中科院版「分割一切」模型来了,比Meta原版提速50倍 | GitHub 2.4K+星
通用视觉模型,中科院自动化所出品
An. 投稿
量子位 | 公众号 QbitAI
比Meta的「分割一切模型」(SAM)更快的图像分割工具,来了!
最近中科院团队开源了FastSAM模型,能以50倍的速度达到与原始SAM相近的效果,并实现25FPS的实时推理。
该成果在Github已经获得2.4K+次星标,在Twitter、PaperswithCode等平台也受到了广泛关注。

相关论文预印本现已发表。
以下内容由投稿者提供

视觉基础模型 SAM[1]在许多计算机视觉任务中产⽣了重⼤影响。它已经成为图像分割、图像描述和图像编辑等任务的基础。
然⽽,其巨⼤的计算成本阻碍了它在实际场景中的⼴泛应⽤。
最近,中科院⾃动化所提出并开源了⼀种加速替代⽅案 FastSAM。
通过将分割⼀切任务重新划分为全实例分割和提⽰指导选择两个⼦任务,⽤带实例分割分⽀的常规 CNN 检测器以⾼出50倍的运⾏速度实现了与SAM⽅法相当的性能,是⾸个实时分割⼀切的基础模型。

意义与动机
SAM 的出现带动了 “分割⼀切”(Segment Anything)任务的发展。这⼀任务由于其泛化性和可扩展性,有很⼤可能成为未来⼴泛视觉任务的基础。
FastSAM 为该任务提供了⼀套实时解决⽅案,进⼀步推动了分割⼀切模型的实际应⽤和发展。
本⽂将“分割⼀切”任务解耦为全实例分割和提⽰引导选择两阶段,通过引⼊⼈⼯先验结构,在提速 50 倍的情况下实现了与 SAM 相近的表现。
FastSAM 的优秀表现为视觉任务的架构选择提供了新的视角——对于特定任务,专用模型结构或许在计算效率和精确度上仍具有优势。
从模型压缩的⾓度看,FastSAM 也证明了基于大模型产生高质量数据,通过引⼊⼈⼯先验结构大幅降低计算复杂度的路径的可⾏性。
示例
– Web DEMO
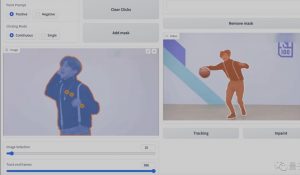
在 HuggingFace 的 Space 中,你可以快速体验 FastSAM 的分割效果。
你可以上传一张自定义的图片,选择模式并设置参数,点击分割按钮,就可以得到一个满意的分割结果。
现在支持一切模式和点模式的交互,其他模式将在未来尝试支持。在 Replicate 上已支持所有模式的在线体验。


– 多种交互⽅式
FastSAM目前共支持三种交互方式。

· 多点交互模式
FastSAM ⽀持多个带有前景/背景标签的点交互模式,可以很好地适应不同场景的应⽤需求。
以缺陷检测场景为例,只需对缺陷部位添加前景点,对正常药丸部分添加背景点,即可准确地检测出物体缺陷。

· 框交互模式
FastSAM 也⽀持框交互模式。也以缺陷检测为例,只需对缺陷⼤致位置进⾏框选,即可准确检测出物体缺陷。

· ⽂本交互模式
FastSAM 也⽀持并开源了⽂本交互模式。通过不同的⽂本提示,FastSAM可以准确分割出不同颜⾊的⼩狗。

工作原理
如下图所示,FastSAM 的网络架构可分为两个阶段:全实例分割和提示引导选择。

在全实例分割阶段,FastSAM 使用卷积神经网络来对图像中的所有对象或区域进行划分。
在提示引导选择阶段,它采用包括点提示、框提示和文本提示的各种提示来选出关注对象。
与基于Transformer的方法不同,FastSAM融合了与视觉分割任务紧密相关的先验知识,例如局部连接和对象分配策略。这使得它以更低地参数量和计算量下更快地收敛。
定性与定量分析
测试结果表明,FastSAM各方面的表现完全不输于Meta的原始版本。
· 速度
从表中可以看出,FastSAM 取得了远超 SAM 的速度表现,在「分割⼀切」模式下,SAM的速度会受到均匀点提⽰数量的影响,⽽ FastSAM 由于结构的特点,运⾏时间不随点提⽰数量的增加⽽增加,这使得它成为「分割⼀切」模式的更好选择。

同时,由于 FastSAM 在结构设计中利⽤了⼈的先验知识,使得它在实时推理的同时也具备了与 SAM 相当的性能。
· 边缘检测
下图展⽰了具有代表性的边缘检测结果。经过定性观察可以看出,尽管FastSAM的参数明显较少(只有68M),但它也能产⽣很⾼质量的边缘检测结果。

从下表可以看出,FastSAM 取得了与 SAM 类似的性能。与 Ground Truth 相⽐,FastSAM和 SAM 都倾向于预测更多的边缘,这种偏差在表中得到了定量的反映。

· 物体候选
从下表可以看出,FastSAM 在 bbox AR@1000 的表现上超过了计算量最⼤的 SAM 模型(SAM-H E64),仅次于在 LVIS 数据集上监督训练的 ViTDet-H[2]。

· 可视化结果
SA-1B 分割结果:下图展⽰了 FastSAM 在 SA-1B 数据集上不同场景和掩码数量时的分割结果。

下游应⽤对⽐:下⾯三张图对⽐了 FastSAM 和 SAM 在异常检测、显著物体分割和建筑物提取三个下游任务的效果,FastSAM 在不同模式下均取得了和 SAM 相当的表现。



参考⽂献
[1] Kirillov A, Mintun E, Ravi N, et al. Segment anything[J]. arXiv preprint arXiv:2304.02643, 2023.
[2] Li J, Yang T, Ji W, et al. Exploring denoised cross-video contrast for weakly-supervised temporal action localization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 19914-19924.
论文地址:
https://arxiv.org/abs/2306.12156
GitHub项目页:
https://github.com/CASIA-IVA-Lab/FastSAM
HuggingFace DEMO:
https://huggingface.co/spaces/An-619/FastSAM
Replicate demo:
https://replicate.com/casia-iva-lab/fastsam
- “史上最快闪存技术”登Nature!复旦新成果突破闪存速度理论极限,每秒执行操作2500000000次2025-04-23
- 挤爆字节服务器的Agent到底啥水平?一手实测来了2025-04-23
- 装满智能体AI的手机,正在呼唤一个“Type-C时刻”2025-04-16
- 最强视觉生成模型获马斯克连夜关注,吉卜力风格转绘不再需要GPT了2025-04-17