自主造芯新突破:256TOPS算力刷新国产性能榜,功耗低至35W,首个存算一体智驾芯片两年交卷
功耗却减少了超50%
金磊 发自 上海量子位 | 公众号 QbitAI
中国芯片,再添一股新势力——
国内首款存算一体智驾芯片,正式发布!

这款12nm芯片名叫鸿途™H30,从性能表现上来看,在功耗仅为35W的情况下,最高物理算力可达256TOPS。
概括来说,就是芯片性能提升了2倍以上,但功耗却减少了超50%。
这一点,以Resnet50性能功耗为例,与国际芯片巨头英伟达主流产品做对比即可一目了然。

不过有一说一,除了“国内首款存算一体智驾芯片”之外,围绕鸿途™H30所体现的“业界第一”还不仅于此。
它的问世也成为了存算一体大算力芯片在国内的首次工程化落地。
而打造鸿途™H30背后的公司后摩智能(下文简称后摩),其自身也拥有着一个“业界第一”的标签——
国内首家存算一体大算力AI芯片公司。
更重要的是,以上种种的成绩,后摩是从自2020年底成立至今,仅仅花费2年多的时间“解锁”。
如此速度和效能之下,也令活动现场掌声不断。

不只是一颗芯片这么简单
我们进一步再来深入了解一下这款存算一体架构芯片。
许多了解芯片的小伙伴在看到“256TOPS”时,就会产生疑问:市面上不是已经有很多能够达到这个算力值的芯片了吗?
我们需要注意的是,鸿途™H30亮出来的是物理算力,并非是市面上常说的稀疏虚拟算力。
这也就意味着它一举成为了国产智驾芯片里物理算力最大的那一个。
更难能可贵的是,在拿下最大算力的同时,功耗正如我们刚才提到的,仅为35W。
如此看下来,芯片的能效比便是几倍于同类的产品了。

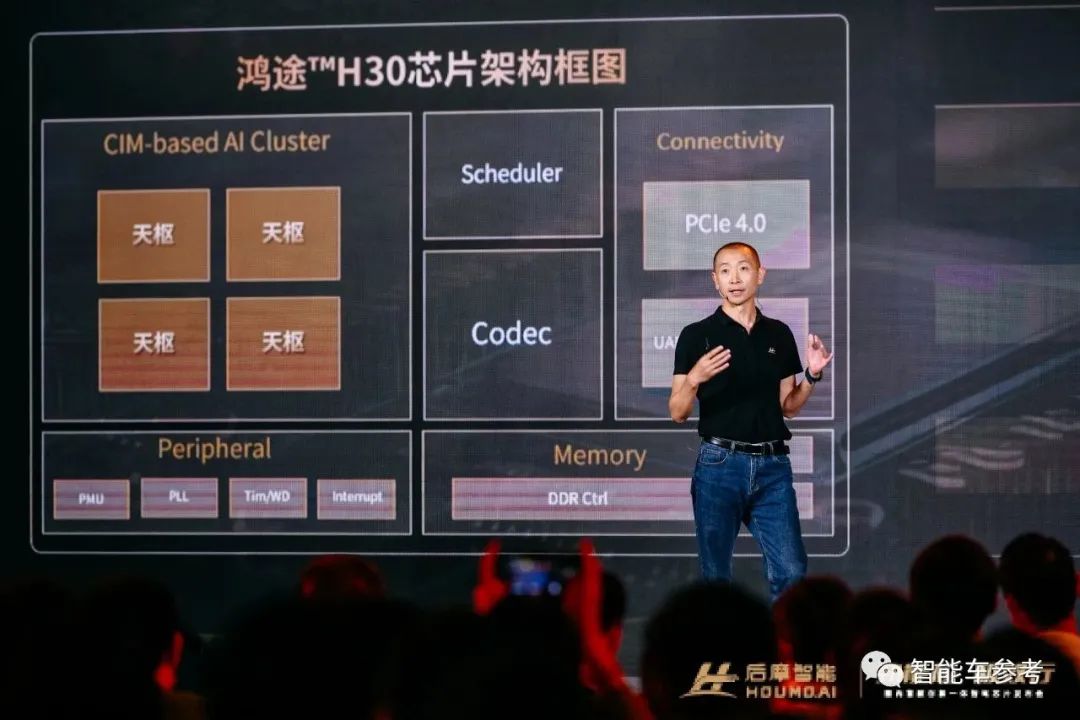
除此之外,在活动现场,后摩对鸿途™H30更多的细节参数做了展示:
- 12nm工艺
- 支持外扩Memory,宽带达128GB/s
- 支持16路FHD Encoder/Decoder
- 支持PCIe 4.0,x8,x4,x2,RC&EP mode
- ……

