
智谱AI CEO张鹏:ChatGLM全球超过百万下载,为行业智能化降本增效|中国AIGC产业峰会
大模型三大挑战
丰色 整理自 凹非寺
量子位 | 公众号 QbitAI
眼下,“预训练大模型是AIGC时代的基座”这一观点已成业界共识。
但训练一个千亿参数规模的大模型,还面临很多挑战。
在中国AIGC产业峰会现场,智谱AI CEO张鹏就指出,在这方面我们至少面临三大挑战:
一是成本,如一个1750亿参数的GPT-3就烧掉了1200万美元(约合人民币8300万元);
二是人力,一个谷歌PaLM-530B的作者列表就有近70人,而我国大模型人才还很欠缺;
三是算法,千亿大模型训练过程极其不稳定,一旦出现意外,成本和风险都将额外增加,性能也无法得到保障。
因此,张鹏认为:我们应该多给国产从业者多一点耐心。

张鹏,毕业于清华大学计算机科学与技术系,现在是北京智谱华章科技有限公司(简称智谱AI)的CEO,公司成立于2019年,从那个时候,张鹏就带领公司瞄向“让机器像人一样思考”的愿景奋斗。几年来,公司连续发布了GLM系列大模型、ChatGLM、CodeGeeX代码大模型等,已经成为国内最早也是最有大模型研发经验的企业之一。
在本次大会上,除了关于预训练大模型本身的思考,张鹏介绍了智谱AI在该领域的最新研发和落地进展,包括:
(1)可与GPT-3基座模型对标的GLM-130B
(2)只用单个GPU就能跑起来的ChatGLM-6B,全球下载量超过100万
(3)每天帮助程序员“编写”超过400万行代码的辅助编程工具CodeGeeX等
为了完整再现这些精彩内容,在不改变原意的基础上,量子位对其演讲进行了编辑整理。
中国AIGC产业峰会是由量子位主办的行业峰会,近20位产业代表与会讨论。线下参与观众600+,线上收看观众近 300万,得到了包括CCTV2、BTV等在内的数十家媒体的广泛报道关注。
演讲要点:
- 预训练大模型是新一代人工智能应用的基础设施。
- 训练高精度千亿中英双语稠密模型,对大模型研究和应用有重大意义。
- 训练千亿大模型的成本高昂,比如1750亿参数的GPT-3总成本就达1200万美元。
- 常见的千亿级模型训练数据量巨大,训练周期又很长,在这之中不可避免会有各种各样的意外发生。所有这些意外都会带来额外的成本和风险,以及不可预测的模型性能下降。
- 开源对话模型ChatGLM-6B仅仅62亿参数,可以在单个GPU上运行起来,意味着稍微好一点的笔记本带的显卡就可以。
- 大模型的智能涌现仍未看到极限……
- 对于目前的GPT-4,人类至少在考试上已经考不过它了。
以下为张鹏演讲全文:
预训练大模型是AIGC时代的基座
AIGC时代的基座到底是什么?
我相信所有人肯定会说是预训练大模型。
所谓基座即基础设施,为什么它能够成为基础设施?
有两点原因。
第一,这样的大模型能够提供非常强大的通用泛化能力,可完成多场景任务,降低成本、提高效率,这是非常关键的特性。
第二,模型本身的规模达到一定程度之后,就能允许我们在当中融入更多的知识,包括跨模态的知识,使得模型能够更好地模拟人的智能。
因此,相关的工作在过去几年已经成为整个行业的研究热点,包括ChatGPT、SD(stable diffusion)等模型所带来的生成能力,正是由于这样的大模型的诞生所衍生出来的。

在这个过程中我们持续跟踪技术前沿,也做了一些相关的工作,后面我们逐渐展开。
如今我们欣喜地观察到,大模型能力正在涌现。
为什么量变会引起智能上的质变?
过去几年中,大家谈大模型的摩尔定律,单模型参数量每年增长十倍甚至百倍。
现在,智能涌现程度也呈现摩尔定律,甚至以更高速度发展。
在这其中,训练高精度千亿中英双语稠密模型,对大模型研究和应用有重大意义。

