoder产生6个不同粒度的分割结果,以及object和part类别。

2.2 训练
为了学到物体级别(object)和部件级别(part)的语义,Semantic-SAM同时从多个数据集中进行学习,如多粒度数据集(SA-1B),物体级别数据集(如COCO),以及部件级别数据集(如Pascal Part)。

为了从联合数据集中学习语义感知性和粒度丰富性,我们引入以下两种训练方法:
解耦物体分类与部件分类的语义学习:为了学习到可泛化的物体和部件语义,我们采用解耦的物体分类和部件分类,以使得只有object标注的数据也可以学习到一些通用的part语义。例如,head是在几乎所有动物上都通用的part,我们期望模型从有标注的dog head,cat head,sheep head等head中学习到可泛化的lion,tiger,panda等head的识别能力。

Many-to-Many的多粒度学习:对于交互式分割中的point输入,Semantic-SAM利用6个prompt去输出多粒度的分割结果,并用包含该点击的所有标注分割来作为监督。这种从多个分割结果到多个分割标注的Many-to-Many的匹配和监督,使得模型能够达到高质量的多粒度分割效果。
3. 实验
3.1 SA-1B 与通用分割数据集的联合训练
我们发现,联合训练 SA-1B 和通用分割数据集可以提高通用分割性能,如对COCO分割和检测效果有大幅提升。

在训练SA-1B数据的过程中,我们也发现了利用少量SA-1B的数据即可得到很好的效果。

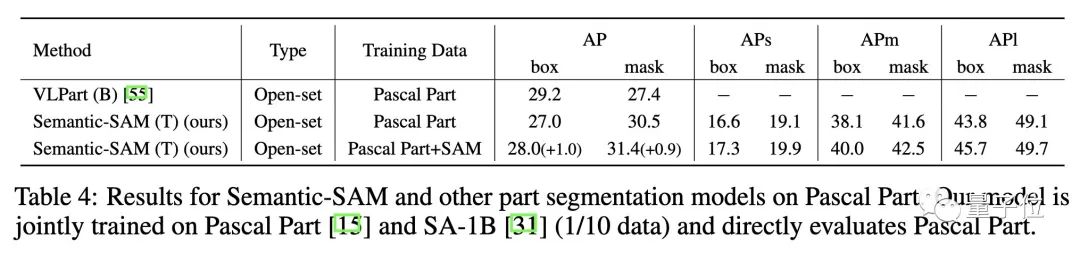
3.2 SA-1B 与细粒度分割数据集的联合训练
同样的,联合训练 SA-1B 和细粒度分割数据集可以提高部件分割性能。
4. 可视化
4.1 Semantic-SAM的prompt从大量数据中学到了固定模式的表征
Semantic-SAM一共有6个可学习的prompt。对于不同图片的点击,观察每个prompt对应的分割结果,可以发现每个prompt的分割都会对应一个固定的粒度。这表明每个prompt学到了一个固定的语义级别,输出更加可控。

4.2 Semantic-SAM与SAM, SA-1B Ground-truth 的比较
每行最左边图像上的红点是用户点击的位置,(a)(b) 分别是Semantic-SAM和 SAM 的分割输出, (c) 是包含用户点击的 Groud-truth 分割。与 SAM 相比,Semantic-SAM具有更好的分割质量和更丰富的粒度,方便用户找到自己需要的分割粒度,可控性更好。

— 完 —
- 从骁龙8至尊版,我看到了AI手机的未来 | 智在终端2024-12-17
- o1被曝“心机深”:逃避监督还会撒谎,骗人能力一骑绝尘2024-12-09
- 低成本机器人“皮肤”登上Nature子刊:实现三维力的自解耦,来自法国国家科学研究中心&香港大学2024-11-23
- OpenAI重夺竞技场第一,但这波靠的是4o2024-11-21
相关阅读