性能指标方面,鸿途™H30与英伟达产品相比,在Resnet50 Batch=1和Batch=8上,分别达到了5.7倍和2.3倍。

计算效率方面,鸿途™H30更是拿下了11.3倍和4.6倍的成绩!

那么具备如此高性能存算IP,如何能将其利用到位,便涉及到AI处理器架构和设计的问题了。
而在活动现场,后摩也是将其背后的架构设计毫无保留地展示了出来——IPU(Intelligence Processing Unit)。

从整体来看,后摩在架构设计上的规划采用了“三步走”的策略。
首先便是第一代IPU天枢架构,这是专门为自动驾驶所打造的IPU,而刚才我们提到的鸿途™H30正是基于此。
谈到这个架构是如何设计出来的,就不得不先提一下以往芯片的设计架构。
例如特斯拉FSD的集中式计算,就是非常典型的通过堆积大量计算资源来提高性能。
它就像是一个四合院,院子里啥都有,主人们在院子里可以尽情沟通交流,但问题也非常明显,就是四合院的面积就只有那么大,居住者数量就是有限的。
后来也有人提出了分布式计算的方法,把算力很大的核拆分成若干个小核;这些小核可以独立完成小任务,也可以共同完成大任务。
这种方式像是现代高层公寓,每层楼都有独立的基础生活功能,也可以方便复制和扩展;但问题是每层楼之间的沟通比较困难。

因此,后摩智能的天枢架构所采用的便是二合一的思路——结合古典中式建筑和现代高层建筑。
简单来说,每个芯片都包含4个IPU核;每个IPU核又有4个Tile;而每个Tile内部还有CPU、张量引擎、特殊功能单元、矢量处理器和多通道DMA等。
这样的架构使得AI计算不但不用在多个处理器(例如CPU,GPU,DSP)之间分配任务,甚至不用出AI核,就可以高效的完成全部端到端的计算。
这种架构还可以说是像一个综合办事大楼,走进去,一站式完成各种业务,大幅提高了效率。

总结来说,天枢架构的特点之一就是多核/多硬件线程实现计算效率与算力灵活扩展的平衡。
除此之外,它还可以摆脱系统总线的桎梏,其双环拓扑专用总线可以实现灵活的数据直传。
就像在多层空中四合院之间,建了个直接入户的电梯,可以快速做到传输。

至于后摩在未来要进一步研发的天璇架构和天玑架构,则将聚焦在扩大模型应用边界和通用人工智能。
在现场,后摩也展示了搭载鸿途™H30后无人小车上路的实测。

但如果你觉得后摩仅仅是拿出来了一块芯片,那就有点too simple了些。
在如此短促的研发时间里,它还一口气发布了力驭®域控制器和后摩大道™软件平台。
力驭是后摩面向智能驾驶市场的大算力域控制器产品,据悉,只需要搭载单颗鸿途™H30,便可以满足智能驾驶多种传感器、从L2到L4所有AI计算的需求。

最后,还有一个后摩大道™软件平台,是为鸿途™H30芯片产品开发的AI软件开发平台。
它的作用便是可以让客户在使用后摩存算一体架构产品时,能够将开发、调试和部署应用的效率大幅提高。
以上便是后摩第一次正式亮相所给出的主要“作业”了。
通过各种数据和效果的对比展示,其在大算力国产智驾芯片的实力可见一斑。
但更令人惊叹的,还应当属“后摩速度”——一切都在2年多时间完成。
如何在2年时间“炼”成的?
不同于美国创业公司从车库、大学宿舍开始的那般浪漫与理想,后摩的创业起点非常出乎人们的意料——沙县小吃。
没错,正是在这种享受馄饨与热汤之际,几个人一拍即合,决定创业搞AI芯片。
不过赛道锁定在芯片,除了大环境的因素之外,也与小伙伴们每个人都向往“万物智能”的生活相关。
例如有人家住得特别远,若是自动驾驶成熟了,便可以边通勤边办公;还有人非常顾家,希望有个机器人把家务全包了……
那么问题来了,到底什么样的芯片才能做到无处不在、让万物实现智能?
极致的效率,毋庸置疑是非常关键的因素之一。
然而当时后摩的初创团队从科技发展历史看清的一个事实是,每1000倍的效率提升将造就一个计算时代。

