国产ChatGPT「套壳」的秘密,现在被找到了
比算力更急需的是高质量数据
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
“套壳ChatGPT!”“套皮Stable Diffusion!”“实则抄袭!”……
外界对国产大模型产生质疑已经不是一次两次了。
业内人士对这个现象的解释是,高质量的中文数据集实在紧缺,训模型时只能让采买的外文标注数据集“当外援”。训练所用的数据集撞车,就会生成相似结果,进而引发乌龙事件。

其余办法中,用现有大模型辅助生成训练数据容易数据清洗不到位,重复利用token会导致过拟合,仅训练稀疏大模型也不是长久之计。
业内渐渐形成共识:
通往AGI的道路,对数据数量和数据质量都将持续提出极高的要求。
时势所需,近2个月来,国内不少团队先后开源了中文数据集,除通用数据集外,针对编程、医疗等垂域也有专门的开源中文数据集发布。
高质量数据集虽有但少
大模型的新突破十分依赖高质量、丰富的数据集。
根据OpenAI 《Scaling Laws for Neural Language Models》提出大模型所遵循的伸缩法则(scaling law)可以看到,独立增加训练数据量,是可以让预训练模型效果变更好的。

这不是OpenAI的一家之言。
DeepMind也在Chinchilla模型论文中指出,之前的大模型多是训练不足的,还提出最优训练公式,已成为业界公认的标准。

△主流大模型,Chinchilla参数最少,但训练最充分
不过,用来训练的主流数据集以英文为主,如Common Crawl、BooksCorpus、WiKipedia、ROOT等,最流行的Common Crawl中文数据只占据4.8%。
中文数据集是什么情况?
公开数据集不是没有——这一点量子位从澜舟科技创始人兼CEO、当今NLP领域成就最高华人之一周明口中得到证实——如命名实体数据集MSRA-NER、Weibo-NER等,以及GitHub上可找到的CMRC2018、CMRC2019、ExpMRC2022等存在,但整体数量和英文数据集相比可谓九牛一毛。
并且,其中部分已经老旧,可能都不知道最新的NLP研究概念(新概念相关研究只以英文形式出现在arXiv上)。
中文高质量数据集虽有但少,使用起来比较麻烦,这就是所有做大模型的团队不得不面对的惨烈现状。此前的清华大学电子系系友论坛上,清华计算机系教授唐杰分享过,千亿模型ChatGLM-130B训练前数据准备时,就曾面临过清洗中文数据后,可用量不到2TB的情况。
解决中文世界缺乏高质量数据集迫在眉睫。
行之有效的解决方法之一,是直接用英文数据集训大模型。
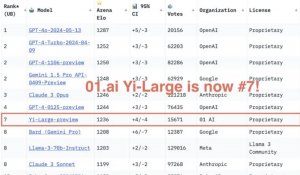
在人类玩家打分的大模型匿名竞技场Chatbot Arena榜单中,GPT-3.5在非英文排行榜位居第二(第一是GPT-4)。要知道,96%的GPT-3.5训练数据都是英文,再刨去其他语种,用来训练的中文数据量少到可以用“千分之n”来计算。

国内top3高校某大模型相关团队在读博士透露,如果采用这种方法,不嫌麻烦的话,甚至可以给模型接一个翻译软件,把所有语言都转换成英语,然后把模型的输出转换为中文,再返回给用户。

然而这样喂养出的大模型始终是英文思维,当遇到成语改写、俗语理解、文章改写这类含有中文语言特色的内容,往往处理不佳,出现翻译错误或潜在文化的偏差。
还有个解决办法就是采集、清洗和标注中文语料,做新的中文高质量数据集,供给给大模型们。
开源数据集众人拾柴
察觉现况后,国内不少大模型团队决定走第二条路,着手利用私有数据库做数据集。
百度有内容生态数据,腾讯有公众号数据,知乎有问答数据,阿里有电商和物流数据。
积累的私有数据不一,就可能在特定场景和领域建立核心优势壁垒,将这些数据严格搜集、整理、筛选、清洗和标注,能保证训出模型的有效性和准确性。
而那些私有数据优势不那么明显大模型团队,开始全网爬数据(可以预见,爬虫数据量会非常大)。