我们可以看到,过去三四年中,有很多人来做相关的探索和研究。
不光是国外,我们国内有很多企业、很多研究团体也做了相关工作,每一个成功都是今天我们看到的成果的基石,一块块砖拼接成最终的基座。
ChatGPT让大家觉得非常惊喜,实际上从基座GPT-3开始到现在经历两年半时间,其中很多工作都是在发掘和诱导基座模型的智能能力。
比如SFT、RLHF等方法都是在诱发基座模型的能力,这些智能能力已经存在于千亿基座模型当中。
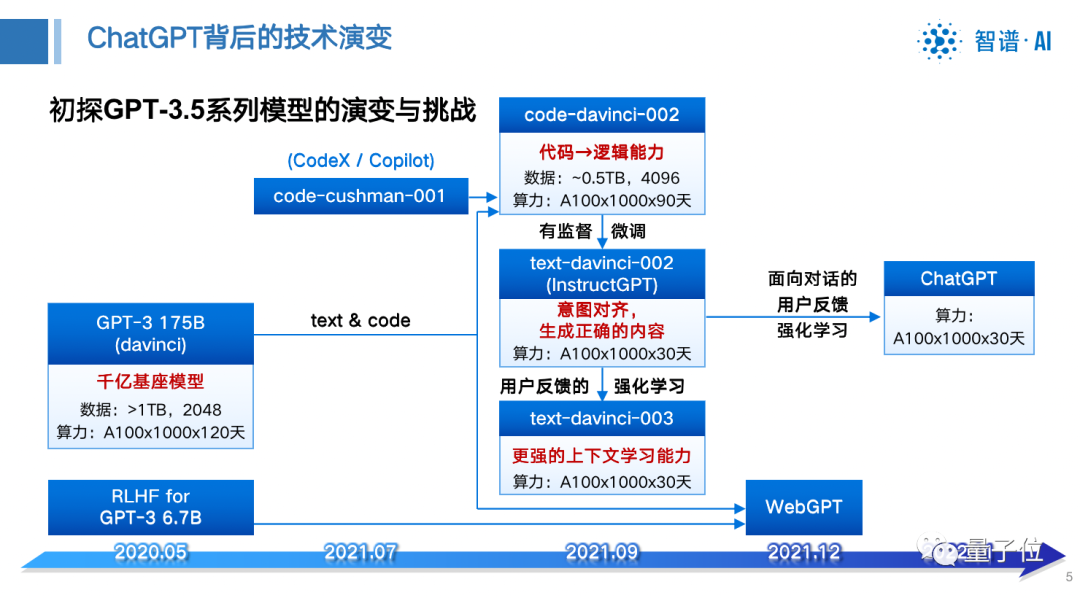
那么,训练千亿模型面临的挑战有哪些?
训练千亿大模型的三大挑战
第一是训练成本高昂。
比如训练1750亿参数的GPT-3,用到了上万块V100,机时费用是460万美元,总成本可达1200万美元。
第二是人力投入极大。
像谷歌PaLM 530B团队,前期准备29人,训练过程11人,整个作者列表68人,但我国能做大模型的人才不足百人。
光是组建这样一个知识密集型团队还不够,还需要成员之间非常紧密的合作。
第三是训练过程不稳定。
常见的千亿级模型训练数据量巨大,训练周期又很长,在这之中不可避免会有各种各样的意外发生。
所有这些意外都会带来额外的成本和风险,以及不可预测的模型性能下降。

所以这方面我们也在一直努力和清华大学联合研究,也提出了自己的一些创新,通过融合GPT和BERT两种训练框架解决训练模型问题。
去年8月份,我们开源了1300亿参数规模的双语预训练模型GLM-130B。
它不仅英文不输GPT-3,中文也超出同类模型。
与此同时,模型精度也提高了,还能够通过量化压缩加速等在低成本情况下跑起来。
大家知道训练大模型很贵,如何让大家用较低的成本用起来,也是我们作为商业化公司来讲要考虑的问题。
经过我们的努力,不仅能够让运行成本降低75%,同时也会不损失任何的精度和推理的速度,最后还能适配国产化硬件,给大家提供更好的选择。
所以这个开源项目受到全球关注,很多科研机构、大学都来申请使用我们模型进行评测。