若是想要达到他们理想的万物智能世界,那么算力起码也得是现今芯片计算效能的1000倍。
加之摩尔定律的逐步失效,他们便将目光聚焦到了另一种打法——换架构,搞存算一体。
团队坚定认为,这就是后摩尔时代下的破局之道:
算力得大,功耗要低,面积要小,成本还得廉。
以至于CEO吴强在现场这般回忆道:
我们太喜欢这个方向了,连公司名字都是从这而来——后摩智能。
(虽然也有人会打电话问是不是做摩托车的……)
不过讲真,存算一体这个技术在两三年前并没有像现在这般火爆。
可以说后摩成为了最早一批尝到红利的公司,也顺理成章地使其成了国内第一个搞存算一体大算力AI芯片的公司。
而之所以会将第一个落地场景放到自动驾驶,用吴强的话来说就是,“自动驾驶是万物智能美好生活的重要组成部分,人们几乎在花1/8清醒时间在开车”。
并且自动驾驶作为“集AI技术大成者”的领域,能啃下这块硬骨头,那么再拓展到其它领域也就会轻松很多。
赛道、方向、技术,在创业初期三大最重要的关键因素定下来之后,接下来就是进入更煎熬的研发阶段了。
虽说是煎熬阶段,但有一说一,对于后摩团队来说,或许都已经是驾轻就熟的事情,因为公司聚集了一帮芯片“老手”。
例如创始人吴强,博士毕业于普林斯顿大学计算机博士学位,研究方向正是高能效比计算芯片及编译器。
毕业之后,他还先后工作于Intel、AMD、Facebook等国外知名企业;值得一提的是,在AMD期间曾担任GPGPU/OpenCL创始团队核心成员。
吴强不仅拥有国外的工作经验,在2017年回国之后,也是在国内AI知名独角兽企业担任技术副总裁和CTO等职务。
在学术方面,吴强曾获第38届计算机体系架构顶会MICRO-38 唯一的一个最佳论文奖;科研成果被美国业内杂志IEEE Micro 评选为年度最有影响的12 个科技成果之一。
 △后摩智能创始人兼CEO,吴强
△后摩智能创始人兼CEO,吴强
再如后摩智能联合创始人、芯片研发副总裁陈亮,本硕博毕业于清华大学,曾任海思CPU芯片资深架构师、地平线AI芯片首席架构师。
在做产品上,后摩联合创始人、产品副总裁信晓旭,具有15年以上计算芯片产品、市场和销售经验,曾任海思计算芯片产品总监。
 △左:陈亮;右:信晓旭
△左:陈亮;右:信晓旭
而从后摩整体研发团队构成来看,硕、博士占比70%以上;核心成员均主导过多颗世界级芯片的设计量产,类别涵盖GPU、CPU、高性能车规级AI芯片等。
更重要的是,用吴强自己的话来说,后摩的研发团队人员都是非常纯粹的人,肯吃苦、够努力。
如此来看,也就不难理解为什么能够在2年多的时间里,将存算一体芯片从0到1开花结果了。
芯片的“后摩时刻”已至
虽然芯片产品已经发布、量产,但最后我们还需要对一个问题做深入的探讨——存算一体,是否真的是正确的方向。
要回答这个问题,我们还需先得知道芯片算力的发展出了什么问题。
无论是计算机、手机,还是智能手环等产品,它们内部程序运行机制都绕不开一个著名的计算体系,冯·诺依曼体系结构。

它的一个特点,就是计算和存储是分离的。
若是通俗一点理解,我们可以将这个过程视为在厨房炒菜:
- 存储器:相当于厨房里的冰箱;
- 数据:相当于冰箱里的菜;
- 计算器:相当于洗菜、切菜和炒菜。
那么要完成一道菜,就需要先从冰箱里把菜取出来,再去厨房里洗、切、炒。

