比AlphaFold2快一个数量级!蛋白质通用大模型来了,13个任务取得SOTA丨百图生科&清华
首个千亿参数蛋白质大模型
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
蛋白质领域的“通用大模型”来了!
参数量高达1000亿,在这个领域尚属首次,一出场就在13个任务上达到SOTA——
例如在抗体结构预测任务中,就超越了“老前辈”AlphaFold2。
如果说之前蛋白质AI模型还大多停留在单一类型任务上,现在从蛋白质预测到蛋白质设计,各种细分任务都用一个AI就能完成。
这个蛋白质语言模型由百图生科和清华大学共同开发,取名xTrimoPGLM。

所以,它究竟在哪些任务上取得了SOTA,这个千亿大模型又究竟是如何炼成的?背后的运作原理和实现方式是什么?
未来在整个生命科学领域,是否也会像自然语言这样,出现类似ChatGPT的通用大模型?
百图生科的CTO宋乐博士向我们分享了思考。

蛋白质的“通用大模型”长啥样?
这个名叫xTrimoPGLM的蛋白质语言大模型,“底子”是清华推出的GLM(通用语言模型)算法。
选用这种算法,是因为人类语言和蛋白质之间存在很多相似之处。
和语言任务一样,蛋白质任务也可以被分为理解(预测)和生成(设计)两大类:
生成任务,指根据不同条件设计对应的蛋白质。如给定某个功能标签,要求生成能实现这一功能的蛋白质;或是给一段蛋白质结构,设计一段可折叠成该结构的氨基酸序列等。
理解任务,指预测某种蛋白质的属性。如蛋白质本身是酶,用AI预测它的最优催化温度、催化效率、稳定性等。
但和人类语言一样,在大模型出现前,蛋白质语言模型往往也“只能干好一件事”,同时学多个任务,反而可能把原来的能力给“忘了”。

(毕竟理解类任务通常用的是双向注意力机制,类似完形填空;但生成类任务用的却是单向的,像续写作文一样)
而GLM在框架设计上兼顾了大模型的理解和生成能力,因此也成为团队这次的基础架构“首选项”。
不过,相比自然语言模型,蛋白质在训练数据、任务和框架适用性上又有所不同。
为了更好地将GLM的优势和蛋白质语言特性结合起来,xTrimoPGLM设计了一种新框架,其中增加了MLM(掩码语言模型)部分。
其中,紫色的[MASK]表示MLM,用于提升模型理解能力;绿色的[sMASK]和[gMASK]表示GLM,用于提升模型生成能力。
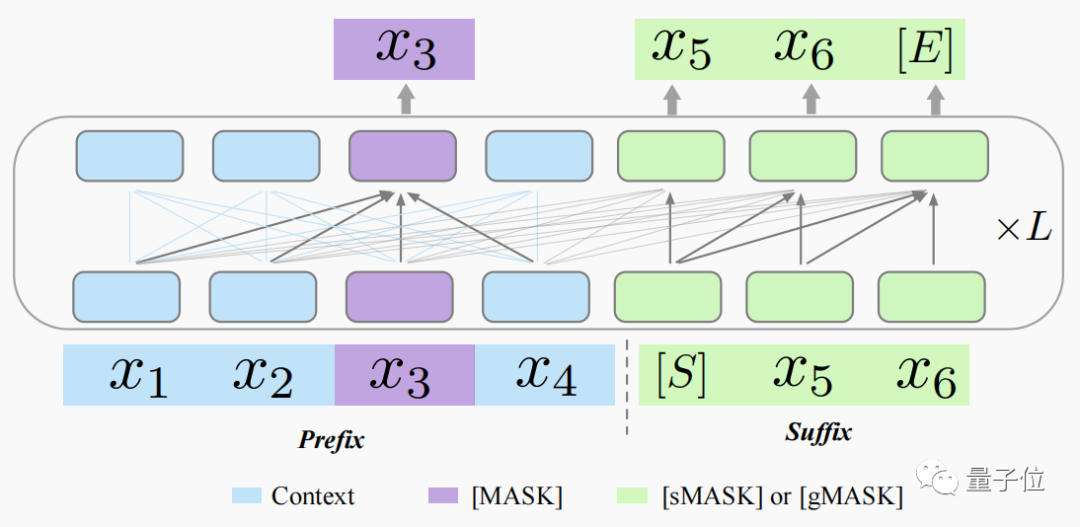
具体到细节上,[sMASK]掩盖序列中间的连续部分,模型预测时不仅要学会预测内容,还需要学会预测长度;[gMASK]掩盖除了上下文之外的其余序列部分,以进一步提升模型的生成能力。
不过,即使是Meta的蛋白质理解模型ESM,参数量也就在150亿级别左右。
为何xTrimoPGLM模型参数量会达到千亿级?
宋乐博士介绍称,这是因为蛋白质的数据比想象中要更大:
目前可用的蛋白质序列已经有几十亿,而这些序列的长度平均又达到几百甚至上千,乘起来就接近自然语言token的数量规模了。
更大的数据量,自然需要更大的模型来“吃”。
在大语言模型已经达到千亿级参数量的情况下,蛋白质语言模型理论上也应达到这一规模,才能实现比Meta的ESM更好的效果。
基于这一理念设计的xTrimoPGLM,确实在理解和生成任务上均取得了不错的效果。
斩下13个SOTA,可直接用于行业
研究人员一共将xTrimoPGLM在15个任务上进行了测试。
事实证明,这个蛋白质语言模型在其中的13个任务上都取得了SOTA。