华为为了打造盘古大模型,从互联网爬取了80TB文本,最后清洗为1TB的中文数据集;浪潮源1.0训练采用的中文数据集达5000GB(相比GPT3模型训练数据集为570GB);最近发布的天河天元大模型,也是天津超算中心搜集整理全域网页数据,同时纳入各种开源训练数据和专业领域数据集等的成果。
与此同时,近2个月来,中文数据集出现众人拾柴火焰高的现象——
许多团队陆续发布开源中文数据集,弥补当前中文开源数据集的不足或失衡。
其中部分整理如下:
- CodeGPT:由GPT和GPT生成的与代码相关的对话数据集;背后机构为复旦大学。
- CBook-150k:中文语料图书集合,包含15万本中文图书的下载和抽取方法,涵盖人文、教育、科技、军事、政治等众多领域;背后机构为复旦大学。
- RefGPT:为了避免人工标注的昂贵成本,提出一种自动生成事实型对话的方法,并公开我们的部分数据,包含5万条中文多轮对话;背后是来自上海交大、香港理工大学等机构的NLP从业者。
- COIG:全称“中国通用开放指令数据集”,是更大、更多样化的指令调优语料库,并由人工验证确保了它的质量;背后的联合机构包括北京人工智能研究院、谢菲尔德大学、密歇根大学、达特茅斯学院、浙江大学、北京航空航天大学、卡内基梅隆大学。
- Awesome Chinese Legal Resources:中国法律数据资源,由上海交大收集和整理。
- Huatuo:通过医学知识图谱和GPT3.5 API构建的中文医学指令数据集,在此基础上对LLaMA进行了指令微调,提高了LLaMA在医疗领域的问答效果;项目开源方是哈工大。
- Baize:使用少量“种子问题”,让 ChatGPT 自己跟自己聊天,并自动收集成高质量多轮对话数据集;加州大学圣迭戈分校(UCSD)与中山大学、MSRA合作团队把使用此法收集的数据集开源。

当更多的中文数据集被开源到聚光灯下,行业的态度是欢迎与欣喜。如智谱AI创始人兼CEO张鹏表达出的态度:
中文高质量数据只是被藏在深闺而已,现在大家都意识到这个问题了,自然也会有相应的解决方案,比如数据开源。
总之是在向好的方向发展,不是吗?
值得注意的是,除了预训练数据,目前阶段人类反馈数据同样不可或缺。
现成的例子摆在眼前:
与GPT-3相比,ChatGPT叠加的重要buff就是利用RLHF(人类反馈强化学习),生成用于fine-tuing的高质量标记数据,使得大模型向与人类意图对齐的方向发展。
提供人类反馈最直接的办法,就是告诉AI助手“你的回答不对”,或者直接在AI助手生成的回复旁边点赞或踩一踩。

先用起来就能先收集一波用户反馈,让雪球滚起来,这就是为什么大家都抢着发布大模型的原因之一。
现在,国内的类ChatGPT产品,从百度文心一言、复旦MOSS到智谱ChatGLM,都提供了进行反馈的选项。
但由于在大部分体验用户眼中,这些大模型产品最主要的还是“玩具”属性。
当遇到错误或不满意的回答,会选择直接关掉对话界面,并不利于背后大模型对人类反馈的搜集。
So~
今后遇到AI生成回答有错误或遗漏时,
请不要吝惜一次点击,高举你手中的

或

,让大模型能收集更多的人类反馈。
就像读到这里,不要吝惜对这篇推文点赞、转发、在看一样!(doge)
- 狸谱App负责人一休:从“叫爸爸”小游戏到百万月活AI爆款,社交传播有这些底层逻辑丨中国AIGC产业峰会2025-04-23
- 心影随形创始人刘斌新:做不跟用户抢时间的AI产品丨中国AIGC产业峰会2025-04-22
- 直观即时绘制3D模型,可添加文本提示,VAST又开源了2025-04-21
- LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯2025-04-06