那么问题来了,这些菜需要在存储器和计算器之间疯狂地做搬运工作,这就无形之间产生了巨大的时间开销,
若是对于较低的计算量来说,冯·诺依曼体系结构尚且还可处理,但谁能想到,在信息数据量爆炸的当下,人们对算力的需求会变得如此之大。
举个例子,若是用全卷积网络处理一张分辨率为224×224大约5万像素的图片,需要的计算量为5×109次的计算。
这个任务若是放在一个CPU核心上处理,需要足足3秒钟的时间,慢,着实太慢!
单单是这么简单的任务尚是如此,近年来随着AIGC热潮的到来,大模型成为了产学界的香饽饽,而动辄需要对上千亿参数做训练推理,需要的算力之大可见一斑。
即便现代很多芯片开始设计更复杂的多级存储结构,例如把SRAM(静态随机存储器)作为距离计算单元最近的缓存,保证最高的读写速度,但容量还是非常的有限。
例如在下图英伟达GA102 GPU中,蓝色方块区域便是缓存区域,即便看上去占了不少空间,但其实容量也就6MB而已。
这在当今主流AI任务面前,简直是大巫见小巫了。

这,就是当下算力发展所遇到的致命瓶颈。
而且就过去二十年的发展来看,处理器性能以每年大约55%的速度提升,但内存性能的提升速度每年只有10%左右。
存储速度长期滞后于计算速度,因此就导致了芯片性能难以满足AI需求的情况。
不仅如此,近年来“摩尔定律即将失效”的声音也是此起彼伏,很多人认为传统的芯片无法再胜任新的大算力任务了。
虽然业界在后来提出了GPU、多核CPU等解决方案,但依旧是无法绕开冯·诺依曼体系结构最为致命的瓶颈问题。
在如此情况之下,业界便提出了更为大胆的想法——干脆把冰箱和厨房搞到一起,让取菜、洗菜、切菜和炒菜都在一个空间里完成——即,存算一体。

对应到芯片设计,就意味着把分开的计算单元和SRAM单元重新设计,把乘加单元打散并插入到SRAM阵列当中,以此形成新的存算单元。
如此一来,每个存算单元既保留了SRAM本身的规则性,便于高速读写;又扩充了并行计算功能,实现高能效计算。

以后摩发布的鸿途™H30为例,在存算一体架构之下,便可以在每秒计算超过4×1012次。

和其它AI芯片相比,后摩存算一体的宏单元在同样能耗下提供的算力,可以直接飙升10倍!

但其实存算一体技术早在2011年就引起学术界关注,而后在2016-2017年成为学术界热议的话题。
到2019年逐渐开始受到工业界和资本的关注,彼时大家的讨论主要集中在这项技术的可靠性上。
从2020年开始,越来越多的玩家进入这个市场,并且大公司都开始在存内计算上发力,此时的存内计算已成为产业界“不得不跟进”的技术之一,大家的讨论聚焦在存内计算未来的市场空间上。
再从市场规模角度来看,量子位在《存算一体芯片深度产业报告》中曾经预测:
2030年,基于存算一体技术的大算力芯片市场规模约为67亿人民币。
由此可见,不论是从技术亦或是市场的发展和预测来看,存算一体确实是解决算力瓶颈的一大利器。
而作为率先入局的后摩智能,也给出了自己的观点:
存算一体的价值在于,它是一种比传统架构更接近人脑的计算方式,能达到远超传统方式的高计算效率,和智能驾驶终局的需求天然吻合。
2023年,会是存算一体商业落地的元年。
至此,对于芯片算力的瓶颈,后摩智能已经给出了自己的一套打法,并且已经交出了一份高分作业。
站在现今后摩尔时代的当下,或许芯片的“后摩时刻”已经到来。
- 阶跃星辰推出开源 SOTA 图像编辑模型,一个月连发三款多模态模型2025-04-27
- 清华系智谱×生数达成战略合作,专注大模型联合创新2025-04-27
- 夸克AI超级框上新“拍照问夸克” 加码多模态能力2025-04-27
- 一季度超百万辆!比亚迪凭实力书写行业 “霸榜” 传奇2025-04-27