2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B是亚洲唯一入选的大模型。
在与OpenAI、谷歌大脑、微软、英伟达、脸书的各大模型对比中,评测报告显示GLM-130B在准确性和公平性指标上与GPT-3 175B (davinci) 接近或持平,鲁棒性、校准误差和无偏性优于GPT-3 175B。

GLM-130B是去年8月份的开源项目,9月份我们也开源了另外的项目——CodeGeeX。
我们专门针对开发者去设计了这样一款大模型,提供相应的服务,他们可以利用这个模型来写代码,提高他们的生产效率。
CodeGeeX每天线上帮助程序员用户提供超过400万行代码的生成量,大家可以算算相当于多少程序员的工作量。

就在今年3月份的时候,我们终于把GLM-130B升级到了我们自己的聊天对话模型ChatGLM。
这个模型已完成第一阶段快速的内测,有将近5000人的规模参与,引起很多关注。
在人类指令的意图理解这方面它表现不错,它会比较坚持地认为它是一个AI机器人或者是某种人格的智能体,不会被用户随便混淆。
为了让更多人加入到大模型体验中来,我们把小一点规模的ChatGLM-6B,就是62亿规模的模型进行了开源。
这个项目4天就获得了6K star,昨天已经超过2万star,这是我们发布的开源项目中star数增长速度最快的。

△ 截至4月30日的热度
这个项目为什么引起大家的热捧?
因为模型规模仅仅62亿参数,可以在单独一张GPU上就可以运行起来,也就意味着稍微好一点的笔记本带的显卡就可以把它跑起来。
甚至有人还在网络平台直播怎么玩这个模型,怎么跑这个模型,非常有意思。
业界也做了评测,与GPT-3.5、GPT-4平行评测,包括关于安全性方面测,结果发现ChatGLM模型稳定性不错,安全性也还行。
大模型的智能涌现仍未看到极限
基于以上模型,我们提供商业化的服务方式,我们称之为Model as a Service(MaaS)。
它有多种服务方式,包括端到端的模型训练服务,从开始训练到最后应用的开发和集成都囊括。也可以像OpenAI一样,提供API调用服务,也可以把模型以商业应用的方式提供给大家来进行使用,最后还能帮助大家去开发一些创新的应用。

在这样的理念下,我们提供BigModel.ai的开放平台,上面有解决方案、产品、好玩的demo、生成内容、API请求入口,大家可以了解一下。
具体介绍几个产品。
在座有没有程序员?
程序员非常喜欢这样的工具(CodeGeeX),提升大家的工作效率,而且这个工具是免费的,所以大家尽管去试,尽管去用。
其次,文字工作者们也可以用这样的辅助写作工具(写作蛙),完成营销文案、社交媒体内容,或者做细分场景划分,比如可以用他来写一封给我孩子的信,让他带到学校去,在老师同学们面前念出来,我觉得写得比我自己写的好。

在聊天的场景下(小呆)我们也可以让它去扮演某一种角色每天跟你聊一会儿,安慰你的心灵,或者你喜欢一个可爱的女朋友,你可以设定一下跟你聊一聊。

商业落地方面,如美团电商平台,用我们大模型提升广告推广以及提高客户服务场景下的任务的性能;世界杯期间我们也服务了特殊的人群——听障人士,用手语方式现场实时直播,关爱听障人士。
未来,大模型能帮大家做很多事情,包括工作、生活甚至创新范式,大模型的快速进步给实现通用人工智能(AGI)带来了曙光。让我们一起多一些期待,多一点耐心,一起拥抱这个伟大的AI时代,谢谢大家。
- 人人可用的超级智能体!100+MCP工具随便选,爬虫小红书效果惊艳2025-04-29
- 当购物用上大模型!阿里妈妈首发世界知识大模型,破解推荐难题2025-05-01
- OceanBase全员信:全面拥抱AI,打造AI时代的数据底座2025-04-27
- 网易有道张艺:AI教育的规模化落地,以C端应用反推大模型发展2025-04-27