这些任务从蛋白质结构、可发展性、相互作用到功能分为四大类,具体又包括评估蛋白质特性,如溶解性、对蛋白酶的稳定性、温度敏感性、蛋白质结合亲和力、抗生素抗性等。

以抗体结构预测为例。据宋乐博士介绍,和AlphaFold2相比,xTrimoPGLM不仅效果更好,而且速度快了接近一个数量级。
之所以能做到在模型更大的同时,预测速度还更快了,是因为相比AlphaFold2,xTrimoPGLM“跳了一步”:
AlphaFold2依赖多序列比对进行搜索,但xTrimoPGLM因为已经“学会了蛋白质的语言”,所以直接省去了这个步骤。

在此基础之上,xTrimoPGLM不仅能很好地提供蛋白质序列信息,模型能力也得到了增强。
宋乐博士认为,不止是抗体结构预测,类似思路也能被推广到更通用的蛋白质结构预测上去,这也在团队的下一步计划之内。
不仅如此,团队还计划把模型扩展到RNA、DNA等不同模态的生命科学数据上,甚至是跨细胞、跨组织层面,尝试实现更加通用的生命科学大模型。
当然,目前这一阶段的xTrimoPGLM,就已经能直接提供给行业使用了。
从它能实现的任务来看,已经涵盖了不少蛋白质下游应用的场景,如涉及蛋白质的相关酶的设计,以及医药食品行业的一些消费级蛋白质预测任务,都可以直接用xTrimoPGLM去帮助解决。
据宋乐博士介绍,xTrimoPGLM未来也会接入到百图生科的AI生成蛋白平台AIGP中去,负责如抗体结构预测、亲和力预测和蛋白质相互作用预测等任务。
One More Thing
目前来看,发展“通用大模型”的路径主要有两种。
一种是继续扩大单个模型的参数量,试图达到真正的单个AGI之路;
另一个则是通过多个模型联合的如Mixture of Experts等方式,将负责不同任务类型的大模型之间联合起来,以实现更多功能。
这两条路各有其优缺点所在。如果要想继续发展生命科学领域的“通用大模型”,哪条路径更有可能通往AGI?
宋乐博士认为“都有可能”。
不过就百图生科团队而言,他们仍然采取多个大模型联动的方式,来继续探索通用大模型之路。
论文地址:
https://www.biorxiv.org/content/10.1101/2023.07.05.547496v1
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07